1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
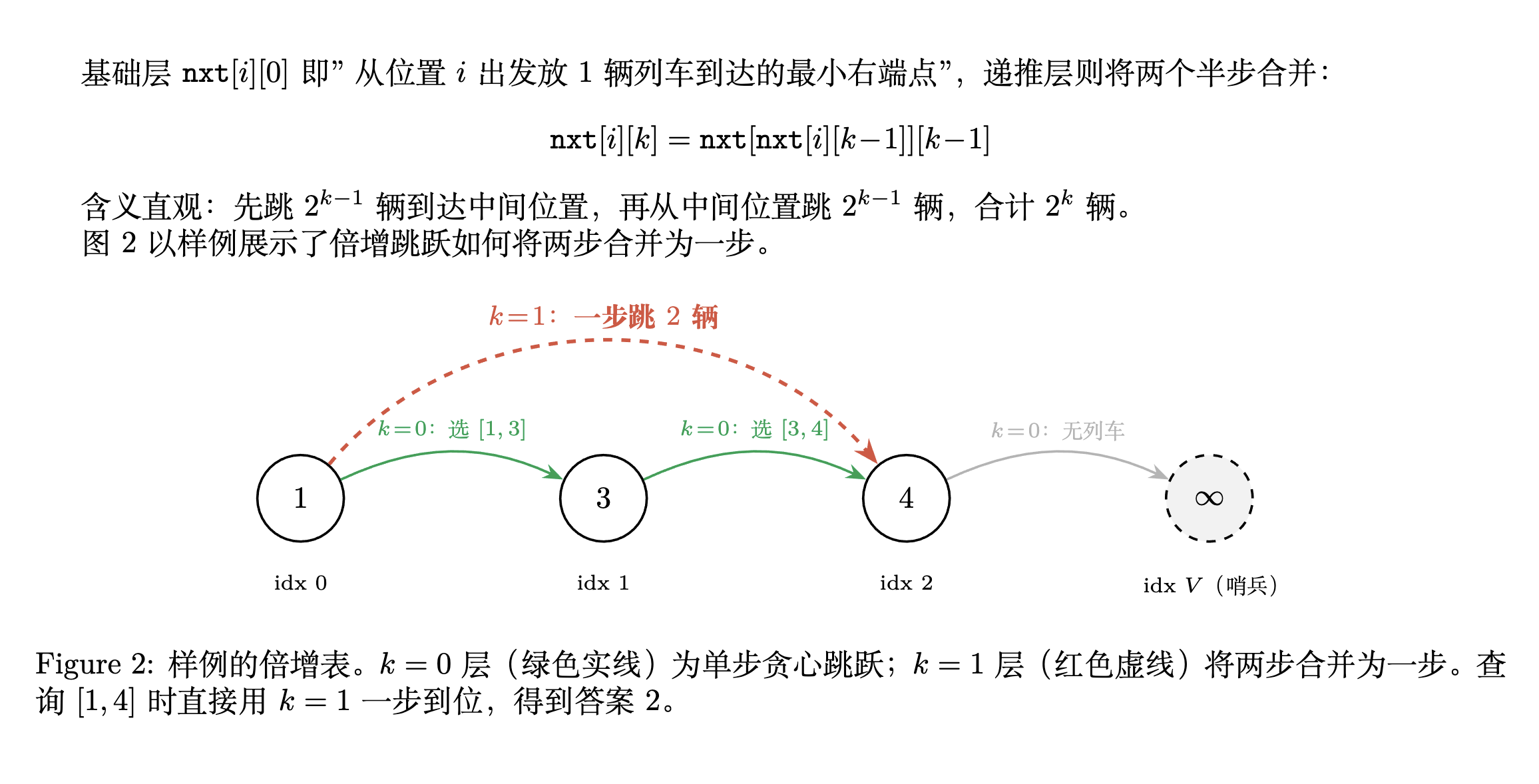
| \documentclass{article}
\usepackage{graphicx}
\usepackage{amsmath}
\usepackage{amssymb}
\usepackage{xeCJK}
\usepackage{multicol}
\usepackage{tocloft}
\usepackage{xcolor}
\usepackage{tikz}
\usetikzlibrary{decorations.pathreplacing, arrows.meta}
\usepackage[cachedir=_minted-main]{minted}
\usepackage[a4paper, left=2cm, right=2cm, top=2.5cm, bottom=2.5cm]{geometry}
\setminted{
breaklines=true,
breakanywhere=true,
fontsize=\small,
frame=single,
bgcolor=gray!5,
tabsize=2,
}
\renewcommand{\cftsecleader}{\cftdotfill{\cftdotsep}}
\usepackage[colorlinks=true, linkcolor=black, anchorcolor=black, citecolor=black, filecolor=black, menucolor=black, runcolor=black, urlcolor=blue]{hyperref}
\definecolor{seg1}{RGB}{50,120,200}
\definecolor{seg2}{RGB}{220,80,60}
\definecolor{seg3}{RGB}{0,160,80}
\definecolor{seg4}{RGB}{140,80,200}
\definecolor{highlight}{RGB}{255,160,0}
\title{\textbf{P16230 [蓝桥杯 2026 省 A] 综合应变指标} \\ 题解}
\author{}
\date{}
\begin{document}
\maketitle
\section{题意概述}
给定长度为 $N$ 的整数序列 $A$,选取三个分割点 $i, j, k$(满足 $1 \le i < j < k < N$)将序列划分为四个非空连续子段,最大化四段元素和的绝对值之和:
$$|A_1 + \cdots + A_i| + |A_{i+1} + \cdots + A_j| + |A_{j+1} + \cdots + A_k| + |A_{k+1} + \cdots + A_N|$$
\section{第一层思考:前缀和改写目标函数}
定义前缀和 $P_m = \sum_{t=1}^{m} A_t$($P_0 = 0$)。四段的元素和分别为 $P_i$、$P_j - P_i$、$P_k - P_j$、$P_N - P_k$。目标函数改写为:
