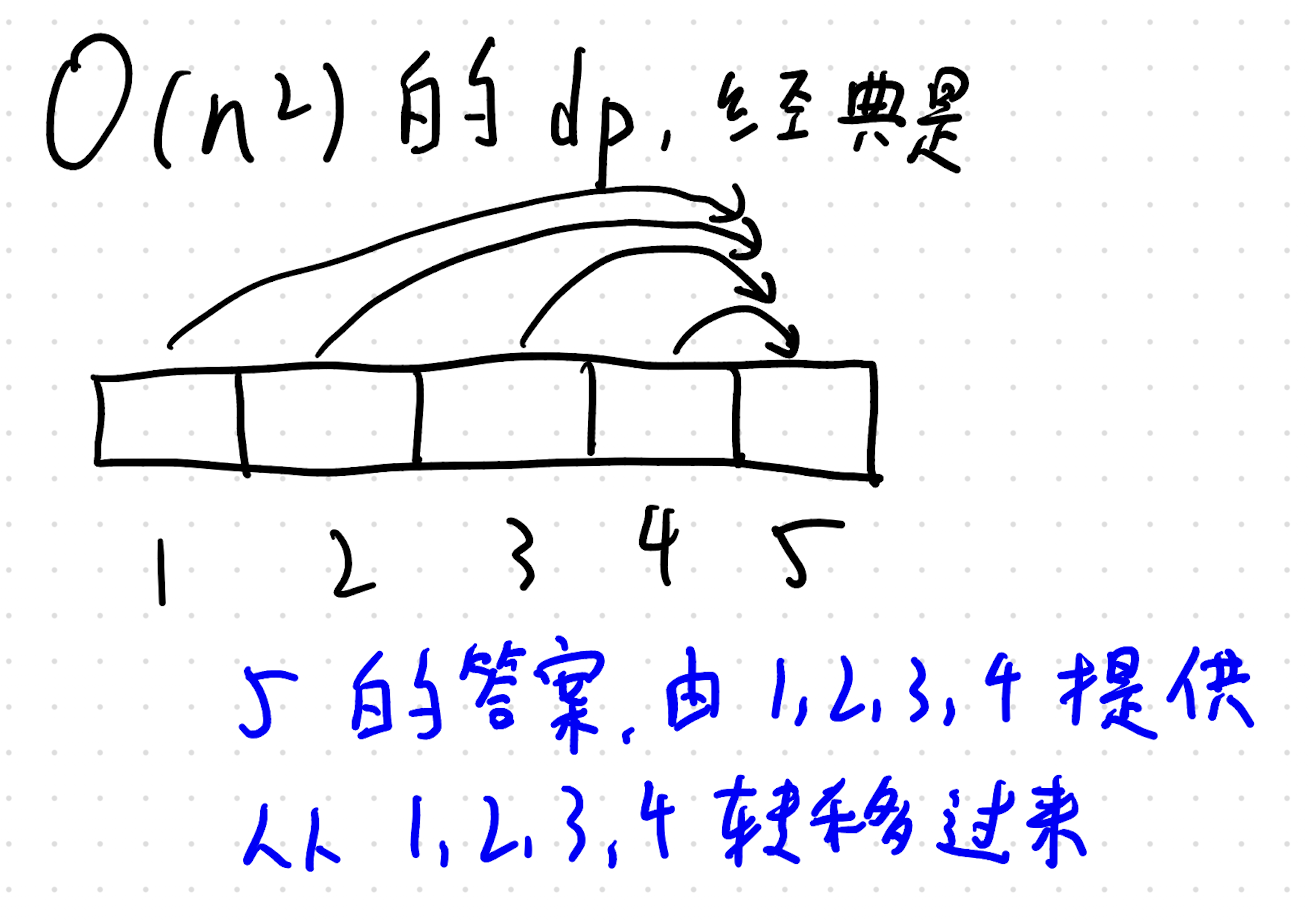
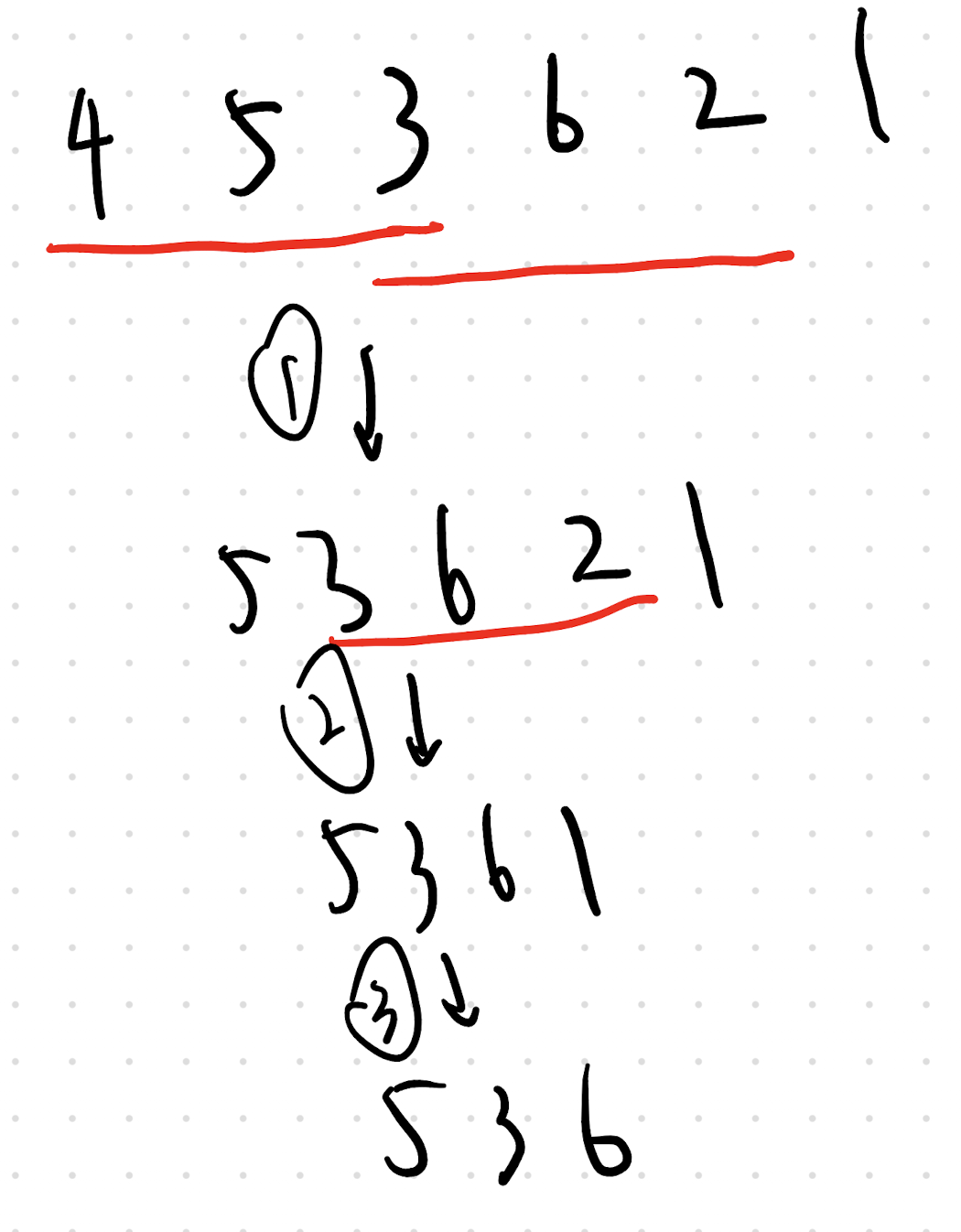题目大意
题目大意
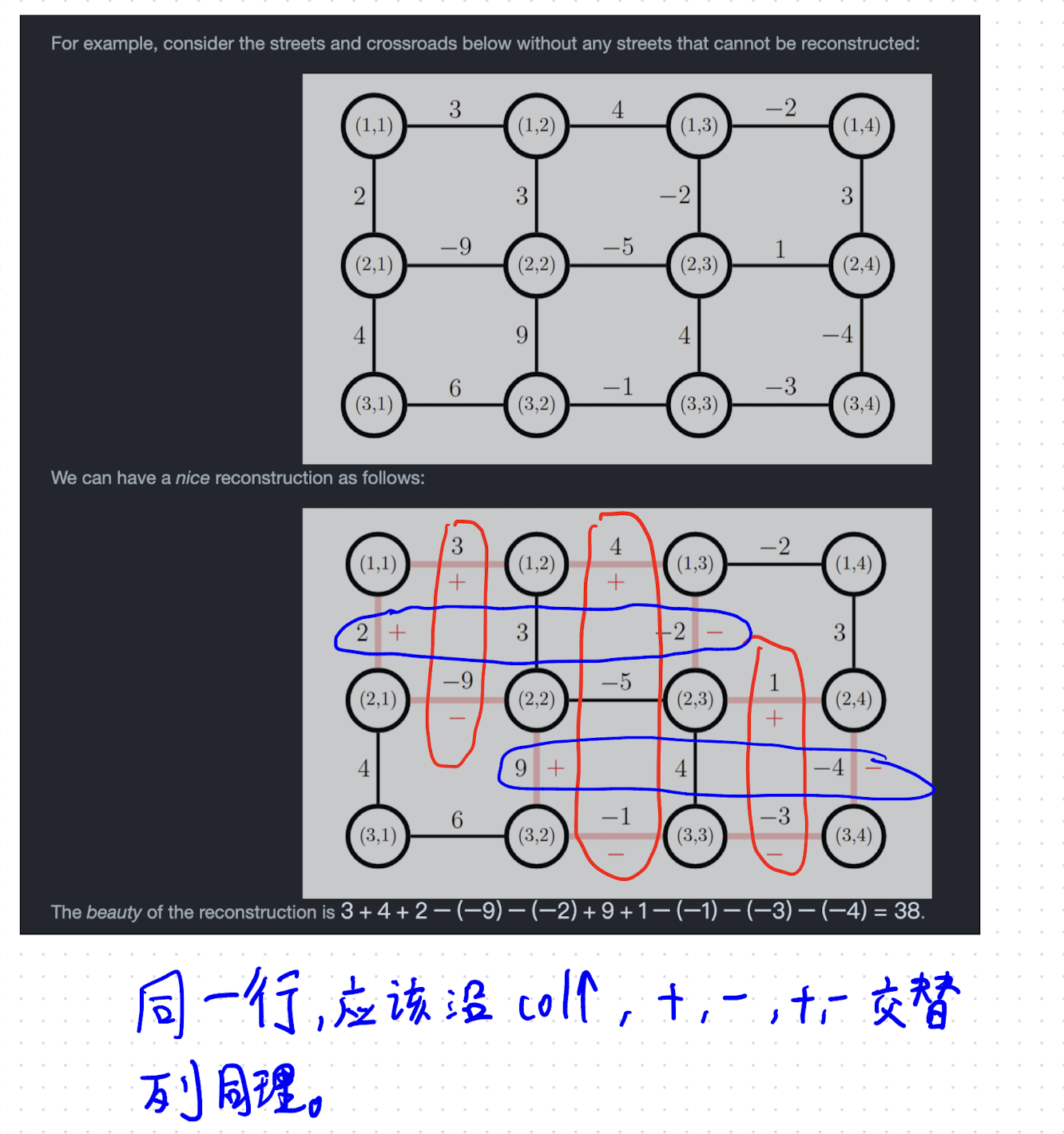
给定一个 的网格图,包含交汇点 到 。网格中的相邻交汇点之间存在道路:
-
点 与 之间为垂直道路,其权值为 。
-
点 与 之间为水平道路,其权值为 。
由于一些事故,部分道路无法被重建(由输入状态 表示),其余道路可选择是否重建(由输入状态 表示)。
对于网格中的任意一个交汇点,如果与其相连且最终被重建的道路数量为偶数,则称该交汇点是“优雅的”。
如果所有的交汇点都是“优雅的”,则称当前的整个道路重建方案是“完美的”。
美丽值计算方式
对于一个“完美的”重建方案,其“美丽值”的计算方式如下:
-
初始美丽值为 。
-
对于每一行 (),找出所有在这一行向下延伸(即连接 与 )且被重建的垂直道路。设它们所在的列号从小到大依次为 ,则将 累加到美丽值中。
