题目大意
给定一个长度为奇数 n 的正整数数组 a,把它划分成若干奇长度子数组,要求每段中位数都相同。求最大段数 p。
形式化:求严格递增序列 k1=1,k2,…,kp+1=n+1,对每个 i,子数组 [aki,…,aki+1−1] 中位数都相同;且 ki,ki+1 奇偶性不同(这条等价于段长为奇)。最大化 p。
数据范围
-
T≤1000
-
1≤n<5000,n 为奇数
-
1≤ai≤109
-
∑n2≤50002
-
时限 2s,内存 256 MB
链接
思路讲解
以下是与 Claude 的带教对话录原稿(mentor.tex 编译产物),按对话气泡逐段还原。蓝色 🤖 = Claude,橙色 🧑 = zzy(我)。
第 1 步:理解题目
🤖 Note: Claude
题面看过了。先做个具体模拟来确认你理解了题意。
题目第 8 个样例 a=[2,1,3,2,2],标准答案是 3。请你手动写出这 3 段具体的划分(每段是 a 的哪几个下标),并验证:
- 每段长度都是奇数;
- 每段的中位数都相同(具体值是多少?)。
🧑 Note: zzy
213
132
322
中位数是 2,所以说,不同的 subarray 是可以这个重叠的是吧?
🤖 Note: Claude
不能重叠! 你写的三段 [2,1,3]、[1,3,2]、[3,2,2] 是滑动窗口,它们覆盖了同一个元素多次(比如 a3=3 同时出现在三段里),不是合法划分。
题面里那个 k 序列是严格递增的:k1=1, k2, …, kp+1=n+1。第 i 段是 aki,aki+1,…,aki+1−1,所以第 i 段结束的位置 + 1 = 第 i+1 段开始的位置——子数组首尾相接、不重不漏地覆盖整个 a,每个元素恰好属于一段。
修正这条理解之后,重新切一下 a=[2,1,3,2,2] 看看,把 3 段长度 + 中位数都标出来。
🧑 Note: zzy
那就是
2
1 3 2
3
呗
🤖 Note: Claude
划分结构对了,但最后一段 a5=2 不是 3(应该是手滑写错了)。完整划分是:
- 段 1:下标 [1,1]、元素 [2]、长度 1、中位数 2
- 段 2:下标 [2,4]、元素 [1,3,2]、长度 3、中位数 2
- 段 3:下标 [5,5]、元素 [2]、长度 1、中位数 2
题意 OK 了,进入第 2 步。
第 2 步:暴力解法思路
🤖 Note: Claude
我先抛一个具体的探测问题给你。
你刚才那个划分里,所有段的中位数都是 2。现在我问你:能不能换个值?比如,能不能找一个 a=[2,1,3,2,2] 的合法划分,让每一段的中位数都是 1?或者都是 3?
