题目描述 S S S k k k S S S k k k [ 1 , 2 , 1 ] [1, 2, 1] [ 1 , 2 , 1 ] 1 1 1 0 0 0 2 2 2 3 3 3
给定一个长度为 n n n a 1 , a 2 , … , a n a_1, a_2, \ldots, a_n a 1 , a 2 , … , a n b 1 , b 2 , … , b n b_1, b_2, \ldots, b_n b 1 , b 2 , … , b n 0 ≤ b i ≤ 1 0 9 0 \le b_i \le 10^9 0 ≤ b i ≤ 1 0 9 1 ≤ i ≤ n 1 \le i \le n 1 ≤ i ≤ n [ b 1 , … , b i ] [b_1, \ldots, b_i] [ b 1 , … , b i ] ( n − i + 1 ) (n-i+1) ( n − i + 1 ) a i a_i a i
如果存在这样的数组,请构造并输出任意一个满足条件的数组 b b b
输入格式 t t t 1 ≤ t ≤ 1 0 4 1 \le t \le 10^4 1 ≤ t ≤ 1 0 4 n n n 1 ≤ n ≤ 2 ⋅ 1 0 5 1 \le n \le 2 \cdot 10^5 1 ≤ n ≤ 2 ⋅ 1 0 5 a a a n n n a 1 , a 2 , … , a n a_1, a_2, \ldots, a_n a 1 , a 2 , … , a n 0 ≤ a i ≤ 1 0 9 0 \le a_i \le 10^9 0 ≤ a i ≤ 1 0 9 n n n 2 ⋅ 1 0 5 2 \cdot 10^5 2 ⋅ 1 0 5
输出格式 b b b YES(不区分大小写),第二行输出 n n n b 1 , b 2 , … , b n b_1, b_2, \ldots, b_n b 1 , b 2 , … , b n 0 ≤ b i ≤ 1 0 9 0 \le b_i \le 10^9 0 ≤ b i ≤ 1 0 9 NO。
样例数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Input: 6 3 3 3 1 3 2 1 3 1 0 1 2 4 7 5 2 2 6 6 6 6 4 3 3 Output: YES 2 0 2 NO YES 67 NO NO YES 5 2 1 5 2 0
样例解释 a = [ 3 , 3 , 1 ] a = [3, 3, 1] a = [ 3 , 3 , 1 ] b = [ 2 , 0 , 2 ] b = [2, 0, 2] b = [ 2 , 0 , 2 ]
当 i = 1 i=1 i = 1 [ b 1 ] = [ 2 ] [b_1] = [2] [ b 1 ] = [ 2 ] ( 3 − 1 + 1 ) (3-1+1) ( 3 − 1 + 1 ) 3 3 3 0 , 1 , 3 , 4 , … 0, 1, 3, 4, \dots 0 , 1 , 3 , 4 , … 3 3 3 3 3 3 a 1 a_1 a 1