-
对于每一列 (),找出所有在这一列向右延伸(即连接 与 )且被重建的水平道路。设它们所在的行号从小到大依次为 ,则将 累加到美丽值中。
(简单来说,就是分别对“每行向下的重建道路”和“每列向右的重建道路”按坐标顺序交替加减其权值)
目标:在所有“完美的”重建方案中,求出最大的“美丽值”。
输入格式
-
第一行包含测试用例数 ()。
-
每个测试用例的第一行包含 和 ()。
-
接下来 行,每行 个整数,表示垂直道路的权值 。
-
接下来 行,每行 个整数,表示水平道路的权值 。
-
接下来 行,每行一个长度为 的 01 字符串,表示各条垂直道路是否可以被重建。
-
接下来 行,每行一个长度为 的 01 字符串,表示各条水平道路是否可以被重建。
输出格式
对于每个测试用例,输出一个整数,表示在所有完美重建方案中能获得的最大美丽值。
样例数据
1 | 4 |
样例解释
以第一个测试用例为例(,且所有道路均允许重建),在使得所有交汇点相连重建道路数均为偶数的前提下,取得最大美丽值的方案如下:
垂直道路(向下的边)的选择:
-
第 1 行向下重建位于列 1、列 3 的道路,权值分别为 ,贡献值为:
-
第 2 行向下重建位于列 2、列 4 的道路,权值分别为 ,贡献值为:
水平道路(向右的边)的选择:
-
第 1 列向右重建位于行 1、行 2 的道路,权值分别为 ,贡献值为:
-
第 2 列向右重建位于行 1、行 3 的道路,权值分别为 ,贡献值为:
-
第 3 列向右重建位于行 2、行 3 的道路,权值分别为 ,贡献值为:
该方案不仅满足所有交汇点度数皆为偶数,且其总美丽值为:
。
在第二个测试用例中,受限于无法重建的道路限制,唯一的完美重建方案是“不重建任何道路”,因此最大美丽值为 。
思路讲解
像这道题目,对于重建的这个约束太多。
Consider the case without any “accidents”, i.e., when there are no additional restrictions on the reconstructed streets.