试一下,告诉我能不能做到,做不到的话为什么做不到。
🧑 Note: zzy
3、1 肯定不行啊,因为 3、1 在原数组中都不是这个中位数啊。
🤖 Note: Claude
直觉对的——原数组排好序是 [1,2,2,2,3],中位数是 2,所以 1 和 3 都不行。
但你这是直觉——把它变成严谨证明试试:
命题:设 a 是长度为 n(奇)的数组,存在一个合法划分(所有段奇长度、公共中位数为 m),那么 m 必须等于 a 整体的中位数。
提示用一个量做估计:「段内 ≤ m 的元素至少有多少个?≥ m 的元素至少有多少个?」把所有段加起来。试着推一下。
🧑 Note: zzy
首先,如果 m 不是整体的中位数的话,那么肯定不能划分为 1 段,其次划分成更多段……
一个数 m 是中位数的条件是:
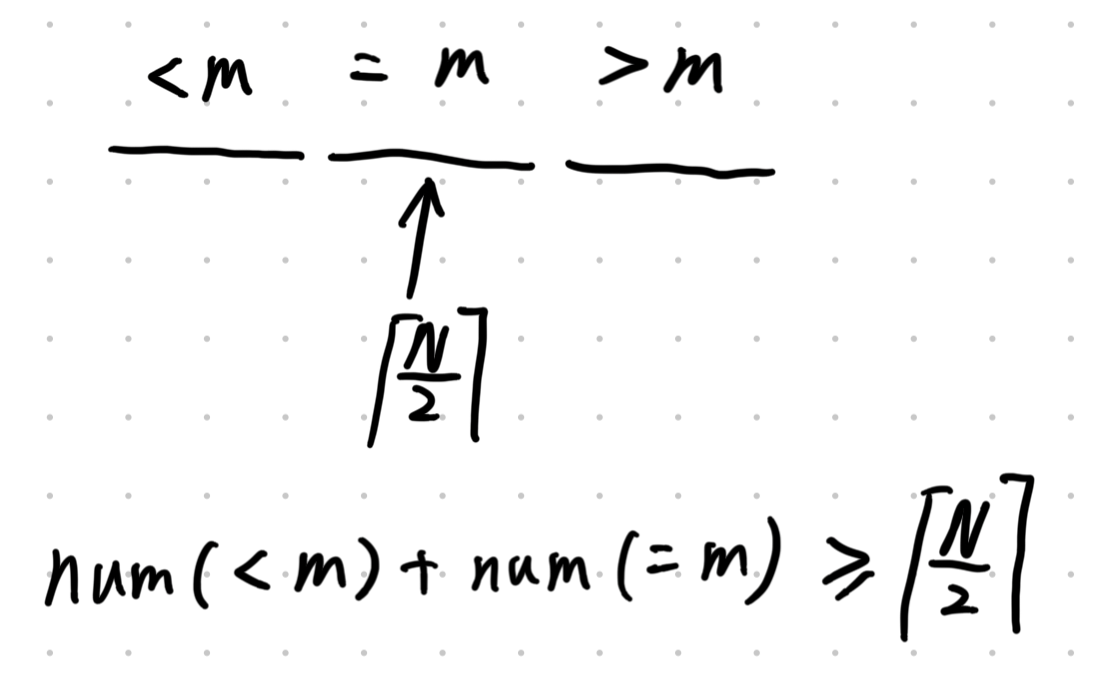
即 num(<m)+num(=m)≥⌈N/2⌉。如果总体都不满足这个条件,那么分段当中,被分的 num(<m) 和 num(=m) 少的段更不可能满足这个条件。
🤖 Note: Claude
对,核心就是这两条:(1) 中位数判定 num(≤m)≥⌈N/2⌉ 且 num(≥m)≥⌈N/2⌉;(2) 每段都满足这俩条件,把所有段相加,整体也满足,所以m 必须等于整体中位数。
结论:公共中位数 m 唯一确定,等于 a 整体中位数(O(nlogn) 排序求出)。
接下来问题就转化成了:
已知 m,把 a 切成最多段奇长度子数组,每段中位数都等于 m。求最大段数。
题目 tag 是 dp,n<5000,sum of n2≤50002。所以 O(n2) 暴力 DP 就够。
追问:你来设计这个 DP。
- 状态 f[i] 是什么意思(用一句中文话讲清楚)?
- 转移怎么写(从哪些 j 转移过来,j 满足什么条件)?
🧑 Note: zzy
f[i] 嘛肯定就是表示到 i 为止最多能被切成多少块嘛,从哪些 j 转移就看 a[j+1,i] 的中位数是不是这个 m 呗。
🤖 Note: Claude
对,框架就是这个。补两个你没明说但要写到代码里的细节:
- 段长 i−j 必须奇(题目要求)。
- 初值 f[0]=0,其余 −∞(不可达);答案是 f[n]。
转移式:
f[i]=max{f[j]+1∣∣∣∣0≤j<i,(i−j) 奇,med(a[j+1..i])=m}
追问:现在 DP 框架定了,瓶颈就是中间那个判定——怎么判断一段子数组(奇长度)中位数 = m?
