题目大意
CF2169C Range Operation
题目描述
给定一个长度为 n 的整数数组 a。
你可以进行以下操作:选择一个区间 [l,r](1≤l≤r≤n),并将区间内的元素 al,al+1,…,ar 全部替换为 l+r。
你的任务是计算,在最多允许进行一次上述操作的情况下,数组的和可能达到的最大值。
输入格式
第一行包含一个整数 t(1≤t≤104),表示测试用例的数量。
每个测试用例的第一行包含一个整数 n(1≤n≤2⋅105)。
第二行包含 n 个整数 a1,a2,…,an(0≤ai≤2n)。
输入额外限制:所有测试用例中 n 的总和不超过 2⋅105。
输出格式
对于每个测试用例,输出一个整数,表示在至多进行一次操作后数组的最大和。
输入输出样例 #1
输入 #1
1
2
3
4
5
6
7
8
9
10
| 4
3
2 5 1
2
4 4
4
1 3 2 1
5
3 2 0 9 10
|
输出 #1
说明/提示
在第一个样例中,可以对子数组 [3,3] 执行操作,得到数组 [2,5,6],其和为 13。
在第二个样例中,不需进行任何操作。
在第三个样例中,可以对子数组 [1,4] 执行操作,得到数组 [5,5,5,5],其和为 20。
在第四个样例中,可以对子数组 [2,3] 执行操作,得到数组 [3,5,5,9,10],其和为 32。
由 ChatGPT 5 翻译
思路讲解
类似于求解最大字段和的 dp。
思路参考了 starsilk 的代码。
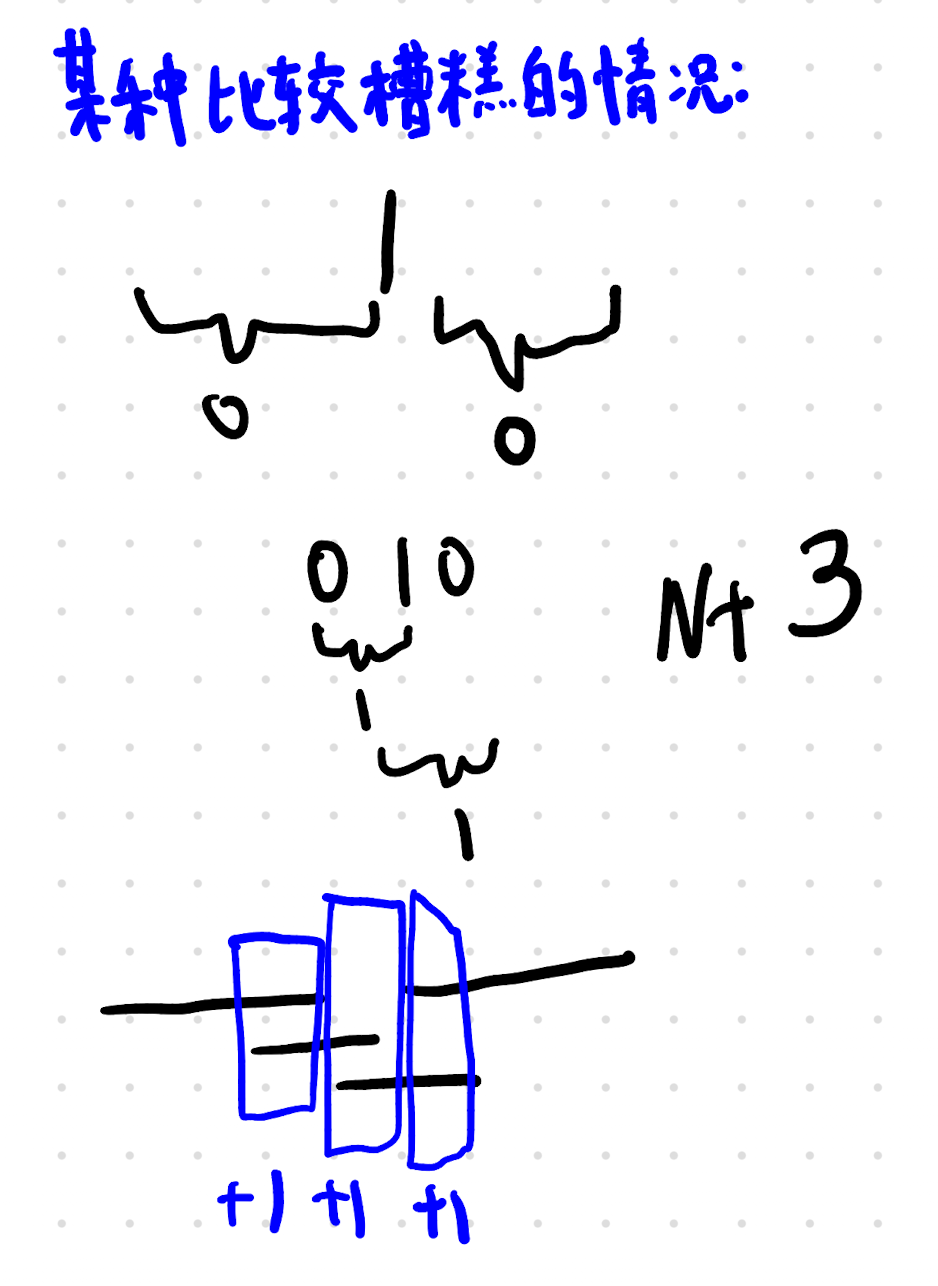
首先,我们必须要把 r,l 两者分开。
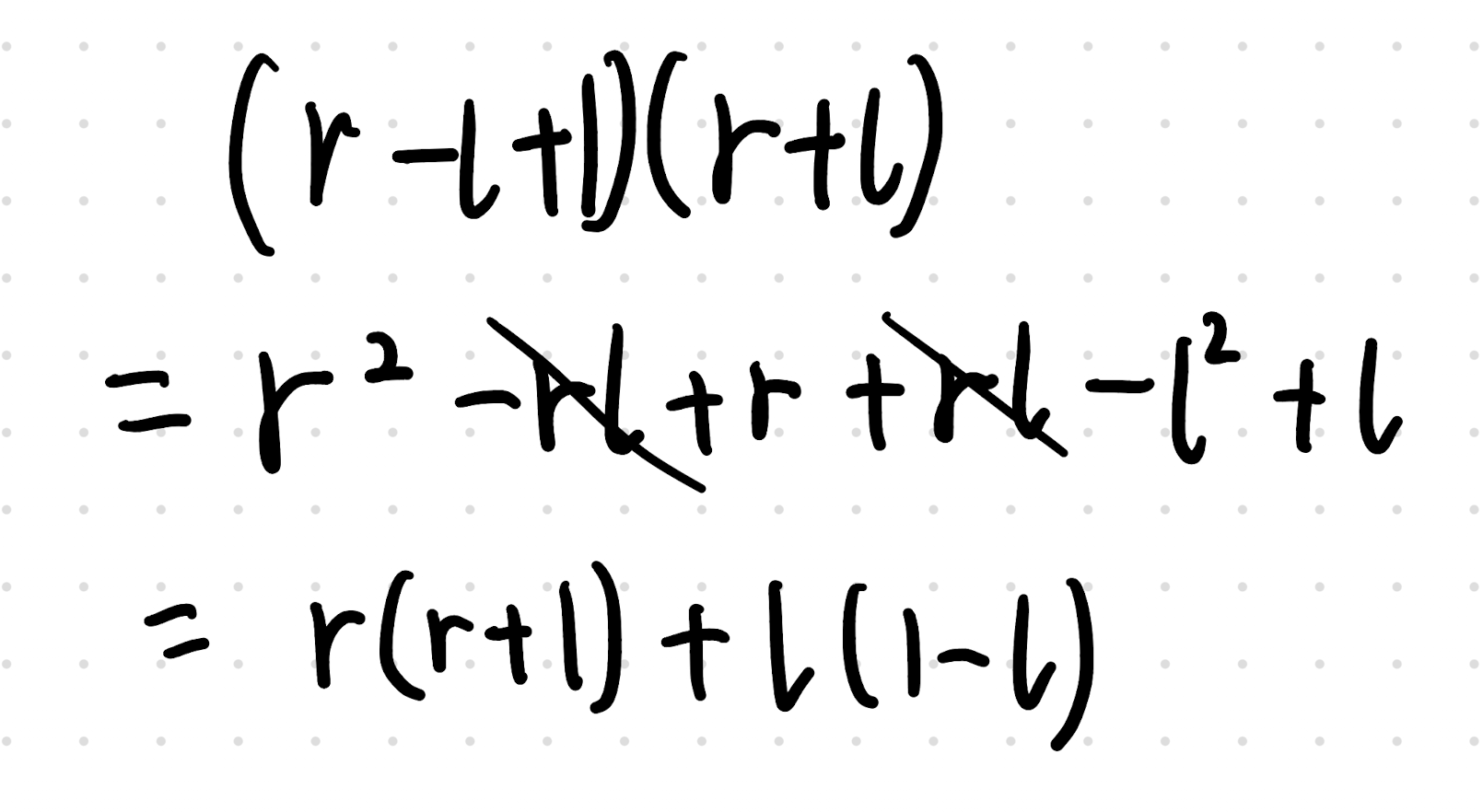
我们就会发现,总答案就可以写为:(Sx 表示 x 的前缀和)
ans=Sl−1+l(1−l)+Sn−Sr+r(r+1)
这个明显可以使用这个 dp,因为我们只需要最优化 Sl−1+l(1−l) 这个值,就直接最优化了左端点。而右端点的转移,一旦不用考虑这个左端点是不是最优的,就容易多了。
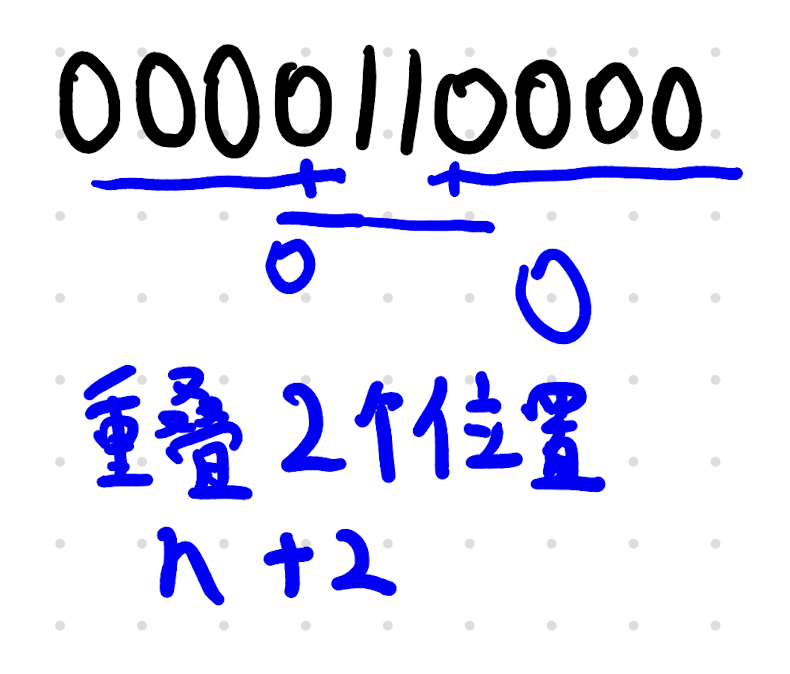