我们可以先把所有对于重建边操作的限制,就是有一些边不能进行重建操作,给删除,我们会做了吗?(注意这里不能够把这个偶数条边的这个结果也给删了)
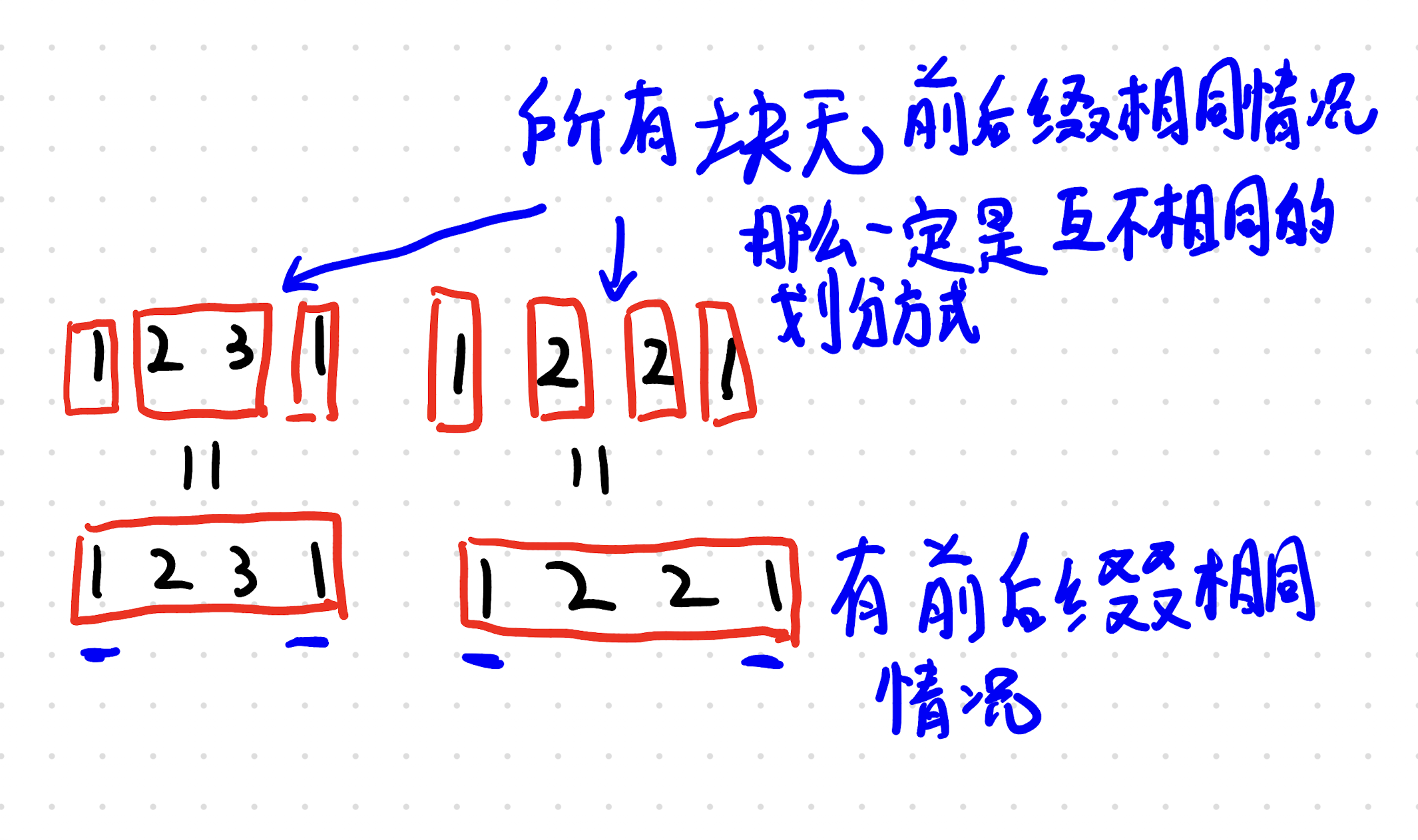
其实也没有那么简单,你首先要注意到,对于一维问题,成对的±,相当于一系列差分的和。那么,还需要特意去选吗?直接选全部为正的差分值不就好了?(连续选了两个或更多差分值,有重叠也没关系,可以使用我们下图的逆运算)
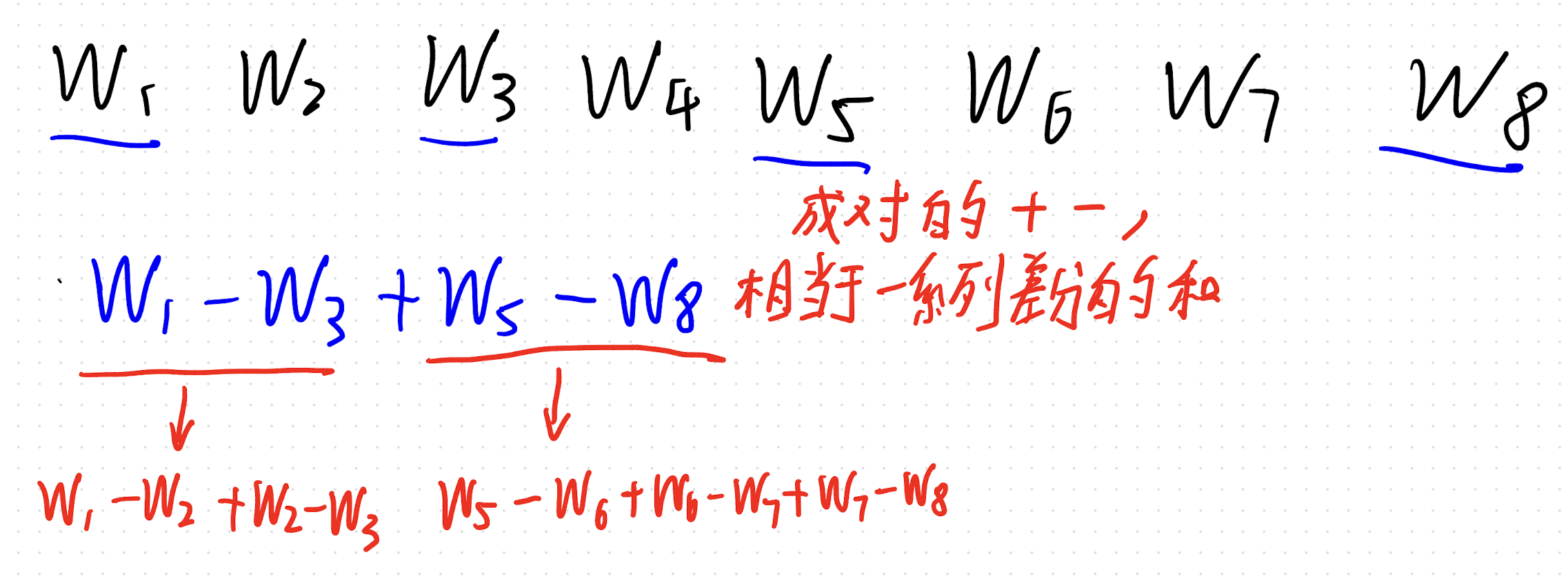
但是这个只能解决成对的 ± 问题呀,要是 ±+,以 + 结尾的不成对串如何解决呢?
