题意
给定 n n n F = { f 1 , f 2 , … , f n } F=\{f_1, f_2, \dots, f_n\} F = { f 1 , f 2 , … , f n } f i ( x ) = a i x 2 + b i x + c i f_i(x) = a_i x^2 + b_i x + c_i f i ( x ) = a i x 2 + b i x + c i
定义两个函数 f f f g g g 独立 的,当且仅当对于所有的实数 x ∈ R x \in \mathbb{R} x ∈ R f ( x ) ≠ g ( x ) f(x) \neq g(x) f ( x ) = g ( x )
定义一个函数集合 G ⊆ F G \subseteq F G ⊆ F 有序 的,当且仅当 G G G
对于每一个 i i i 1 ≤ i ≤ n 1 \le i \le n 1 ≤ i ≤ n f i f_i f i S ⊆ F S \subseteq F S ⊆ F f i ∈ S f_i \in S f i ∈ S S S S ∣ S ∣ |S| ∣ S ∣
数据范围
1 ≤ t ≤ 1 0 4 1 \le t \le 10^4 1 ≤ t ≤ 1 0 4
1 ≤ n ≤ 3000 1 \le n \le 3000 1 ≤ n ≤ 3 0 0 0
− 1 0 6 ≤ a i , b i , c i ≤ 1 0 6 , a i ≠ 0 -10^6 \le a_i, b_i, c_i \le 10^6, a_i \neq 0 − 1 0 6 ≤ a i , b i , c i ≤ 1 0 6 , a i = 0
保证所有测试用例中 n 2 n^2 n 2 300 0 2 3000^2 3 0 0 0 2
输入格式
第一行包含一个整数 t t t n n n n n n a i , b i , c i a_i, b_i, c_i a i , b i , c i i i i
输出格式
对于每个测试用例,输出一行 n n n i i i f i f_i f i
样例输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 3 4 1 2 -1 -3 0 -3 -1 4 -5 1 2 -4 5 3 0 0 1 0 -5 -3 0 0 -1 0 10 1 0 -10 5 884 -667 497 680 -973 213 23 -548 -412 826 359 -333 773 212 218
样例输出
1 2 3 3 2 3 3 3 3 2 2 3 3 3 3 1 2
样例解释(第一组数据)
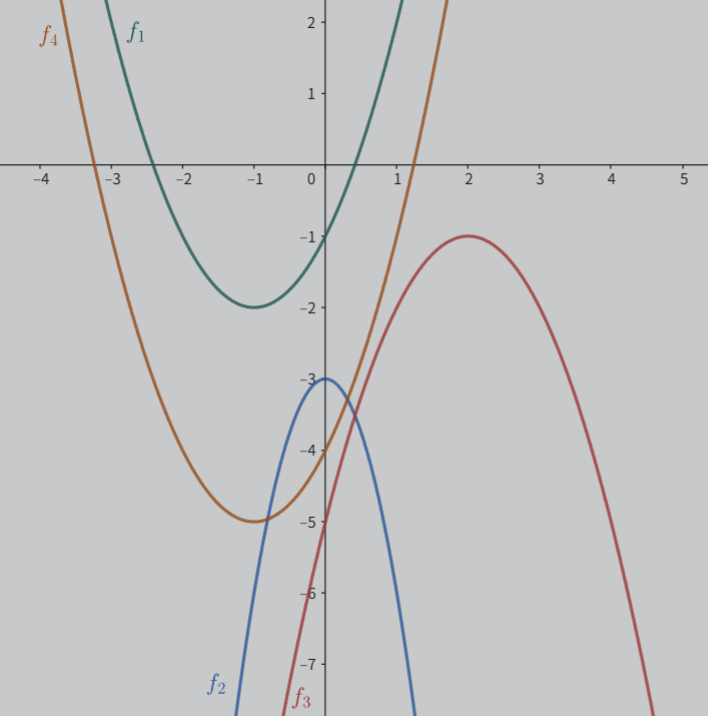
给定的 4 个函数如下:
f 1 ( x ) = x 2 + 2 x − 1 f_1(x) = x^2 + 2x - 1 f 1 ( x ) = x 2 + 2 x − 1
f 2 ( x ) = − 3 x 2 − 3 f_2(x) = -3x^2 - 3 f 2 ( x ) = − 3 x 2 − 3
f 3 ( x ) = − x 2 + 4 x − 5 f_3(x) = -x^2 + 4x - 5 f 3 ( x ) = − x 2 + 4 x − 5
f 4 ( x ) = x 2 + 2 x − 4 f_4(x) = x^2 + 2x - 4 f 4 ( x ) = x 2 + 2 x − 4
各函数包含于其中的最大有序子集如下:
对于 f 1 f_1 f 1 { f 1 , f 3 , f 4 } \{f_1, f_3, f_4\} { f 1 , f 3 , f 4 }
对于 f 2 f_2 f 2 { f 1 , f 2 } \{f_1, f_2\} { f 1 , f 2 }
对于 f 3 f_3 f 3 { f 1 , f 3 , f 4 } \{f_1, f_3, f_4\} { f 1 , f 3 , f 4 }
对于 f 4 f_4 f 4 { f 1 , f 3 , f 4 } \{f_1, f_3, f_4\} { f 1 , f 3 , f 4 }
官方题解(写的挺好的)
让我们考虑一个图G G G u ↔ v u\leftrightarrow v u ↔ v f u f_u f u f v f_v f v G G G 连续 函数。也就是说,如果对于所有x ∈ R x \in \mathbb{R} x ∈ R f i ( x ) ≠ f j ( x ) f_i(x) \neq f_j(x) f i ( x ) = f j ( x )