$$f(i, j, k) = |P_i| + |P_j - P_i| + |P_k - P_j| + |P_N - P_k|$$
这一步把"子段求和"全部消解成了前缀和之差的绝对值,后续只需操作 $P$ 数组。
\begin{figure}[H]
\centering
\begin{tikzpicture}[scale=0.75, every node/.style={font=\small}]
\foreach \idx in {1,...,10} {
\fill[gray!12] (\idx-0.45, -0.4) rectangle (\idx+0.45, 0.4);
\draw[gray!50] (\idx-0.45, -0.4) rectangle (\idx+0.45, 0.4);
\node at (\idx, 0) {$A_{\idx}$};
}
\draw[seg1, line width=3pt] (0.45, -0.65) -- (3.55, -0.65);
\node[seg1, font=\bfseries] at (2, -1.15) {第 1 段};
\node[seg1] at (2, -1.65) {和 $= P_i$};
\draw[seg2, line width=3pt] (3.55, -0.65) -- (6.55, -0.65);
\node[seg2, font=\bfseries] at (5, -1.15) {第 2 段};
\node[seg2] at (5, -1.65) {和 $= P_j - P_i$};
\draw[seg3, line width=3pt] (6.55, -0.65) -- (8.55, -0.65);
\node[seg3, font=\bfseries] at (7.5, -1.15) {第 3 段};
\node[seg3] at (7.5, -1.65) {和 $= P_k - P_j$};
\draw[seg4, line width=3pt] (8.55, -0.65) -- (10.55, -0.65);
\node[seg4, font=\bfseries] at (9.5, -1.15) {第 4 段};
\node[seg4] at (9.5, -1.65) {和 $= P_N - P_k$};
\draw[thick, dashed] (3.55, 0.6) -- (3.55, -0.55);
\node[above] at (3.55, 0.6) {$i$};
\draw[thick, dashed] (6.55, 0.6) -- (6.55, -0.55);
\node[above] at (6.55, 0.6) {$j$};
\draw[thick, dashed] (8.55, 0.6) -- (8.55, -0.55);
\node[above] at (8.55, 0.6) {$k$};
\end{tikzpicture}
\caption{
将序列 $A$ 在分割点 $i, j, k$ 处划分为四段。每段的元素和均可用前缀和 $P$ 简洁表示。
}
\label{fig:partition}
\end{figure}
直接枚举三个分割点的时间复杂度为 $O(N^3)$,对 $N = 10^5$ 不可接受。能否把三重循环逐层拆解,每层都只做线性扫描?
