1009线段染色
https://acm.hdu.edu.cn/contest/problem?cid=1174&pid=1009
https://vjudge.net/problem/HDU-8011
又是沟槽的概率题目。
感觉不是我能碰瓷的题目,之后有兴趣了再来看吧。
https://grok.com/chat/dc6a06d2-50d6-4bb8-a88b-87a1c553307d
1 |
|
题目大意
题意简述
在一个长度为 的数轴上(包含整点 ),给出了 条线段,第 条线段覆盖区间 。
针对数轴上的每个整点 ,进行一次独立的染色操作,染色的成功率为 。
定义一条线段被染色,当且仅当该线段覆盖的整点中至少有一个被染色。
求所有给定的 条线段都被染色的概率。
输入格式
第一行包含一个整数 ,表示测试数据组数。
对于每组数据:
-
第一行两个整数 ,分别表示数轴长度和线段数量。
-
第二行 个整数 ,表示每个点的染色概率参数()。
-
接下来 行,每行两个整数 ,表示一条线段的左右端点。
输出格式
输出一个整数,表示概率对 取模后的结果。
数据范围
样例
1 | 6 |
样例输出
1 | 625000005 |
样例解释
第一组数据:
-
,所有点染色概率均为 。
-
线段为 和 。
-
要使两条线段都被染色,需满足:(点2被染 或 点3被染) 且 (点3被染 或 点4被染)。
-
情况分类:
- 点3被染(概率 ):此时两条线段都已满足条件。
- 点3未被染(概率 ):此时必须点2被染(概率 )且点4被染(概率 ),概率为 。
-
总概率 。
-
。
第二组数据:
-
线段为 和 。
-
线段1仅包含点2,必须点2被染(概率 )。
-
线段2包含点3, 4,需至少一个被染,概率为 。
-
两者独立,总概率 。
思路讲解
我们重新回来看这道题目啊,重新回来看一下这道题目。
这是一个很好的问题,我来认真分析一下。
直接回答:对这道题来说,很难再靠更强的数据结构降低思维难度了
原因是:这道题的思维瓶颈在 DP 的建模,而不在 DP 的优化。数据结构能帮你优化已有的转移(比如把 变成 ),但不能替代"发现 DP 怎么定义"这一步。
为什么?来看这道题的思维结构
这道题的核心洞察只有一个:
枚举"上一个被染色的位置 ",那么 之间不能完整包含任何线段。
一旦有了这个洞察,就能定义:
其中 ,是所有右端点在 左边的线段中,最大的左端点。
关键: 天然单调不减(随着 增大,参与取 的线段只多不少),所以转移的求和下界单调右移——这是一个滑动窗口。
数据结构(线段树/BIT)的作用是:如果你没注意到"前缀积可以提出来、然后滑动窗口"这件事,你可以用线段树做"区间乘 + 单点插入 + 区间求和"来暴力维护转移,省去这一步推导。
但"枚举上一个染色位置"这一步,没有任何数据结构能替你想。这就像斜率优化 DP 里——你可以用李超线段树替代手动维护凸包(降低了"维护凸包"的思维),但"发现 DP 具有斜率优化结构"这一步,李超树帮不了你。
其实这道题比你想的简单:不需要线段树
这道题甚至不需要线段树。令 ,代入得:
单调不减,所以 就是一个滑动窗口求和,双指针维护即可。
整个算法:
- 对每个线段 ,标记
bestL[r] = max(bestL[r], l)。 - 扫一遍算出 。
- 滑动窗口跑 DP。
- 答案 = 。
时间复杂度 ,不需要任何复杂数据结构。
唯一需要特判的是 (即 ,点 必然被染色)的情况——此时前缀积为零,不能除。解决方式是在这些点处"重置"前缀积的基准。
什么时候"更强数据结构"真的能降低思维?