当 i = 2 i=2 i = 2 [ b 1 , b 2 ] = [ 2 , 0 ] [b_1, b_2] = [2, 0] [ b 1 , b 2 ] = [ 2 , 0 ] ( 3 − 2 + 1 ) (3-2+1) ( 3 − 2 + 1 ) 2 2 2 1 , 3 , 4 , … 1, 3, 4, \dots 1 , 3 , 4 , … 2 2 2 3 3 3 a 2 a_2 a 2
当 i = 3 i=3 i = 3 [ b 1 , b 2 , b 3 ] = [ 2 , 0 , 2 ] [b_1, b_2, b_3] = [2, 0, 2] [ b 1 , b 2 , b 3 ] = [ 2 , 0 , 2 ] ( 3 − 3 + 1 ) (3-3+1) ( 3 − 3 + 1 ) 1 1 1 1 , 3 , 4 , … 1, 3, 4, \dots 1 , 3 , 4 , … 1 1 1 1 1 1 a 3 a_3 a 3
在第二组测试用例中,a = [ 2 , 1 , 3 ] a = [2, 1, 3] a = [ 2 , 1 , 3 ] b b b NO。
在第三组测试用例中,a = [ 0 ] a = [0] a = [ 0 ] b = [ 67 ] b = [67] b = [ 6 7 ] [ b 1 ] = [ 67 ] [b_1] = [67] [ b 1 ] = [ 6 7 ] 1 1 1 0 0 0 a 1 a_1 a 1
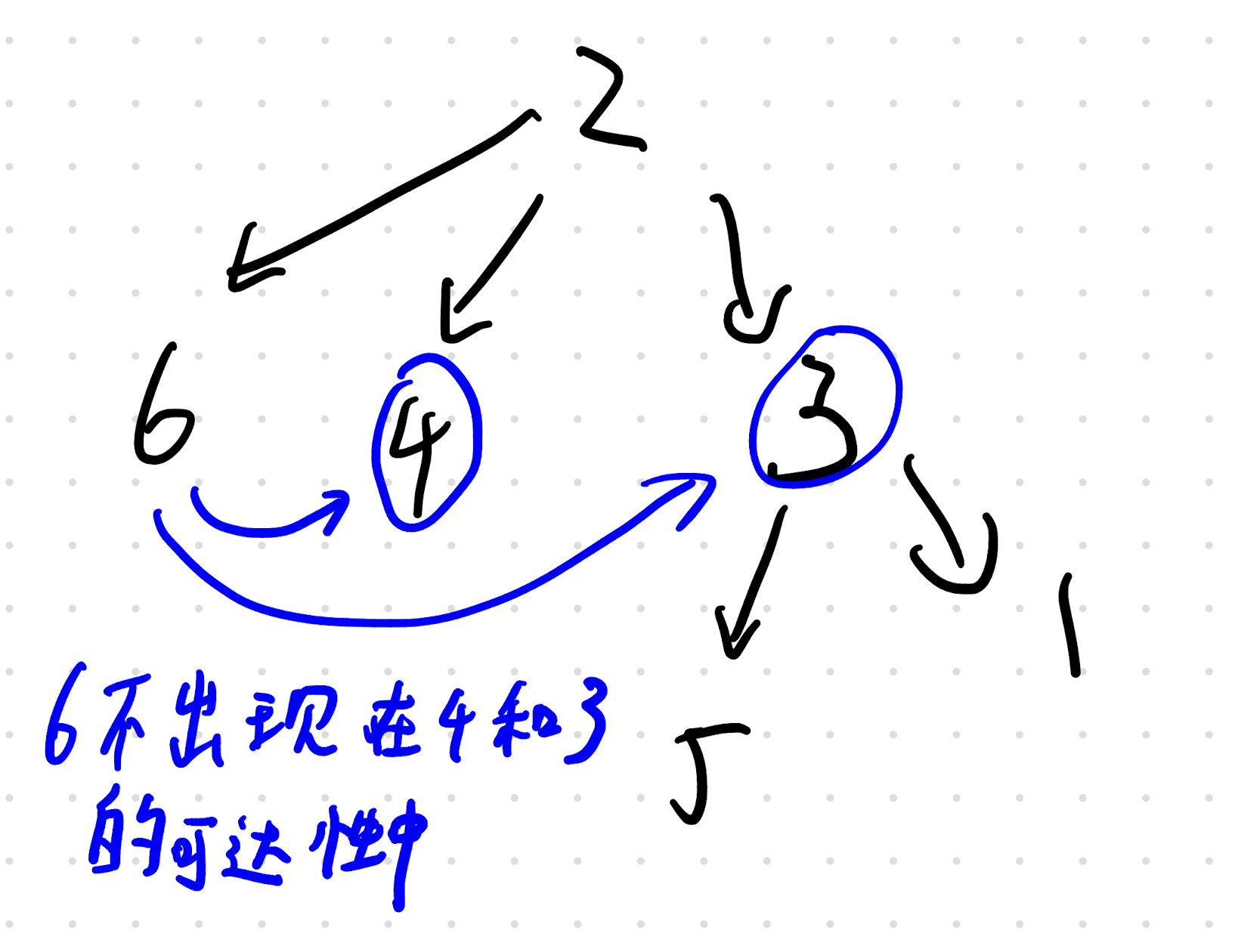
如何解决这道题目的难点,即所谓的后效性,构造前面的可能影响后面的
b_i 会不会把未来某个 a_j 自己的位置占掉”的浅层冲突,因为你认为这个很简单、不是难点。a_j 要想合法,依赖于前面若干步对 b 的构造结果(也就是前面是否保留了足够且合适的缺失结构、是否在合适区间内消耗了哪些值)。你这个“更深耦合”说得对,真正难点是这个,不是“占坑”。
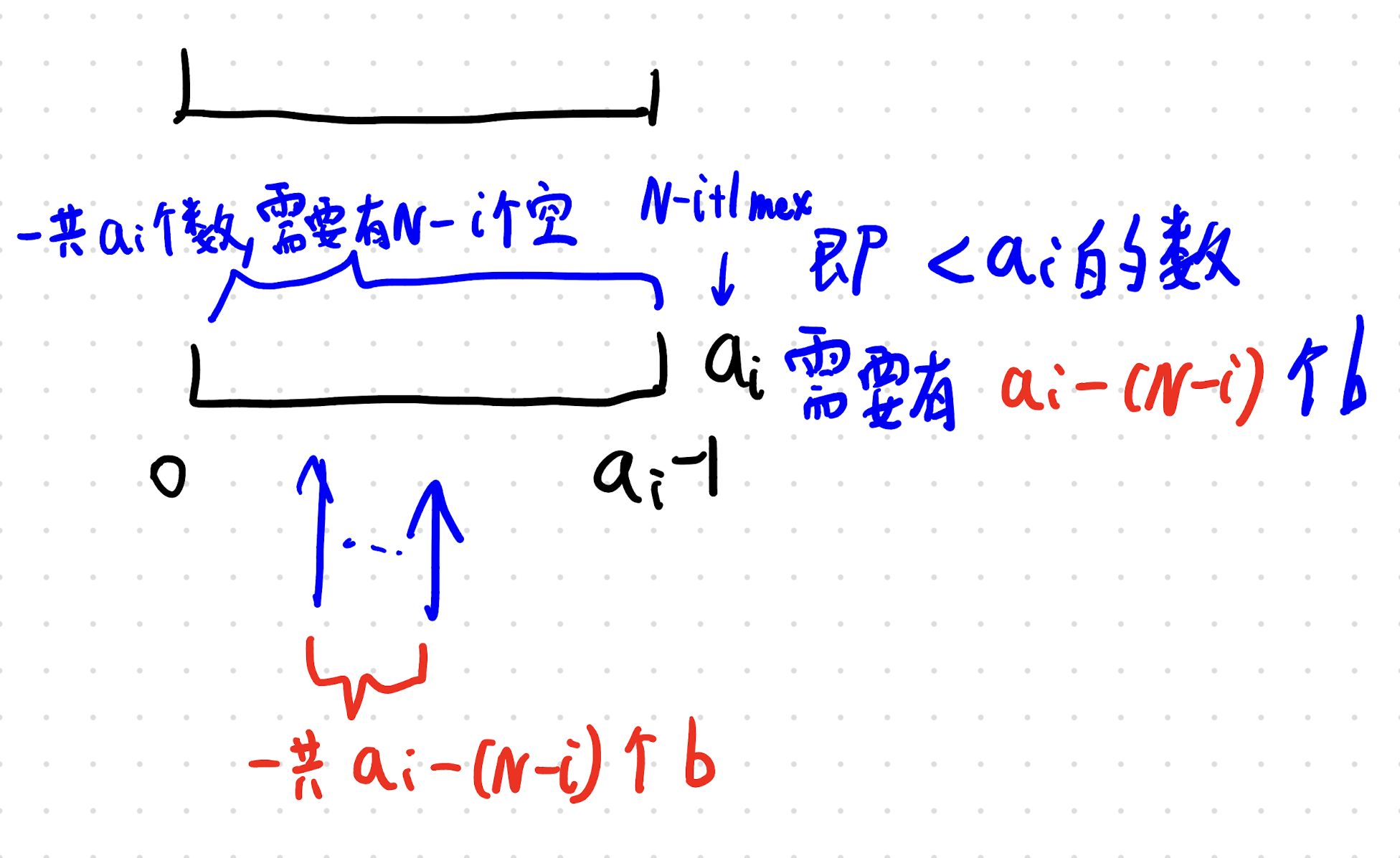
设 used(<x) 表示当前前缀里,0..x-1 中已经被你“用掉(出现过)”的不同值个数。
那么 missing(<x) = x - used(<x)。
题目在第 i 步其实要求的是missing(<a_i) = n-i,等价于used(<a_i) = a_i-(n-i)。v 放进 b_i,会让 used(<x) 对所有 x>v 都 +1。a_i。
怎么解这个后效性?
每次当你发现当前 used(<a_i) 还差 1,你就必须 消耗一个 <a_i 的资源值。
这个资源值选小了,会影响更多未来阈值;选大了,只影响较大的阈值。
所以为了给未来留最大余地,策略是:在所有可选的 <a_i资源里,选最大的那个。
选更小的 v 会额外改动一批中小阈值(v < x <= v' 这段);
选更大的 v' 不会多改任何阈值,改动范围更窄;
所以“选最大可行值”始终更保守,未来选择空间更大。
你可以把整题理解成两类约束同时满足:
硬约束 :当前步 used(<a_i) 必须达到目标值。耦合控制 :当必须加 1 时,把这 +1 尽量放在“最高位置”上,减少对小阈值链条的污染。
一句话总结你问的点:b_i 对多阈值前缀计数的联动”,而破解方式是“把每次必做增量放到最大可行值上”,把全局耦合压成局部可维护贪心。
首先,需要这样子想,每一个 a 代表什么?可以这样子想:
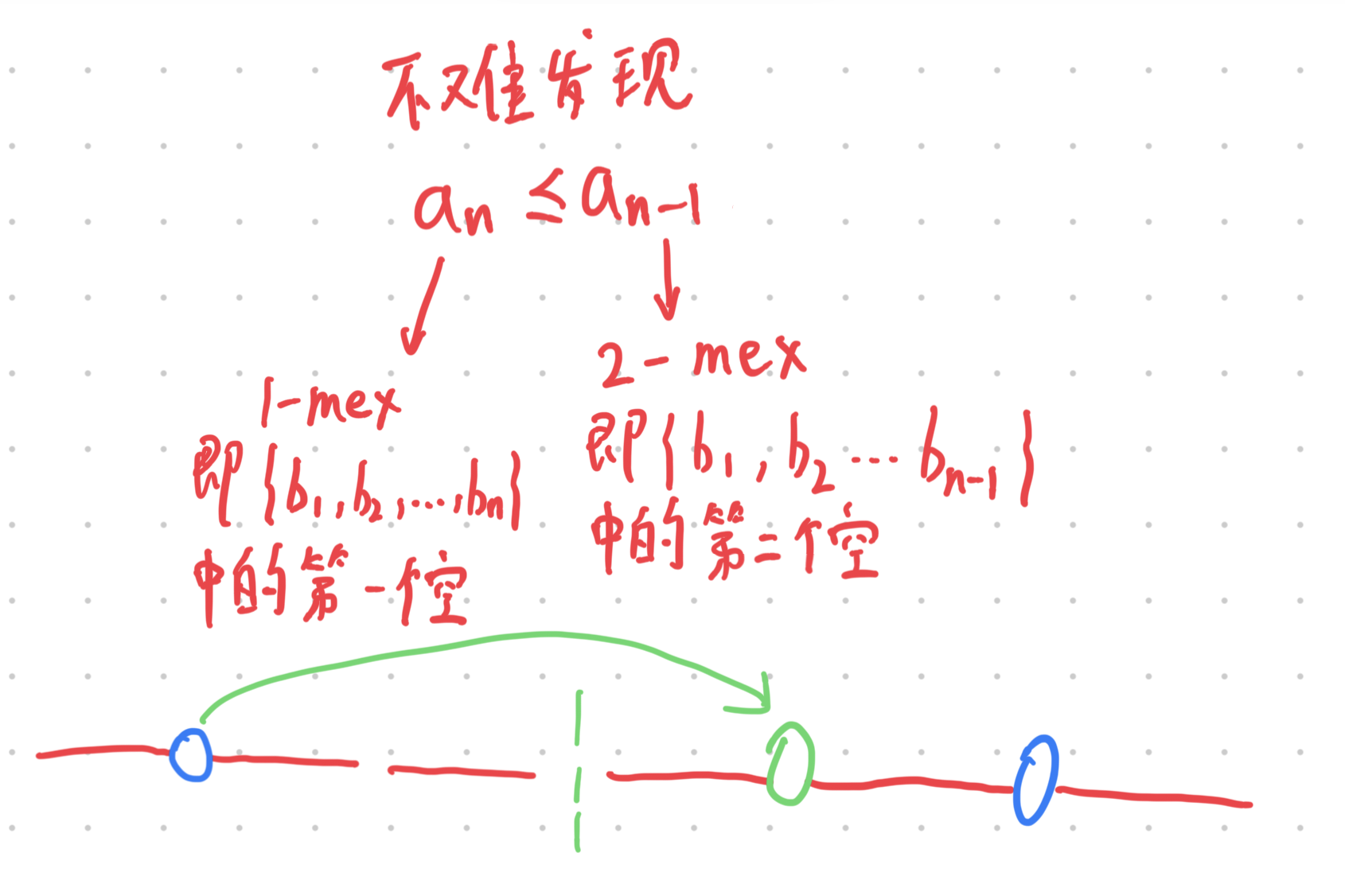
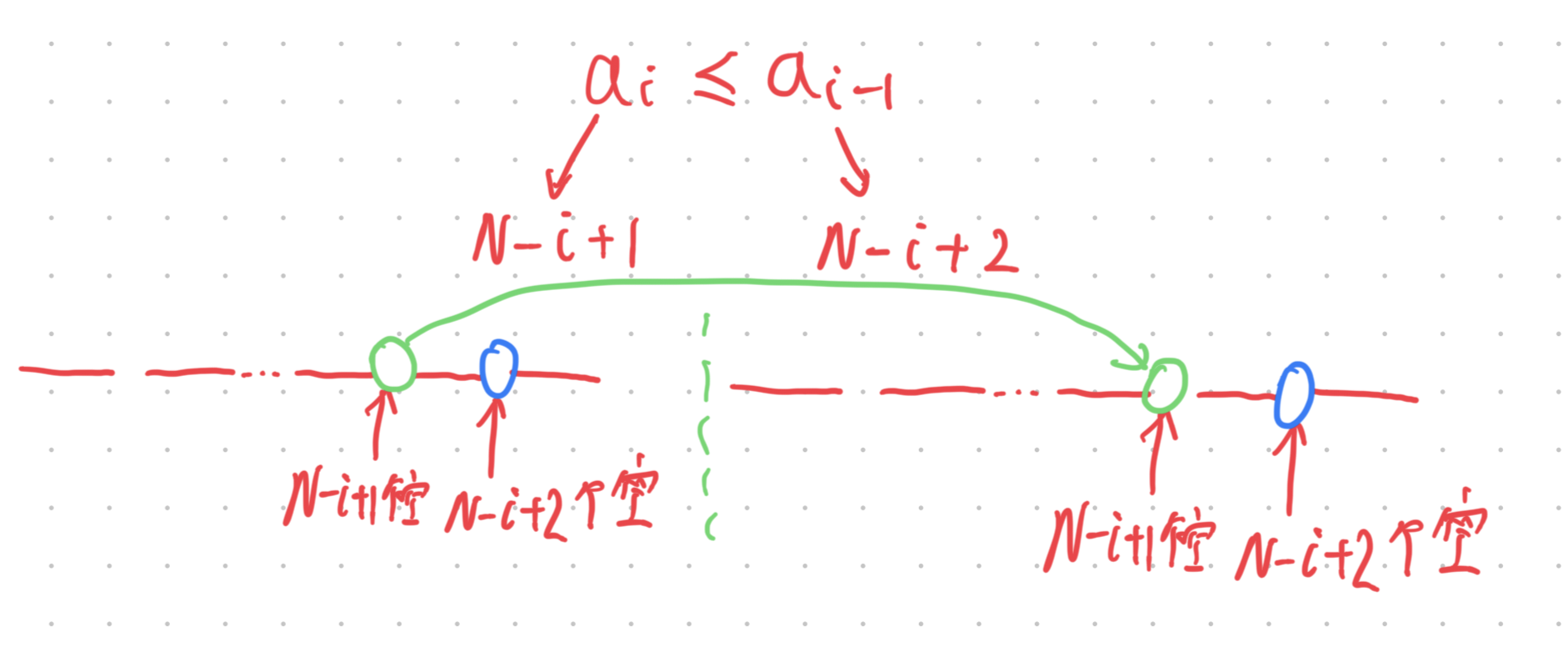
不难发现:(使用归纳法)
当然,我们可以换成这个 i。
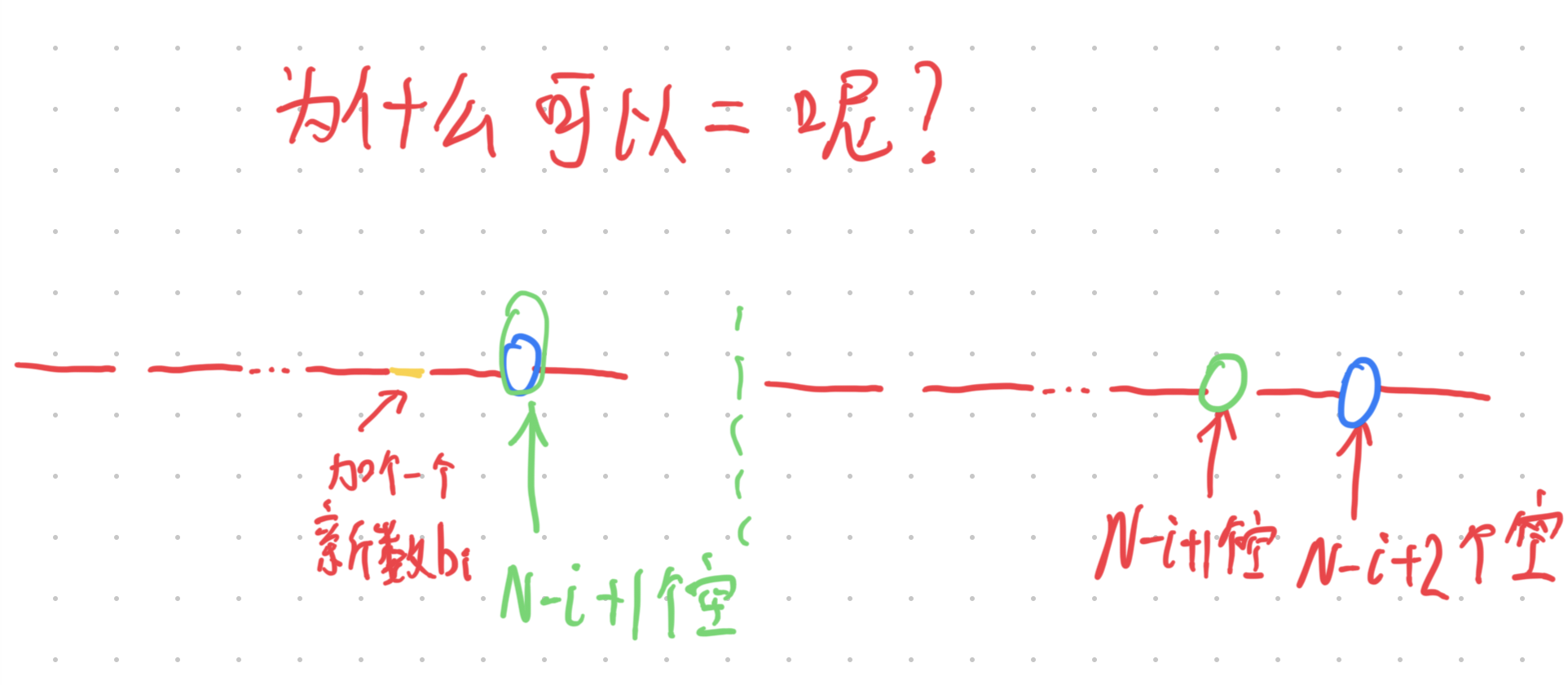
为什么可以 = 呢?
其实这个规律还是没有那么难以观察出来的,毕竟这个 a1 代表第 n 个空,a2 代表第 n-1 个空,你也很难想象第 n-1 个空在第 n 个空后面是吧 ?
AI 使用这个 EDF(Earliest deadline first scheduling) 调度,即我们都学过的,选择结束时间最靠前的这个任务,想出了这道题目的解法
好,我前面的论证确实有问题——“影响范围小所以更安全"本质上是在循环论证,没说清楚"为什么更安全”。换一个角度重新讲。v v v a a a a a a ≤ v \le v ≤ v v v v v < a j v < a_j v < a j v v v 快过期的你现在不用,以后就用不了了;晚过期的你现在不用,以后还能用。 所以先用快过期的不会错过任何机会,反过来先用晚过期的可能让快过期的白白浪费。a a a a a a a a a
我觉得上面 AI 的这个角度还是挺好的,但是我其实觉得稍微有点扯。
然后我们还是没有想到怎么做?那应该是对 a 的性质探索的还不够多!(继续沿着探索 a 的性质的这条路走)
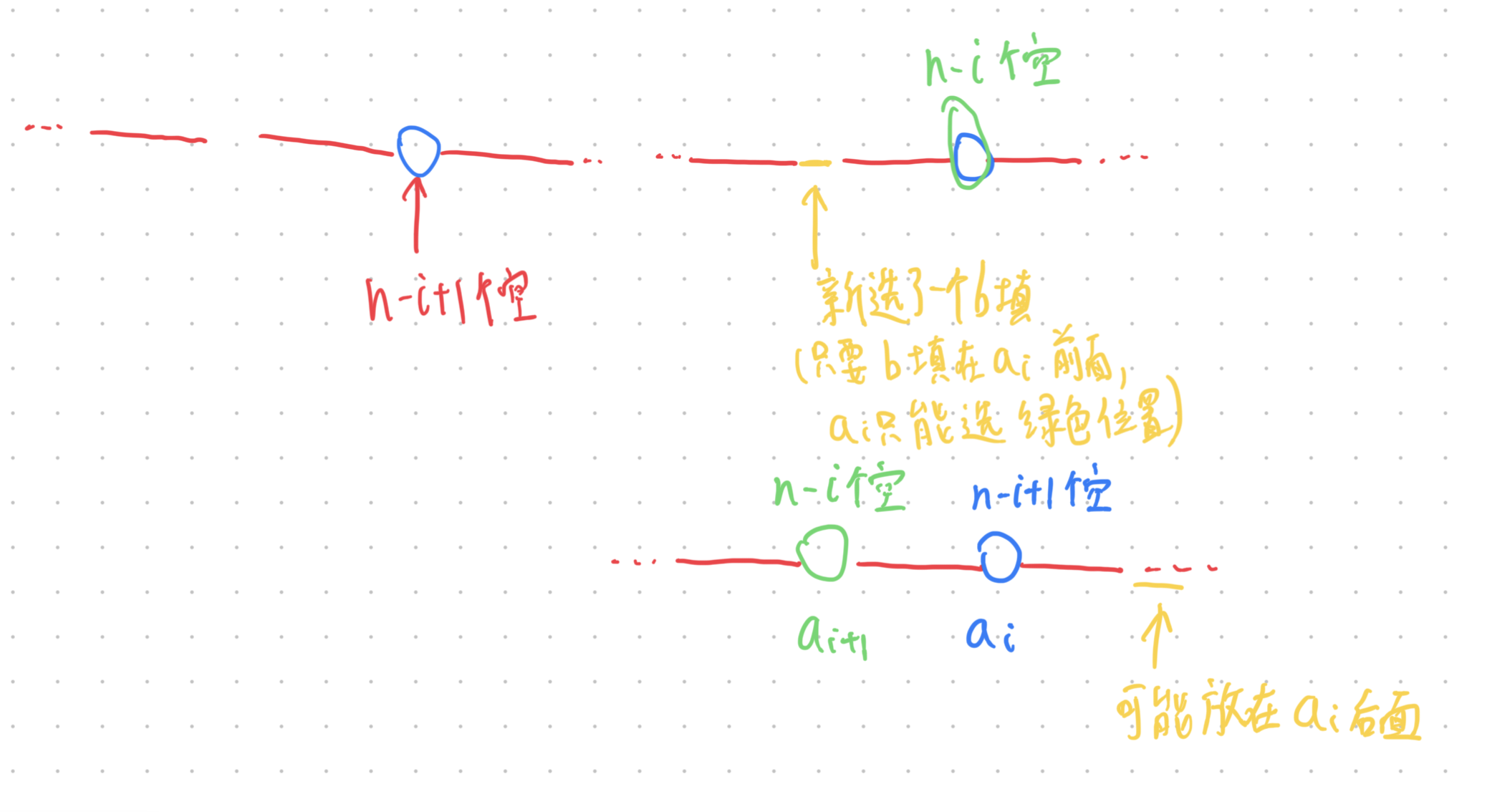
其实光有这个递减性质,其实还是不够的,我们不妨多探索一些性质,比如说 ai+1 其取值范围到底是在哪里?
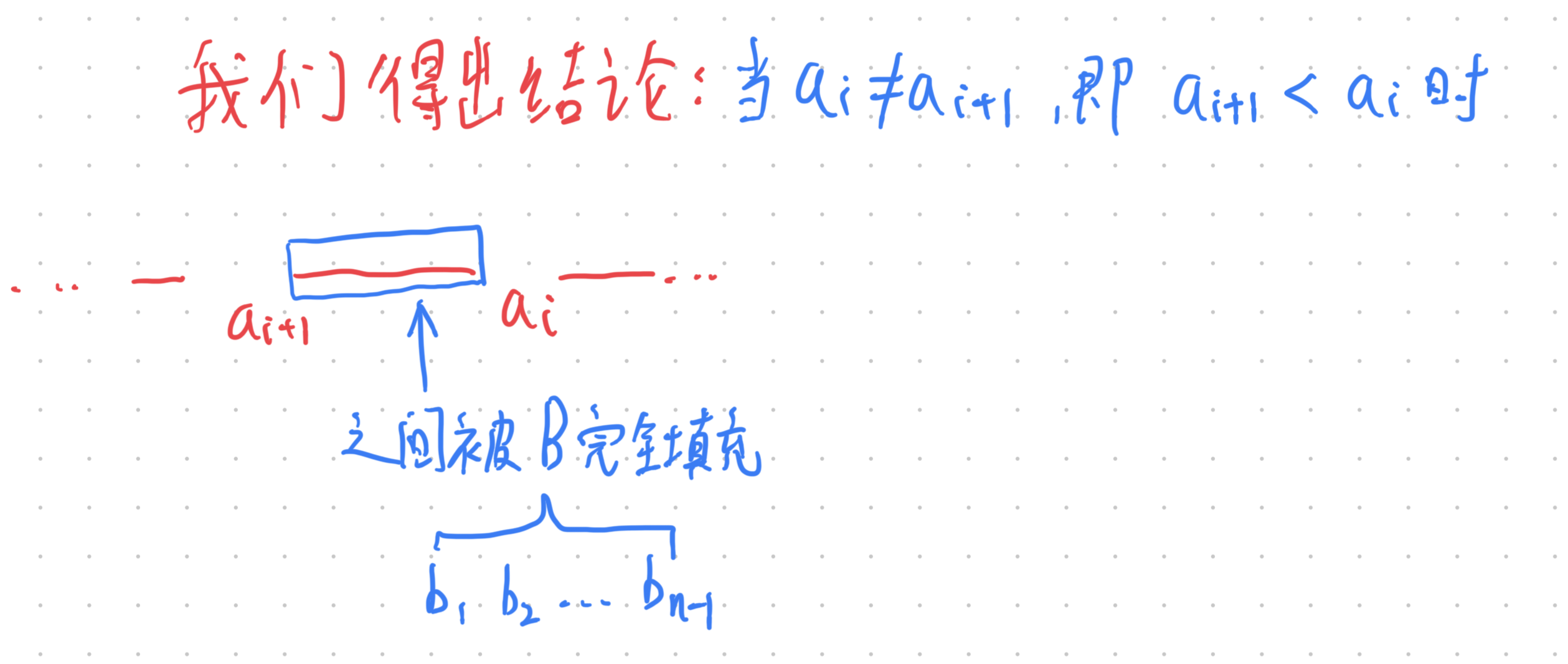
通过上面的推导,我们不难得出如下结论:
这道题目,我们的做法需要用到 dsu on next 技巧。那么要注意这个合并方向。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 vector<ll> B (N + 2 ) ;ll cur; vector<ll> wp; ll top_b = 0 ; for (int i = 1 ; i <= N; ++i) { if (i == 1 ) { if (A[i] > N) { cout << "NO\n" ; return ; } if (A[i] == N) { wp.push_back (i); cur = N; } else if (A[i] == N - 1 ) { B[i] = mod; cur = N - 1 ; } else { cout << "NO\n" ; return ; } merge (A[i], A[i] - 1 ); continue ; } if (A[i] == cur) { wp.push_back (i); } else { ll fcur = find (cur); if (fcur < A[i]) { cout << "NO\n" ; return ; } merge (A[i], A[i] - 1 ); for (ll j = fcur; j > A[i]; --j) { merge (j, j - 1 ); if (wp.empty ()) { cout << "NO\n" ; return ; } B[wp.back ()] = j; wp.pop_back (); } cur = A[i]; B[i] = mod; } } while (!wp.empty ()) { if (!merge (top_b, top_b - 1 )) { cout << "NO\n" ; return ; } B[wp.back ()] = top_b; wp.pop_back (); top_b++; } cout << "YES\n" ; for (int i=1 ;i<=N;++i) { cout<<B[i]<<" " ; }
AChttps://codeforces.com/contest/2207/submission/367198322
源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 #include <bits/stdc++.h> #define all(vec) vec.begin(),vec.end() #define lson(o) (o<<1) #define rson(o) (o<<1|1) #define SZ(a) ((long long) a.size()) #define debug(var) cerr << #var <<" = [" <<var<<"]" <<"\n" ; #define debug1d(a) \ cerr << #a << " = [" ; \ for (int i = 0; i < (int)(a).size(); i++) \ cerr << (i ? ", " : "" ) << a[i]; \ cerr << "]\n" ; #define debug2d(a) \ cerr << #a << " = [\n" ; \ for (int i = 0; i < (int)(a).size(); i++) \ { \ cerr << " [" ; \ for (int j = 0; j < (int)(a[i]).size(); j++) \ cerr << (j ? ", " : "" ) << a[i][j]; \ cerr << "]\n" ; \ } \ cerr << "]\n" ; #define cend cerr<<"\n-----------\n" #define fsp(x) fixed<<setprecision(x) using