思路讲解
树状数组+二分
你可以理解为用树状数组的区间加减加速模拟法(模拟法最大的瓶颈不就是区间加减吗?)
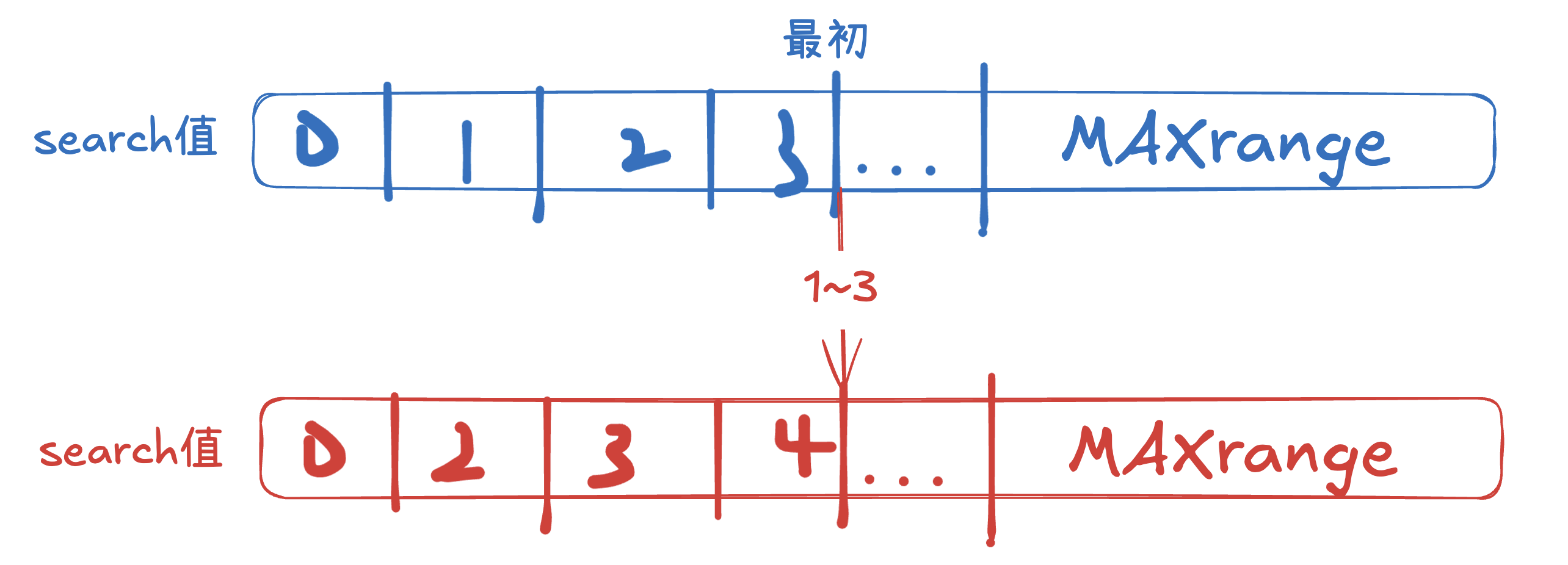
然后分数是只增不减的,初始分数比别人低,经过N次比赛后也不会比别人高
所以我们就能够用二分法找到区间的L,和R
1 | inline ll findl(ll x){ |
AC代码
AC
https://atcoder.jp/contests/abc389/submissions/61877078
1 |
|
心路历程(WA,TLE,MLE……)
提交了好多次RE,发现可能是C++23不支持宏定义了
树状数组+二分
你可以理解为用树状数组的区间加减加速模拟法(模拟法最大的瓶颈不就是区间加减吗?)