来,我们仔细看看。只需要在末尾加一个 0,然后采用同样的贪心即可。
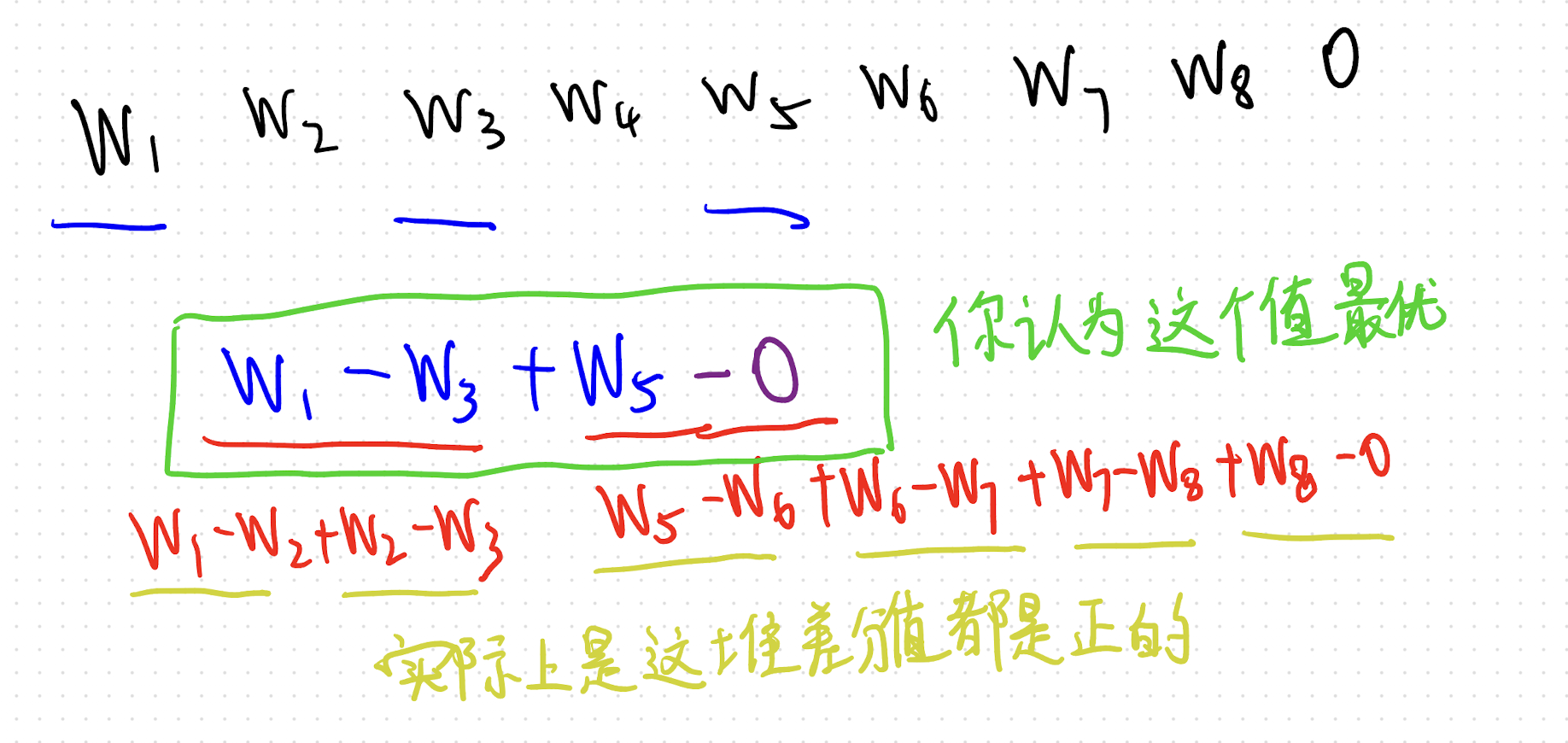
好,下面我们要正式解决这个问题了。
问题来到了 2D,我们发现有一个这个约束,就是,点的偶数边重建约束,这个还是有点烦的,怎么样去解决这个问题?