namespace std;using ll = long long ;using ull = unsigned long long ;using DB = double ;using i128 = __int128;using CD = complex<double >;static constexpr ll MAXN = (ll) 1e6 + 10 , INF = (1ll << 61 ) - 1 ;static constexpr ll mod = 998244353 ; static constexpr double eps = 1e-8 ;const double pi = acos (-1.0 );ll lT, testcase; void Solve () ll N; cin >> N; vector<ll> A (N + 2 ) ; for (int i = 1 ; i <= N; ++i) { cin >> A[i]; } if (!is_sorted (A.begin () + 1 , A.begin () + N + 1 , greater<>())) { cout << "NO\n" ; return ; } map<ll, ll> fa; auto find = [&](ll x) { ll root = x; while (fa.contains (root)) { root = fa[root]; } while (x != root) { tie (x, fa[x]) = make_tuple (fa[x], root); } return root; }; auto merge = [&](ll x, ll y) -> bool { x = find (x), y = find (y); if (x == y) return false ; fa[x] = y; return true ; }; vector<ll> B (N + 2 ) ; ll cur; vector<ll> wp; ll top_b = 0 ; for (int i = 1 ; i <= N; ++i) { if (i == 1 ) { if (A[i] > N) { cout << "NO\n" ; return ; } if (A[i] == N) { wp.push_back (i); cur = N; } else if (A[i] == N - 1 ) { B[i] = mod; cur = N - 1 ; } else { cout << "NO\n" ; return ; } merge (A[i], A[i] - 1 ); continue ; } if (A[i] == cur) { wp.push_back (i); } else { ll fcur = find (cur); if (fcur < A[i]) { cout << "NO\n" ; return ; } merge (A[i], A[i] - 1 ); for (ll j = fcur; j > A[i]; --j) { merge (j, j - 1 ); if (wp.empty ()) { cout << "NO\n" ; return ; } B[wp.back ()] = j; wp.pop_back (); } cur = A[i]; B[i] = mod; } } while ( !wp.empty ()) { if (!merge (top_b, top_b - 1 )) { cout << "NO\n" ; return ; } B[wp.back ()] = top_b; wp.pop_back (); top_b++; } cout << "YES\n" ; for (int i=1 ;i<=N;++i) { cout<<B[i]<<" " ; } cout << "\n" ; } signed main () ios::sync_with_stdio (false ); cin.tie (nullptr ); cout.tie (nullptr ); #ifdef LOCAL cout.setf (ios::unitbuf); #endif cin >> lT; for (testcase = 1 ; testcase <= lT; ++testcase) Solve (); return 0 ; }
对拍拍出来的数据。
brute
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 #include <bits/stdc++.h> #define all(vec) vec.begin(),vec.end() #define lson(o) (o<<1) #define rson(o) (o<<1|1) #define SZ(a) ((long long) a.size()) #define debug(var) cerr << #var <<" = [" <<var<<"]" <<"\n" ; #define debug1d(a) \ cerr << #a << " = [" ; \ for (int i = 0; i < (int)(a).size(); i++) \ cerr << (i ? ", " : "" ) << a[i]; \ cerr << "]\n" ; #define debug2d(a) \ cerr << #a << " = [\n" ; \ for (int i = 0; i < (int)(a).size(); i++) \ { \ cerr << " [" ; \ for (int j = 0; j < (int)(a[i]).size(); j++) \ cerr << (j ? ", " : "" ) << a[i][j]; \ cerr << "]\n" ; \ } \ cerr << "]\n" ; #define cend cerr<<"\n-----------\n" #define fsp(x) fixed<<setprecision(x) using namespace std;using ll = long