你说的这种思想确实有适用的场景,比如:
| 场景 | “聪明做法”(思维重) | “数据结构做法”(思维轻) |
|---|---|---|
| 斜率优化 DP | 手维护凸包 + 单调性分析 | 李超线段树直接维护 |
| 树上路径问题 | 点分治 / 各种分讨 | LCT / 树链剖分 |
| 区间历史操作 | 复杂的势能分析 | 吉司机线段树(Segment Tree Beats) |
| 带修 DP | 重新推导转移 | 线段树维护转移矩阵(动态 DP) |
| 但这些场景的共同点是:瓶颈在"优化/维护"而非"建模"。如果一道题的瓶颈在于"如何定义状态和转移",那数据结构是无能为力的。 | ||
| 本题恰好属于后者。 |
如果这道题加了修改操作……
如果题目变成"每次修改一个 ,查询当前的概率",那就可以用动态 DP(线段树维护转移矩阵)来做——这确实是"更厉害的数据结构技巧"。但原题没有修改,所以用不上。
总结:你的直觉(用强数据结构换思维难度)是对的策略,但这道题的瓶颈不在数据结构能解决的层面。好消息是,一旦你掌握了"枚举上一个染色位置 + 单调 → 滑动窗口"这个 pattern,以后类似的一维覆盖概率题都可以秒。这是经验/模板的力量,比数据结构更靠谱。
好,我给你几层递进的提示,你自己想到哪一层算哪一层。
提示一(最基本的观察)
如果你把所有被染色的点从左到右排成一列 ,那么"所有线段都被满足"这个条件,本质上是在约束相邻染色点之间的空隙。想想看:两个相邻染色点 和 之间的"空白区域" 不能怎么样?
提示二(DP 状态)
如果你意识到了"空隙不能完整包含任何线段",那么自然可以设计 DP:从左到右枚举"下一个被染色的点 ",上一个被染色的点是 。转移的合法性只取决于 的值—— 必须 某个下界。这个下界是什么?它跟哪些线段有关?
提示三(下界的单调性)