然后分数是只增不减的,初始分数比别人低,经过N次比赛后也不会比别人高
所以我们就能够用二分法找到区间的L,和R
1 | inline ll findl(ll x){ |
AC
https://atcoder.jp/contests/abc389/submissions/61877078
1 |
|
提交了好多次RE,发现可能是C++23不支持宏定义了
1 |
|
购买第 i 种产品的第 j 个花费是
那不难发现,我们有一个贪心策略,就是优先买便宜的东西,再买贵的东西。
当然,直接这样搞的话,肯定TLE,我们需要找一个价格阈值x,小于x的东西我们买,大于x的东西我们就不买了,最后看总花费是否 ≤ M
https://www.luogu.com.cn/article/imo508fb 然后你会发现WA了两个点,
hack数据:
1 | 2 25 |
同样起始价格为1,有时要买3个,有时要买4个,那怎么解决?
加了下面的小根堆就万无一失了,因为我们将刚刚超过价格阈值的全部记录下来,再跑一遍看看有没有遗失的。
1 | // 下面就是把check(l)的过程再跑了一遍,只不过加了小根堆 |
AC https://atcoder.jp/contests/abc389/submissions/61888808
1 |
|
参考题解
https://ac.nowcoder.com/discuss/1452143
1 | // 以陪第i只猪猪为结束需要多少消耗 |
直接记忆化会导致TLE,所以我进行了一些小小的优化,具体见图
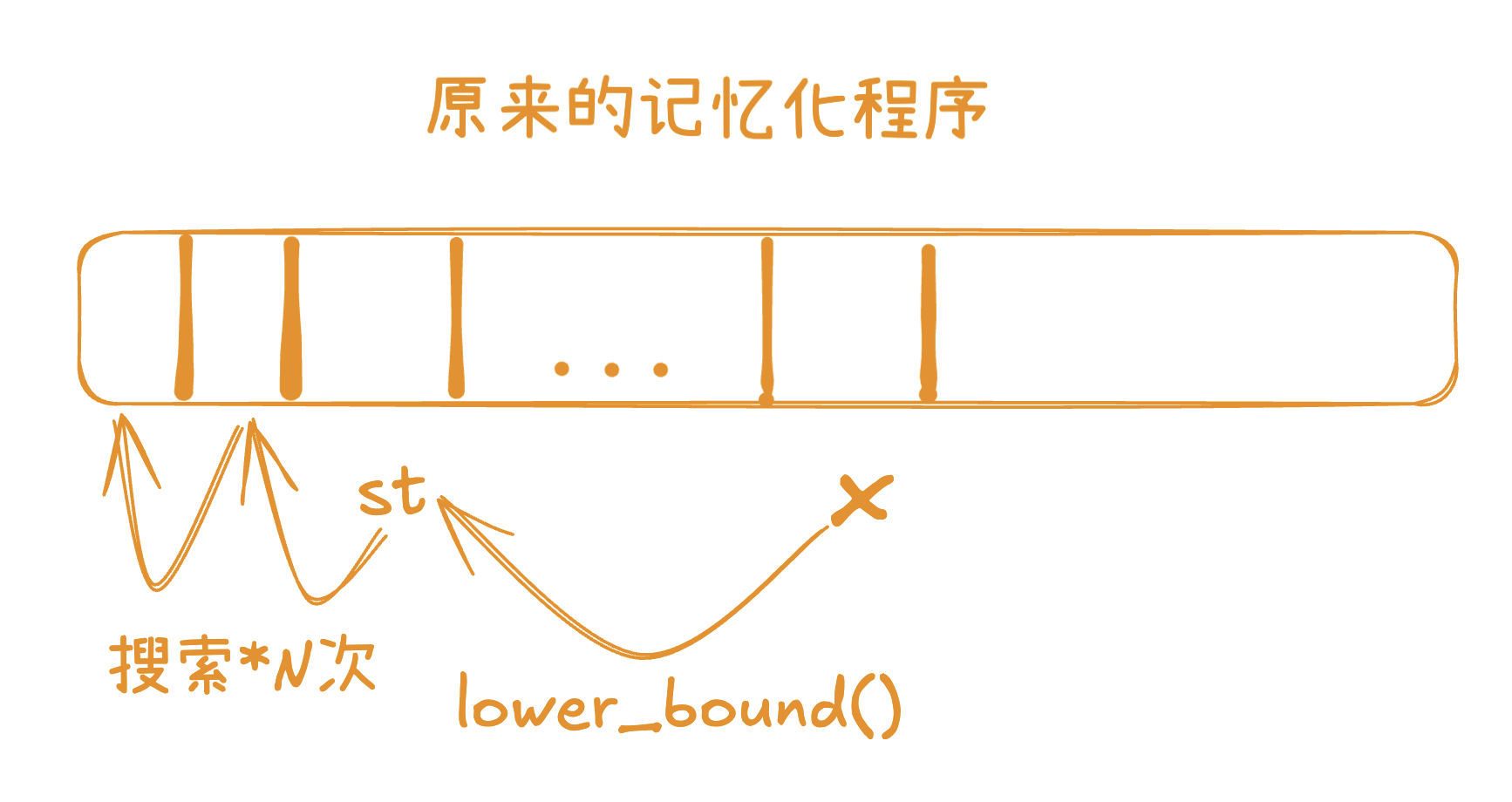
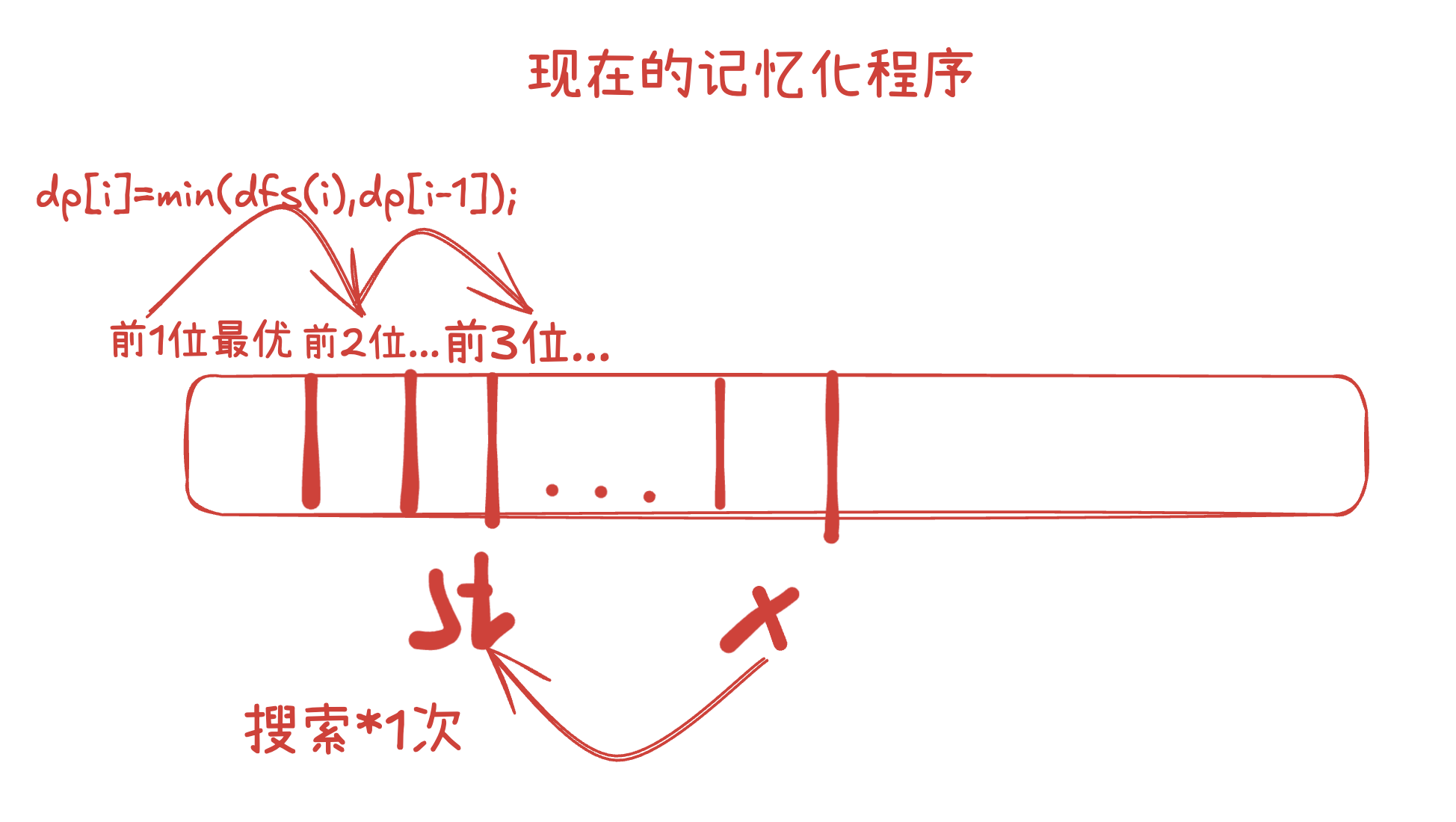
当然,改动之后dp里装的就是以前1~i位为末尾的最优的情况(最少的消耗)。
1 | for(int i=1;i<=N;++i){ |
所以这个程序其实是个伪装成记忆化搜索的递推!