long ;using ull = unsigned long long ;using DB = double ;using i128 = __int128;using CD = complex<double >;static constexpr ll MAXN = (ll) 1e6 + 10 , INF = (1ll << 61 ) - 1 ;static constexpr ll mod = 998244353 ; static constexpr double eps = 1e-8 ;const double pi = acos (-1.0 );ll lT, testcase; void Solve () ll N; cin >> N; vector<ll> A (N + 2 ) ; for (int i = 1 ; i <= N; ++i) { cin >> A[i]; } vector<ll> sts; for (int i = 0 ; i <= N; ++i) { sts.push_back (i); } bool ok = false ; auto dfs = [&](auto &&go, vector<ll> st, vector<ll> B, ll idx) -> void { if (ok) { return ; } if (idx == 0 ) { ok = true ; return ; } vector<ll> back_up = st; for (int i = 0 ; i <= N + 1 ; ++i) { if (binary_search (all (st), i)) { auto it = lower_bound (all (st), i); st.erase (it); } B.push_back (i); if (idx - 1 < SZ (st) && st[idx - 1 ] == A[N - idx + 1 ]) { go (go, st, B, idx - 1 ); } B.pop_back (); st = back_up; } }; dfs (dfs, sts, {}, N); if (ok) { cout << "YES\n" ; } else { cout << "NO\n" ; } } signed main () ios::sync_with_stdio (false ); cin.tie (nullptr ); cout.tie (nullptr ); #ifdef LOCAL cout.setf (ios::unitbuf); #endif cin >> lT; for (testcase = 1 ; testcase <= lT; ++testcase) Solve (); return 0 ; }
gen