定义 为"所有右端点严格小于 的线段中,左端点的最大值"。想一想:为什么 关于 是单调不减的?这个单调性意味着什么?
提示四(优化方向)
如果你已经写出了转移式:
现在的问题是怎么快速算这个求和。你有两条路:
- 路线 A(数据结构):观察一下,当 递增到 时,已有的每个 项会发生什么变化?只是被乘上了一个 。所以你需要一个支持区间乘、单点修改、区间求和的数据结构。
- 路线 B(代数化简):试试令 ,代入转移式看看会发生什么。结合 的单调性,你会发现一个非常简洁的结构。
提示五(特殊情况)
如果某个点 满足 (即 ,必然被染色),你的"除以前缀积"会出问题。想想这种点在物理意义上意味着什么,以及它如何把问题切成独立的段。
这 AI 提示二搁这乱写的,这数轴上的每一个点都是染色点,哪来的不染色点啊?那属于搞笑来了,卧槽。
你先别急,我觉得这里可能有个术语上的误解,我重新把关键点说清楚。
题目说的是:“整点 被染色的成功率为 ”。也就是说,每个点进行染色操作后,有两种结果:
- 染色成功(概率 )
- 染色失败(概率 )
比如样例六,,第四个点 ,意味着 ,第四个点必定染色失败。而线段 要求第四个点染色成功,所以答案为 。
所以 个点中,并非每个点都会染色成功。最终染色成功的点是一个随机子集。我之前说的"染色点"指的就是"染色成功的点",表述上确实不够清晰,这里道歉。
重新用明确的语言给提示:
提示一
考虑最终的随机结果: 个点中,有些染色成功,有些染色失败。把所有染色成功的点从左到右记为 。那么"所有线段都被满足"等价于:每条线段 内至少包含一个染色成功的点。
反过来想:如果两个相邻的染色成功点 和 之间有一段空白 ,这段空白里的点全部染色失败。如果某条线段完整地落在这个空白里,那它就没有任何染色成功的点——这条线段就不满足条件。
提示二
基于提示一,可以设计 DP:设 表示"位置 染色成功,且所有右端点 的线段都被满足"的概率贡献。转移时枚举上一个染色成功的位置 ,中间 全部染色失败。