\section{第二层思考:$O(N^2)$ 的朴素代码}
问题本身就是分段的,自然地逐段转移。定义四层 DP:\texttt{dp1[i]} 表示只切出第一段、该段以位置 $i$ 结尾时的最大贡献;\texttt{dp2[i]} 表示前两段的最大贡献,第二段以 $i$ 结尾;\texttt{dp3}、\texttt{dp4} 同理。答案为 \texttt{dp4[N]}。
第一层直接算:
\begin{minted}{cpp}
dp1[i] = abs(preA[i]);
\end{minted}
从 \texttt{dp1} 到 \texttt{dp2}、从 \texttt{dp2} 到 \texttt{dp3}、从 \texttt{dp3} 到 \texttt{dp4},转移结构完全一样,写成一个通用函数:
\begin{minted}{cpp}
void excute_dp(const vector<ll> &dp1, vector<ll> &dp2) {
for (int i = 1; i <= N; ++i) {
for (int j = 1; j <= i; ++j) { // ← 内层循环
dp2[i] = max(dp2[i], dp1[j] + abs(preA[i] - preA[j]));
}
}
}
\end{minted}
调用三次 \texttt{excute\_dp},每次 $O(N^2)$。瓶颈就在内层 \texttt{for(j)} 循环——能不能干掉它?
\section{第三层思考:干掉内层循环}
盯着内层循环体看:
\begin{minted}{cpp}
dp2[i] = max(dp2[i], dp1[j] + abs(preA[i] - preA[j]));
\end{minted}
\texttt{abs} 只有两种展开。代入后,把只跟 \texttt{j} 有关的项括起来:
\begin{minted}{cpp}
dp1[j] + preA[i] - preA[j] = (dp1[j] - preA[j]) + preA[i]
// ^^^^^^^^^^^^^^^^^^ ^^^^^^^^
// 只跟 j 有关 只跟 i 有关
dp1[j] + preA[j] - preA[i] = (dp1[j] + preA[j]) - preA[i]
// ^^^^^^^^^^^^^^^^^^ ^^^^^^^^
// 只跟 j 有关 只跟 i 有关
\end{minted}
所以内层循环等价于:
\begin{minted}{cpp}
dp2[i] = max(
max_over_j(dp1[j] - preA[j]) + preA[i],
max_over_j(dp1[j] + preA[j]) - preA[i]
);
\end{minted}
\texttt{max\_over\_j(dp1[j] - preA[j])} 和 \texttt{max\_over\_j(dp1[j] + preA[j])} 不依赖 \texttt{i}!而且随着 \texttt{i} 递增,\texttt{j} 的候选范围只增不减($j \le i$)。用两个变量滚动维护前缀最大值就行了,内层循环彻底消失:
\begin{minted}{cpp}
void excute_dp(const vector<ll> &from, vector<ll> &to) {
ll Mplus = -INF, Mminus = -INF;
for (int i = 1; i <= N; ++i) {
Mplus = max(Mplus, from[i] + preA[i]); // 维护 max(dp1[j]+preA[j])
Mminus = max(Mminus, from[i] - preA[i]); // 维护 max(dp1[j]-preA[j])
to[i] = max(Mminus + preA[i], Mplus - preA[i]);
}
}
\end{minted}
双重循环 $\to$ 单层循环,$O(N^2) \to O(N)$。调用三次,总计 $O(N)$。
\subsection{图像理解}
上面的优化可以用图~\ref{fig:v-shape} 直观看懂。
对每个候选 \texttt{j},\texttt{dp1[j] + abs(preA[i] - preA[j])} 是关于 \texttt{preA[i]} 的一条 V 形曲线——谷底在 \texttt{preA[j]},谷底高 \texttt{dp1[j]},两臂斜率 $\pm 1$。内层循环就是对所有 V 形取最大值(上包络)。
关键:所有 V 形的斜率全一样($\pm 1$),不同的只是截距。同斜率的平行线取最大值,只有截距最大的一条存活。所以上包络只由两条直线决定——截距就是代码里的 \texttt{Mminus} 和 \texttt{Mplus}。
\texttt{i} 每递增一步,候选集多出一条新 V 形。新 V 形的截距和当前 \texttt{Mminus}、\texttt{Mplus} 取一次 \texttt{max} 就完成更新——这就是循环体里那两行 \texttt{max} 在干的事。
\begin{figure}[H]
\centering
\begin{tikzpicture}[scale=0.85, every node/.style={font=\small}]
\begin{scope}
\clip (-0.5, -0.5) rectangle (8.2, 7.5);
\draw[gray!40, line width=0.5pt, densely dashed] (0, 4) -- (2, 2);
\draw[gray!40, line width=0.5pt, densely dashed] (0, 5.5) -- (4, 1.5) -- (7.5, 5);
\draw[gray!40, line width=0.5pt, densely dashed] (6, 1) -- (8, 3);
\draw[seg1, line width=2.5pt] (2, 2) -- (7.5, 7.5);
\draw[seg3, line width=2.5pt] (0, 7) -- (6, 1);
\draw[highlight, line width=3.5pt, opacity=0.45] (0, 7) -- (3.5, 3.5) -- (7.5, 7.5);
\end{scope}
\fill[seg1] (2, 2) circle (3pt);