不难想到,如果一个点的边是否重建受到约束,我们能不能找到一个东西,其无论怎么样取,都符合约束呢?这样无论是贪心还是 dp,都会好解决的多。
Codeforces Round 1026 (Div. 2)-CF-1026-E. Melody
Codeforces Round 1081 (Div. 2)-CF-1081-E. Swap to Rearrange(按值进行图论建模)(欧拉回路)
通过这些题目,我们知道,如果说所有的点的度数都是偶数,组成的一定是一个欧拉回路(在无向联通图中)。
那么在这道题目中,题目所给我们的图,实际上是一个对偶图(就是边不相交的平面图,显然,网格图是对偶图),欧拉回路在对偶图中,实际上是一个割(这个是不难得出的,说白了,你在平面上一笔画出一条回路,当然能把平面划分为两部分,特别还要求你的这个路径是不会自相交的,因为所有边都互不相交)。注意,可以确定的是,这些欧拉回路
那既然是一个割,把一个面分割成了两部分,我们就想到了黑白染色。
这个时候求解为什么能想到小的单位面元?从更高的观点来看,其实这个是离散型二维格林公式。
没问题。这就把格林公式的灵魂,在这道离散的网格题目中扒得干干净净。这才是这道题最深层的物理/数学本质。
一、 格林公式(Green’s Theorem)的核心灵魂是什么?
在高等数学里,格林公式极其优美,它建立了一个桥梁:
别被公式吓到,它的灵魂用人话说就是:
“沿着一个闭合边界(外轮廓 )转一圈的累积量,完全等于这个边界所包围的区域(内部面 )里,每一个‘无穷小面元’的某种内在属性(旋度)的总和。”
为什么会这样?
因为如果你把区域 切成无数个相邻的“小方格”,当你把所有小方格的“环量”加起来时,相邻方格的公共边界,一个是从左往右走,另一个是从右往左走,互相抵消了! 最后没被抵消的,就只剩下最外面的那一圈大边界 。
二、 题目中的“线积分”在哪?
题目定义的“美丽值”计算方式非常奇怪:
“在每一行 中,选中的列 交替加减:”
我们用几何的眼光来看这个式子。
题目要求所有十字路口的联边数必须是偶数。在图论里,这意味着选出来的边,必定构成若干个闭合的环(多边形)。
假设我们选出了一个大矩形环(左边界在 ,右边界在 ,上边界在 ,下边界在 )。
按照题目的计算规则:
- 对于位于 的左垂直边,它排在第 1 个(奇数),前面是正号 。
- 对于位于 的右垂直边,它排在第 2 个(偶数),前面是负号 。
- 同理,上方的水平边排第一 。
- 下方的水平边排第二 。
发现了吗?
这个交替加减的规则,本质上就是定义了一个有向的线积分规则:
对于任何一个闭合形状,它的左边界贡献正,右边界贡献负,上边界贡献正,下边界贡献负。
这就是格林公式等式左边的那个 !也就是“沿着外围边界的环量”!
三、 把格林公式用在离散网格上(微元化)
既然题目的美丽值求的是一个大环的“线积分(环量)”。
那么根据格林公式的思想,我们完全可以把这个大环,撕碎成无数个 的“无穷小面元(Basis / 小方块)”!
我们取网格中第 行、第 列的那个 的小方块。
如果我们把题目的线积分规则(左+,右-,上+,下-)强制套用到这个最微小的方块上,它就会产生一个属于它自己的“旋度”(也就是内在权值):
这就是那个 Basis 权值的确切由来!它就是离散版本的 !
四、 完美闭环:局部加和 = 全局边界
现在,我们见证格林公式在离散网格上发威的瞬间。
如果我们选定了某几个连续的小方块(构成了一个区域 )。
我们直接把这几个小方块的 (旋度)全部加起来。
会发生什么?
比如方块 和右边的方块 被同时选中。
- 的旋度里有一项是 (它是右边界,取负)。
- 的旋度里有一项是 (它是左边界,取正)。
当这两个方块加在一起时,中间这条公共边 直接抵消为 0!
这在数学上绝对成立,没有任何例外:
只要你把一堆小方块的权值加起来,它们内部所有共享的边必定全部互相抵消。最后加出来的总和,绝对等于这堆小方块构成的外轮廓边界,按照题目“左+右-上+下-”规则算出来的值!
结语
格林公式告诉我们:算复杂的边界太难了,算简单的内部面元再相加就容易了。
题目要求我们在无数种复杂的“偶数闭合边界”中找最大值,这极其困难,因为边界的形状千变万化,且互相牵制。
但格林公式赋予了我们降维打击的武器:
我们根本不去管什么边界和交替相加!我们直接算好每一个 小方块的固定内在权值(旋度),然后只要权值是正的,我就把它拿走(贪心选这个面元)。
你拿走的这堆正权值面元,它们的外边缘自然而然就生成了题目要求的最优闭合边界,且美丽值自动最大化!