提示三
转移的合法条件: 这段空白里不能完整包含任何线段。定义:
即"右端点在 左边的线段中,左端点最大的那个"。那么 必须满足 。
是单调不减的——想想为什么。
提示四
写出转移式后,观察求和的结构。 单调不减意味着求和的左界在右移,这是一个滑动窗口。结合前缀积的技巧,可以做到 。或者用线段树维护"区间乘 + 区间求和"做到 ,不需要想前缀积除法的细节。
OK,我大概看懂了这个 AI 提示3了。这 AI 提示2属于是哈哈哈省略的有些过多了。啊,如果你要看 AI 提示的话,可以直接看这个 AI 提示3。嗯。

应该是如上图这个意思啊,我们先尝试一下能不能实现一下。因为这个转移合法性是具有单调性的。就是说,如果说这个 LR 不符合要求的话,那么更小的 L 是更加不可能符合要求的。那么这个还是非常容易就可以找到的。
啊,然后你按照这个思路写了一个 DP 程序以后,现在问题就是答案到底是什么?我们会发现答案不是 DP[N] 啊,答案不是 DP[N] 那怎么答案从何而来?答案是什么?现在的问题是这个。
你的代码有三个问题,核心都是同一件事的不同表现。
我们最大的问题是少考虑了虚拟起点0。说白了,它可以从 0 转移过来。还有一个地方就是它转移过来的中间那一段,它不能够被染色。
问题一:转移少乘了一坨东西
你写的转移是:
1 | dp[i] = p_i × Σ dp[j] (j 从 F(i) 到 i-1) |
但正确的转移是:
那个 是什么意思? 说的是" 是上一个染色成功的点",那 这些点就必须全部染色失败,概率是 。你把这个因子整个漏了。(我给 AI 的这个式子加了个括号,避免你理解错了。)
拿样例一来说,,全部 ,线段 和 :
- 你的代码算 ,
- 正确的是
差别就在于 这项:从虚拟起点 到位置 ,中间位置 必须染色失败,要乘 。
问题二:没有虚拟起点