那我们定义,dpi,0 为前缀和(操作前),dpi,1 表示从 i 及之前开始转化的最大化 Sl−1+l(1−l) 值(可以理解为操作中,但是不严谨),dpi,2 表示 i 以及之前转化结束,所能达到的最大和(操作后)。
之所以定义三个状态,而不是两个,是为了避免重复操作。
dpi,0=dpi−1,0+aidpi,1=max(dpi−1,1,dpi−1,0+i(1−i))dpi,2=max(dpi−1,2+ai,dpi,1+i(i+1))
这个状态转移式子中 dpi,2 之所以有两个来源,就是其状态定义,在 i 之前转化结束一个来源,在 i 结束一个来源。
i 定义为这个长整型,小心溢出。
1
2
3
4
5
6
7
8
9
|
for (ll i=1;i<=N;++i) {
dp[i][0]=dp[i-1][0]+A[i];
dp[i][1]=max(dp[i-1][1],dp[i-1][0]+i*(1-i));
dp[i][2]=max(dp[i-1][2]+A[i],dp[i][1]+i*(i+1));
}
cout<<max(dp[N][0],dp[N][2])<<"\n";
|
AC代码
AC
https://codeforces.com/contest/2169/submission/360407408
源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
#include <iostream>
#include <numeric>
#include <algorithm>
#include <complex>
#include <map>
#include <ranges>
#include <cstring>
#include <string>
#include <deque>
#include <queue>
#include <vector>
#include <set>
#include <cmath>
#include <bitset>
#include <iterator>
#include <random>
#include <iomanip>
#define all(vec) vec.begin(),vec.end()