那为什么不直接写递推那?还不是不太直接想的出来。。。
AC
https://ac.nowcoder.com/acm/contest/view-submission?submissionId=74795179
1 |
|
直接记忆化会喜提TLE
https://ac.nowcoder.com/acm/contest/view-submission?submissionId=74794988

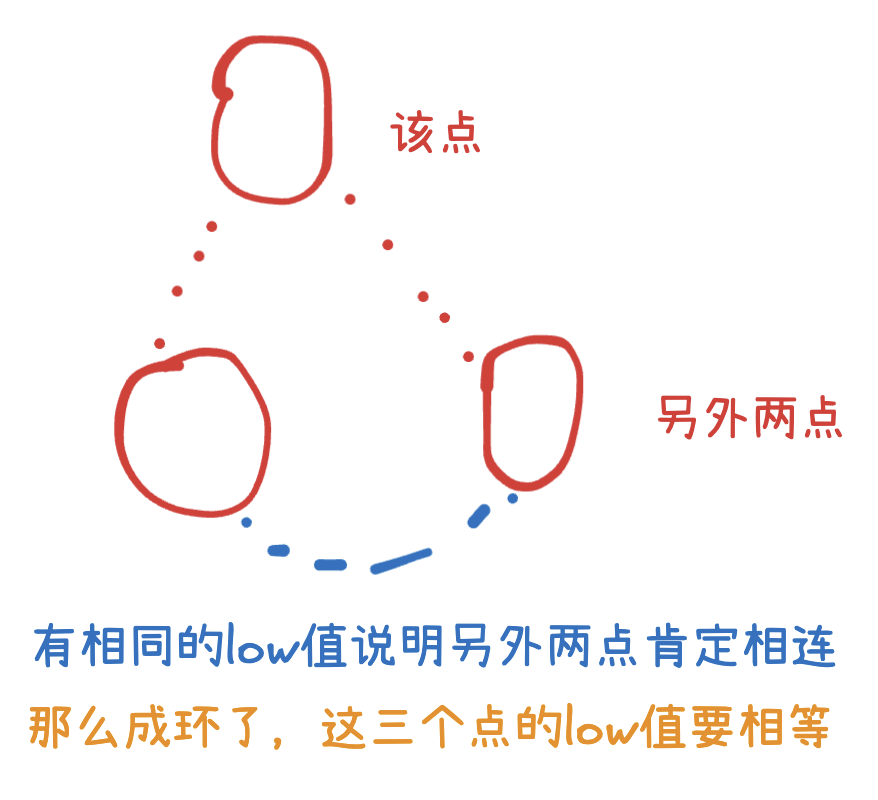
low值相同的点我们可以进行缩点,看成是一个点。
为什么可以这样统计缩点的入度,不会有两个low值相同的点与该点相连嘛?
1 | ll tarjan(){ |
显然不可能,有两个low值相同的点与该点相连,那么该点必然与这些点都有共同的low值
AC
https://www.luogu.com.cn/record/198957305
1 |
|
题解讲的云里雾里的,有的时候还是得看书,黑书牛逼!