位置 可以是第一个染色成功的点,前面全部失败。这对应从一个虚拟的位置 转移过来,。你的二分从l=1开始,完全没考虑 这种情况。
问题三:答案不是
最右边的染色成功点不一定是 。比如 ,可能点 染色成功、点 染色失败,只要所有线段都被覆盖了就行。正确答案是:
就是枚举"最右边的染色成功点是谁",后面的点全部失败。
这三个问题本质是一回事:你的 DP 把"中间点必须染色失败"这个概率因子完全忽略了。一旦补上这个因子,BIT 里就不能直接存 了(因为 依赖于查询时的 ),所以要么改存 ,要么换成带懒标记的线段树做区间乘。这就是为什么改动面积不可避免地大。
我们最大的问题是少考虑了虚拟起点0。说白了,它可以从 0 转移过来。还有一个地方就是它转移过来的中间那一段,它不能够被染色。因此需要乘上一个不被染色因数。说白了就是计算一下中间那一段它的这个乘积嘛。
后面的这一坨乘积其实不好求啊,不是很好求,因为对于每一个 DP【 j 】来说,它的这个乘积的项数是不一样的。哎,不过我们可以采用类似于维护区间和区间修改的树状数组一样。这个可能说的有点抽象。
我们使用 iPad 画图来说明一下我们的这个意思。
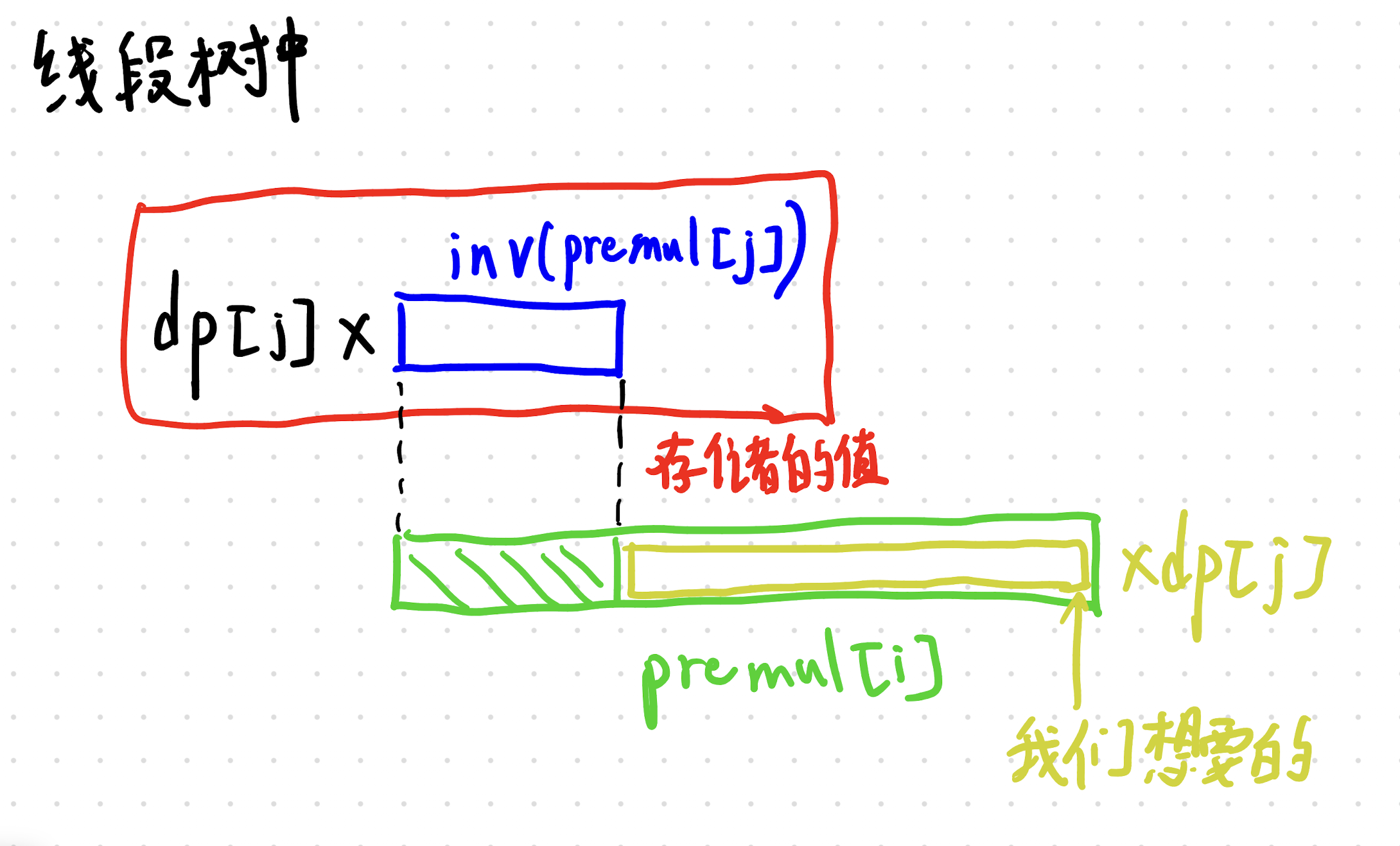
说白了就是在线段树中的 j 存储不同的逆元值,存储的 DP j 乘以不同的逆元值,进而得到乘以相同的值,达到乘以不同值的这个效果。觉得我这个图还是画的比较清楚的。
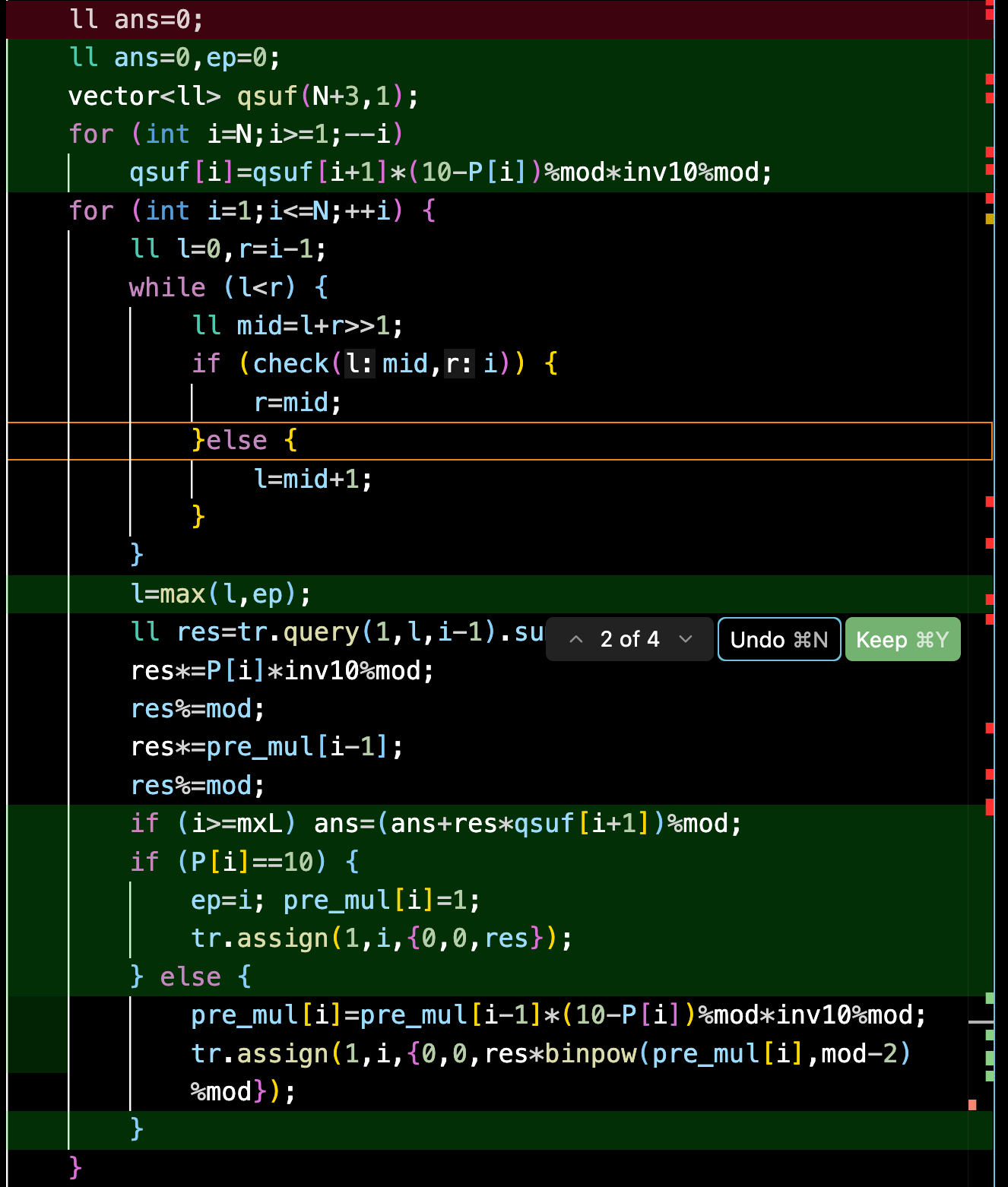
1 | vector<ll> pre_mul(N+2,1); |
AC 代码
AC
https://acm.hdu.edu.cn/contest/view-code?cid=1174&rid=28065
https://vjudge.net/solution/67894251
1 | /** |