f i ( x ) > f j ( x ) f_i(x) \gt f_j(x) f i ( x ) > f j ( x ) x ∈ R x \in \mathbb{R} x ∈ R f i ( x ) < f j ( x ) f_i(x) \lt f_j(x) f i ( x ) < f j ( x ) x ∈ R x \in \mathbb{R} x ∈ R u ≺ v u \prec v u ≺ v x ∈ R x \in \mathbb{R} x ∈ R f u ( x ) < f v ( x ) f_u(x) \lt f_v(x) f u ( x ) < f v ( x ) 关系≺ \prec ≺ a ≺ b a \prec b a ≺ b b ≺ c b \prec c b ≺ c a ≺ c a \prec c a ≺ c
如果u ≺ v u \prec v u ≺ v v ≺ u v \prec u v ≺ u
不能存在任何u u u u ≺ u u \prec u u ≺ u 严格偏序 。D D D u → v u \to v u → v u ≺ v u \prec v u ≺ v ≺ \prec ≺ k k k D D D k k k D D D ≺ \prec ≺ D D D D D D d p l [ v ] \mathtt{dp}_l[v] d p l [ v ] v v v d p r [ v ] \mathtt{dp}_r[v] d p r [ v ] v v v v v v d p l [ v ] + d p r [ v ] − 1 \mathtt{dp}_l[v]+\mathtt{dp}_r[v]-1 d p l [ v ] + d p r [ v ] − 1 O ( n 2 ) \mathcal{O}(n^2) O ( n 2 ) d p r [ v ] \mathtt{dp}_r[v] d p r [ v ] d p r [ v ] \mathtt{dp}_r[v] d p r [ v ]
错误的使用了 bfs 求解最长链
不应该使用这个 BFS,无论你怎么样 BFS 它都不太能够求解这个最长的问题,因为毕竟 BFS 是求最短路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 auto solve=[&](vector<ll> &mx_chain,const vector<vector<ll>> &g) -> void { for (int i=1 ;i<=N;++i) { queue<pair<ll,ll>> q; vector<char > vis (N+2 ) ; vis[i]=true ; q.push ({i,0 }); ll ans=0 ; while (!q.empty ()) { auto [u,dis]=q.front (); q.pop (); ans=max (ans,dis); for (auto to:g[u]) { if (vis[to]) continue ; vis[to]=1 ; q.push ({to,dis+1 }); } } mx_chain[i]=ans; } };
2025 United Kingdom and Ireland Programming Contest (UKIEPC 2025) 2025 英国 ICPC——J. Joust Sort(拓扑排序解决依赖排序问题)
那么我们实际上可以使用记忆化的 DFS 去解决这个问题。
实际上来说呢,如果这个图它是一个完全图,它没有任何其他的性质的话,实际上是一个 NP 问题,也就是团问题。因此呢,实际上这个关系之间具有严格偏序关系。因此这个图实际上是一个 DAG。我们是就是要在一个 DAG 上去求包含该节点的一个最长链。
那么其实不难想到,这个是真不难想到,就是你去求包含一个节点的最长链的话,直接去求是比较困难的。你可以求,先求以这个点为起点的最长链(长度),再去求以这个点为终点的最长链(长度)。
不过其实求以这个点为终点的最长链的长度,你可能会说,哎,我不会求啊,这个怎么求?哎,实际上很简单,你就把图所有的边全部反向 ,然后再用跑,这个求以这个点为起点的最长链长度再跑一遍就好了。
实际上来说,这个东西,这个记忆化 DFS 能跑,也是因为这张图具有 DAG 性质。你实在不放心,也可以用拓扑排序去跑一个 DP 也不难,反正。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 auto solve=[&](vector<ll> &mx_chain,const vector<vector<ll>> &g) -> void { vector<ll> dp (N+2 ); vector<char > vis (N+2 ) ; auto dfs=[&](auto && self,ll u) -> void { if (vis[u]) { return ; } vis[u]=true ; for (auto to:g[u]) { self (self,to); dp[u]=max (dp[u],dp[to]); } dp[u]+=1 ; }; for (int i=1 ;i<=N;++i) { dfs (dfs,i); mx_chain[i]=dp[i]; } }; solve (mx_chain1,org_g);solve (mx_chain2,rev_g);