\fill[seg2] (4, 1.5) circle (3pt);
\fill[seg3] (6, 1) circle (3pt);
\fill[highlight!80!black] (3.5, 3.5) circle (3pt);
\draw[seg1!40, densely dotted, thin] (0, 2) -- (2, 2);
\draw[seg2!40, densely dotted, thin] (0, 1.5) -- (4, 1.5);
\draw[seg3!40, densely dotted, thin] (0, 1) -- (6, 1);
\draw[-stealth, thick] (-0.5, 0) -- (8.2, 0) node[right] {\texttt{preA[i]}};
\draw[-stealth, thick] (0, -0.5) -- (0, 7.8);
\foreach \x/\col/\lab in {2/seg1/1, 4/seg2/2, 6/seg3/3} {
\draw[\col] (\x, -0.08) -- (\x, 0.08);
\node[\col, below, font=\footnotesize] at (\x, -0.2) {\texttt{preA[$j_\lab$]}};
}
\node[seg1, left, font=\footnotesize] at (-0.15, 2) {\texttt{dp1[$j_1$]}};
\node[seg2, left, font=\footnotesize] at (-0.15, 1.5) {\texttt{dp1[$j_2$]}};
\node[seg3, left, font=\footnotesize] at (-0.15, 1) {\texttt{dp1[$j_3$]}};
\draw[-stealth, seg1!80!black, thick] (7.2, 5.5) -- (6.2, 6.2);
\node[seg1!80!black, font=\footnotesize, align=left, right] at (7.2, 5.0)
{斜率 $+1$ 冠军\\[-1pt] 截距 $=$ \texttt{Mminus}};
\draw[-stealth, seg3!80!black, thick] (0.6, 7.5) -- (1.2, 5.8);
\node[seg3!80!black, font=\footnotesize, align=left, right] at (0.6, 7.7)
{斜率 $-1$ 冠军,截距 $=$ \texttt{Mplus}};
\draw[gray!40, line width=0.5pt, densely dashed] (4.5, -1.2) -- (5.3, -1.2);
\node[gray!60, font=\footnotesize, right] at (5.4, -1.2) {被淘汰的臂};
\draw[highlight, line width=3pt, opacity=0.45] (4.5, -1.7) -- (5.3, -1.7);
\node[highlight!80!black, font=\footnotesize, right] at (5.4, -1.7) {上包络 $=$ \texttt{dp2[i]}};
\end{tikzpicture}
\caption{
每个候选 \texttt{j} 产生一条 V 形(谷底高 \texttt{dp1[j]},位于 \texttt{preA[j]})。所有 V 形斜率一样($\pm 1$),上包络只由截距最大的两条臂决定——截距就是代码里的 \texttt{Mminus} 和 \texttt{Mplus}。其余臂(灰色虚线)全被淘汰。
}
\label{fig:v-shape}
\end{figure}
\section{代码实现}
\begin{minted}{cpp}
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
static constexpr ll INF = (1ll << 61) - 1;
struct Solve {
ll N;
vector<ll> A, preA;
vector<ll> dp1, dp2, dp3, dp4;
// 核心:优化后的转移,O(N)
void excute_dp(const vector<ll> &from, vector<ll> &to) {
ll Mplus = -INF, Mminus = -INF;
for (int i = 1; i <= N; ++i) {
Mplus = max(Mplus, from[i] + preA[i]);
Mminus = max(Mminus, from[i] - preA[i]);
to[i] = max(Mminus + preA[i], Mplus - preA[i]);
}
}
Solve() {
cin >> N;
A.resize(N + 2);
for (int i = 1; i <= N; ++i)
cin >> A[i];
preA.resize(N + 2);
partial_sum(A.begin(), A.end(), preA.begin());
dp1.resize(N + 2, -INF);
for (int i = 1; i <= N; ++i)
dp1[i] = abs(preA[i]);
dp2.resize(N + 2, -INF);
dp3.resize(N + 2, -INF);
dp4.resize(N + 2, -INF);
excute_dp(dp1, dp2);
excute_dp(dp2, dp3);
excute_dp(dp3, dp4);
cout << dp4[N] << "\n";
}
};
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
Solve solve;
return 0;
}
\end{minted}
\section{复杂度分析}
\begin{itemize}
\item \textbf{时间复杂度}:$O(N)$。\texttt{excute\_dp} 单次 $O(N)$,调用三次,总计 $O(N)$。
\item \textbf{空间复杂度}:$O(N)$。四个 DP 数组加前缀和数组。
\end{itemize}
\end{document}
|