#define lson(o) (o<<1)
#define rson(o) (o<<1|1)
#define SZ(a) ((long long) a.size())
#define debug(var) cerr << #var <<":"<<var<<"\n";
#define cend cerr<<"\n-----------\n"
#define fsp(x) fixed<<setprecision(x)
using namespace std;
using ll = long long;
using ull = unsigned long long;
using DB = double;
using LD = long double;
using CD = complex<double>;
static constexpr ll MAXN = (ll)1e6+10, INF = (1ll<<61)-1;
static constexpr ll mod = 998244353;
static constexpr double eps = 1e-8;
const double pi = acos(-1.0);
ll lT;
void Solve() {
ll N;
cin >> N;
vector<ll> A(N+2);
for (int i=1;i<=N;++i) {
cin>>A[i];
}
vector<vector<ll>> dp(N+2,vector<ll>(3));
for (ll i=1;i<=N;++i) {
dp[i][0]=dp[i-1][0]+A[i];
dp[i][1]=max(dp[i-1][1],dp[i-1][0]+i*(1-i));
dp[i][2]=max(dp[i-1][2]+A[i],dp[i][1]+i*(i+1));
}
cout<<max(dp[N][0],dp[N][2])<<"\n";
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
cin >> lT;
while(lT--)
Solve();
return 0;
}
|
心路历程(WA,TLE,MLE……)