**遗漏了这个做差式二次函数退化的情况**,导致这个 Q U A D 的小于号运算符出现了判断错误。
1 2 3 4 5 6 7 8 9 10 struct Quad { ll a,b,c; bool operator < (const Quad &o) const { ll a1=a-o.a,b1=b-o.b,c1=c-o.c; if (b1*b1-4 *a1*c1>=0 ) return false ; return c<o.c; } };
TLE ,注意⚠️,边的数量也会影响记忆化 DFS 的时间复杂度
https://codeforces.com/contest/2195/submission/363305041
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 auto solve=[&](vector<ll> &mx_chain,const vector<vector<ll>> &g) -> void { vector<ll> dp (N+2 ); vector<char > vis (N+2 ) ; auto dfs=[&](auto && self,ll u) -> void { if (vis[u]) { return ; } vis[u]=true ; for (auto to:g[u]) { self (self,to); dp[u]=max (dp[u],dp[to]); } dp[u]+=1 ; }; for (int i=1 ;i<=N;++i) { dp.assign (N+2 ,0 ); vis.assign (N+2 ,0 ); dfs (dfs,i); mx_chain[i]=dp[i]; } };
其实 TLE 的原因很简单,就是 DFS 实际上是 O ( V + E ) = O ( N 2 ) O(V + E) = O(N^2) O ( V + E ) = O ( N 2 ) O ( N 3 ) O(N^3) O ( N 3 ) 单次 DFS 是 O ( V + E ) = O ( N 2 ) O(V + E) = O(N^2) O ( V + E ) = O ( N 2 ) for 循环里面每轮都 dp.assign(N+2,0) 和 vis.assign(N+2,0),把之前所有记忆化结果全部清空了。这导致:
第 1 次从节点 1 出发做 DFS,算完所有可达节点的 dp 值
第 2 次清空 ,从节点 2 重新算一遍
第 3 次清空 ,从节点 3 重新算一遍
……共 N N N O ( N 2 ) O(N^2) O ( N 2 ) O ( N 3 ) O(N^3) O ( N 3 ) dfs(dfs,1) 可能就把大部分节点的 dp 都算好了,后续的 dfs(dfs,i) 碰到已访问节点直接返回,总复杂度降为 O ( N 2 ) O(N^2) O ( N 2 )
原始文件:src/F_Parabola_Independence.cpp(未改动)
调试副本:src/F_Parabola_Independence.debug2.cpp
临时编译产物:/tmp/cursor-algo-debug/
AChttps://codeforces.com/contest/2195/submission/363306906
源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 #include <bits/stdc++.h> #define all(vec) vec.begin(),vec.end() #define lson(o) (o<<1) #define rson(o) (o<<1|1) #define SZ(a) ((long long) a.size()) #define debug(var) cerr << #var <<" = [" <<var<<"]" <<"\n" ; #define debug1d(a) \ cerr << #a << " = [" ; \ for (int i = 0; i < (int)(a).size(); i++) \ cerr << (i ? ", " : "" ) << a[i]; \ cerr << "]\n" ; #define debug2d(a) \ cerr << #a << " = [\n" ; \ for (int i = 0; i < (int)(a).size(); i++) \ { \ cerr << " [" ; \ for (int