这就是这道算法题背后最深沉、最优美的数学灵魂。

具体而言,如下图所示:
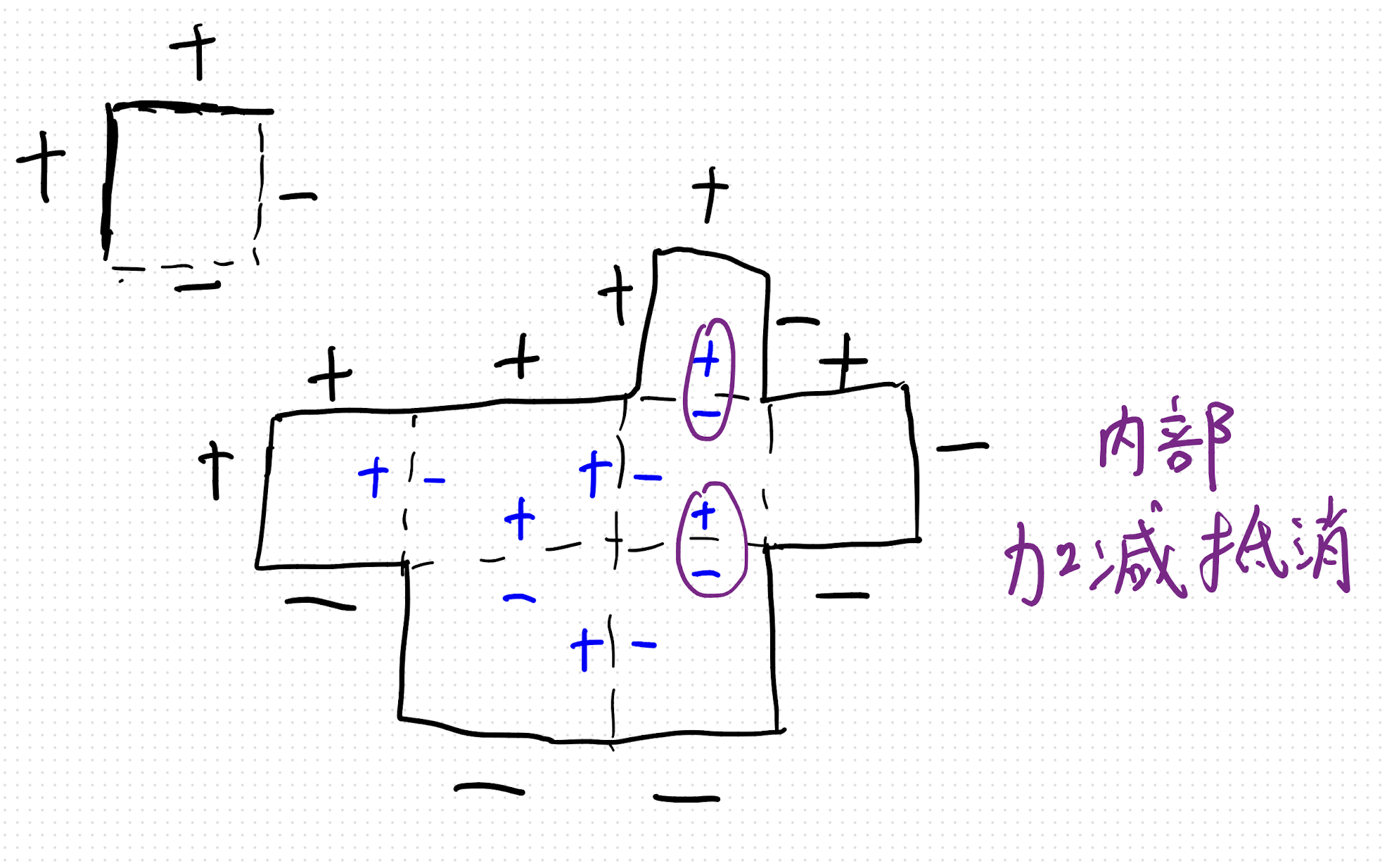
现在问题在于如何处理这个有些边不能进行重建操作?
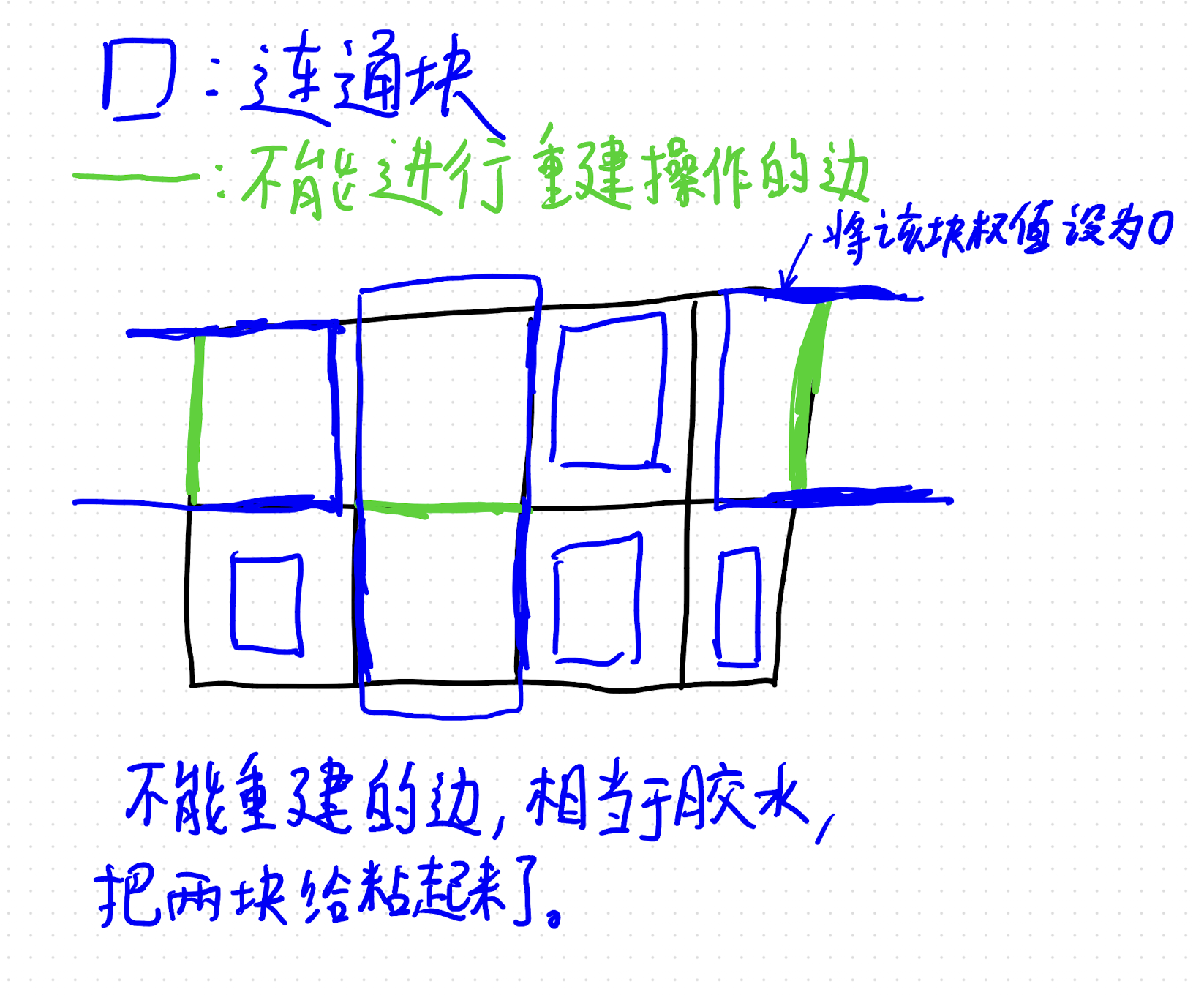
那么上图已经讲的很清楚了,不能重建的边,就像是胶水,直接把这两块给粘起来,这条边就不会再操作了。唯一一个特殊点就是最边上的边就是和外部联通了,这里我们需要设置一个外部节点 out_node,把他和 out 连接在一起即可。
AC代码