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 #include <bits/stdc++.h> #define all(vec) vec.begin(),vec.end() #define lson(o) (o<<1) #define rson(o) (o<<1|1) #define SZ(a) ((long long) a.size()) #define debug(var) cerr << #var <<" = [" <<var<<"]" <<"\n" ; #define debug1d(a) \ cerr << #a << " = [" ; \ for (int i = 0; i < (int)(a).size(); i++) \ cerr << (i ? ", " : "" ) << a[i]; \ cerr << "]\n" ; #define debug2d(a) \ cerr << #a << " = [\n" ; \ for (int i = 0; i < (int)(a).size(); i++) \ { \ cerr << " [" ; \ for (int j = 0; j < (int)(a[i]).size(); j++) \ cerr << (j ? ", " : "" ) << a[i][j]; \ cerr << "]\n" ; \ } \ cerr << "]\n" ; #define cend cerr<<"\n-----------\n" #define fsp(x) fixed<<setprecision(x) using namespace std;using ll = long long ;using ull = unsigned long long ;using DB = double ;using i128 = __int128;using CD = complex<double >;static constexpr ll MAXN = (ll)1e6 +10 , INF = (1ll <<61 )-1 ;static constexpr ll mod = 998244353 ; static constexpr double eps = 1e-8 ;const double pi = acos (-1.0 );ll lT,testcase; mt19937 rng (chrono::steady_clock::now().time_since_epoch().count()) ;void Solve () cout<<1 <<"\n" ; ll N=uniform_int_distribution <ll>(1 ,7 )(rng); cout<<N<<"\n" ; for (int i=1 ;i<=N;++i) { cout<<uniform_int_distribution <ll>(0 ,N)(rng)<<" " ; } } signed main () ios::sync_with_stdio (false ); cin.tie (nullptr ); cout.tie (nullptr ); #ifdef LOCAL cout.setf (ios::unitbuf); #endif Solve (); return 0 ; }