j = 0; j < (int)(a[i]).size(); j++) \ cerr << (j ? ", " : "" ) << a[i][j]; \ cerr << "]\n" ; \ } \ cerr << "]\n" ; #define debug3d(a) \ cerr << #a << " = [\n" ; \ for (int i = 0; i < (int)(a).size(); i++) \ { \ cerr << " [\n" ; \ for (int j = 0; j < (int)(a[i]).size(); j++) \ { \ cerr << " [" ; \ for (int k = 0; k < (int)(a[i][j]).size(); k++) \ cerr << (k ? ", " : "" ) << a[i][j][k]; \ cerr << "]\n" ; \ } \ cerr << " ]\n" ; \ } \ cerr << "]\n" ; #define cend cerr<<"\n-----------\n" #define fsp(x) fixed<<setprecision(x) using namespace std;using ll = long long ;using ull = unsigned long long ;using DB = double ;using CD = complex<double >;static constexpr ll MAXN = (ll)1e6 +10 , INF = (1ll <<61 )-1 ;static constexpr ll mod = 998244353 ; static constexpr double eps = 1e-8 ;const double pi = acos (-1.0 );ll lT,testcase; struct Quad { ll a,b,c; bool operator < (const Quad &o) const { ll a1=a-o.a,b1=b-o.b,c1=c-o.c; if (a1==0 ) { if (b1!=0 ) return false ; return c<o.c; } if (b1*b1-4 *a1*c1>=0 ) return false ; return c<o.c; } }; void Solve () ll N; cin >> N; vector<Quad> A (N+2 ) ; for (int i=1 ;i<=N;++i) { cin>>A[i].a>>A[i].b>>A[i].c; } vector<vector<ll>> org_g (N+2 ),rev_g (N+2 ); for (int i=1 ;i<=N;++i) { for (int j=1 ;j<=N;++j) { if (i==j) continue ; if (A[i]<A[j]) { org_g[j].push_back (i); rev_g[i].push_back (j); } } } vector<ll> mx_chain1 (N+2 ) ,mx_chain2 (N+2 ) ; auto solve=[&](vector<ll> &mx_chain,const vector<vector<ll>> &g) -> void { vector<ll> dp (N+2 ); vector<char > vis (N+2 ) ; auto dfs=[&](auto && self,ll u) -> void { if (vis[u]) { return ; } vis[u]=true ; for (auto to:g[u]) { self (self,to); dp[u]=max (dp[u],dp[to]); } dp[u]+=1 ; }; for (int i=1 ;i<=N;++i) { dfs (dfs,i); mx_chain[i]=dp[i]; } }; solve (mx_chain1,org_g); solve (mx_chain2,rev_g); for (int i=1 ;i<=N;++i) { ll ans=mx_chain1[i]+mx_chain2[i]-1 ; cout<<ans<<" " ; } cout<<"\n" ; } signed main () ios::sync_with_stdio (false ); cin.tie (nullptr ); cout.tie (nullptr ); #ifdef LOCAL cout.setf (ios::unitbuf); #endif cin >> lT; for (testcase=1 ;testcase<=lT;++testcase) Solve (); return 0 ; }