AC
https://codeforces.com/contest/2205/submission/365321534
1 | /** |
心路历程(WA,TLE,MLE……)

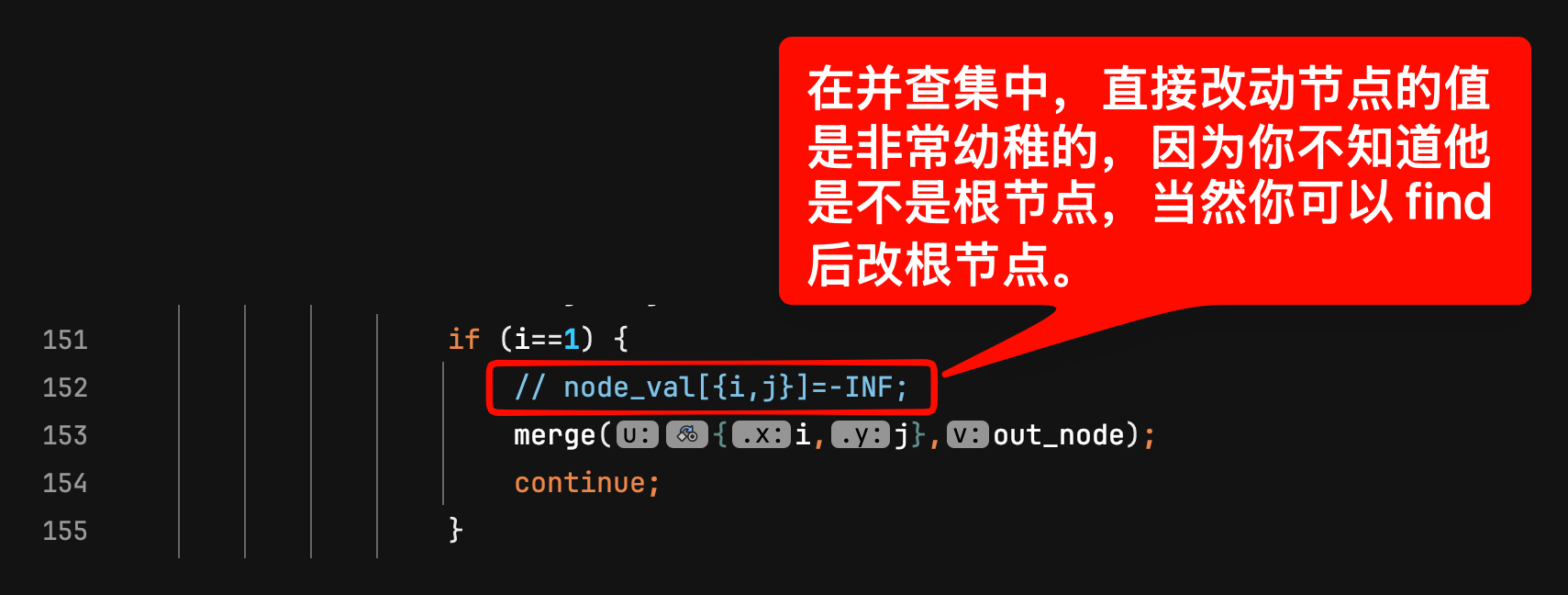
在并查集中,直接改动节点的值是非常幼稚的,因为你不知道他是不是根节点,当然你可以 find 后改根节点。
AC
https://codeforces.com/contest/2205/submission/365204709
AI 代码确实是没什么问题。