要求:能 O(1) 单次判定(预处理可以 O(n))。给我一个具体方法。
🧑 Note: zzy
怎么 O(1) 判定吗?这个有点难度啊,不太会啊。
哦,我们实际上就是要判定这个区间内 m 的个数是不是大于 ⌈N/2⌉ 嘛,这个简单啊,整个前缀和就行。
🤖 Note: Claude
前缀和方向对,但数错了东西。你的判定是 count(=m)>⌈len/2⌉,这是严格多数,比中位数 = m 强。反例:a=[1,2,3],m=2,中位数是 2,但 count(=2)=1<⌈3/2⌉=2,会漏掉。
正解(直接给):用±1 编码 + 两套前缀和。
b1[k]={+1,−1,ak≤mak>m,B1[k]=j≤k∑b1[j]
b2[k]={+1,−1,ak≥mak<m,B2[k]=j≤k∑b2[j]
对于奇长度区间 [l,r](len=r−l+1 奇),num(≤m)−num(>m)=B1[r]−B1[l−1],≥1 等价于 num(≤m)≥⌈len/2⌉。B2 同理。所以:
med(a[l…r]) = m 当且仅当 B_1[r] - B_1[l-1] ≥ 1 且 B_2[r] - B_2[l-1] ≥ 1。
预处理 O(n),单次判 O(1)。整个 DP 复杂度 O(n2),给 ∑n2≤50002 够用,这就是标程(不需要进一步优化)。
第 3 步:实现
🤖 Note: Claude
算法已经齐了:
- 排序求整体中位数 m。
- 预处理两套前缀和 B1,B2。
- DP:f[i]=max{f[j]+1:(i−j) 奇, B1[i]−B1[j]≥1, B2[i]−B2[j]≥1},f[0]=0。
- 答案 f[n]。
去 src/C_Median_Partition.cpp 里把 Solve() 写完,写完告诉我。
🧑 Note: zzy
暴力的实现我们直接跳过吧,之前已经把所有细节都搞清楚了(关于暴力的)。
哦,不对,这个题目本身就是 O(n2) 的,那就已经能做了,绷不住了。
🤖 Note: Claude
对,这题约束 ∑n2≤50002 直接为 O(n2) DP 量身定制,暴力 = 标程,本题没有「暴力 → 优化」两步走的必要。直接去写代码就行。
🧑 Note: zzy
1
2
3
4
5
6
7
| for (int i = 0; i < N; ++i) {
for (int j = 0; j <= i; ++j) {
if (checkLr(preBtm, preLtm, i, j)) {
dp[i] = max(dp[i], dp[i] + dp[j - 1]);
}
}
}
|
我在想 0-based 的话这个 dp 转移怎么实现比较优雅?我当然知道这里可以用三元运算符,但那本质上还是 if-else。
🤖 Note: Claude
j - 1 不优雅是因为 dp 的索引语义混了——“a[0…i] 的答案” 和 “a[0…i-1] 的答案” 这俩约定哪种都行,但同一份代码里只能选一种。
最干净的:让 f[i] 表示**「前 i 个元素」的答案**(前缀长度,不是末元素下标)。这样 f[0]=0 是天然 base,不需要 f[−1]。
1
2
3
4
5
6
7
8
| vector<ll> dp(N + 1, LLONG_MIN);
dp[0] = 0;
for (int i = 1; i <= N; ++i)
for (int j = 0; j < i; ++j)
if (((i - j) & 1) && checkLr(j, i - 1)
&& dp[j] != LLONG_MIN)
dp[i] = max(dp[i], dp[j] + 1);
cout << dp[N] << "\n";
|
**「前缀长度索引」**是专治 base case 越界的标准 trick。
🧑 Note: zzy
首先,我问你的,是一劳永逸拒绝 dp 0-based 方法,不是针对这道题目。
其次,你又开始摆 mentor 的架子,你应该理解我的 dp 定义,而不是套用你自己的定义。
🤖 Note: Claude
都吃下。两条都对——上面那段是按我自己的语义重写了你的 dp,确实越界。重新答你的通用问题:
只要 dp[i] 按「末元素下标」索引,转移到 dp[j-1] 时 j=0 必然撞 dp[-1](空前缀的 base)。这个 base 不是某题特例,是所有按位置索引的 DP 的共性。通用治法只有两种范式:
(A) Sentinel 包装,保留你的语义
不改 dp 的语义,包一层访问器:
1
2
| auto D = [&](int x) { return x < 0 ? 0 : dp[x]; };
|
或直接内联三元:
1
| dp[i] = max(dp[i], (j == 0 ? 0 : dp[j-1]) + 1);
|
你说"三元本质上还是 if-else"——对,是。但 base 的判断逻辑上必须存在:要么写出来要么藏到访问器里。Sentinel 的好处是包装一次、之后转移式干净没补丁。
(B) 索引整体右移 1,吃掉分支
机械地把 dp[i] 全部重命名成 dp'[i+1]:分配大小 N+1,dp'[0] 就是空前缀的 base,不需要负下标。这不是改你的语义,是纯下标偏移:
1
2
3
4
| vector<ll> dp(N + 1, ...);
dp[0] = 0;
|
很多人看到这写法叫"按前缀长度索引"——其实只是机械的 +1 偏移,不是换语义。它的好处是热循环没分支。
两种等价,挑顺手的。(A) 贴近你的思维模型,(B) 编译出的代码可能稍快一丁点(其实差不多)。
AC 代码
AC 提交: 372581604
展开完整 C++ 源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
#include <bits/stdc++.h>
#define all(vec) vec.begin(),vec.end()
#define lson(o) (o<<1)
#define rson(o) (o<<1|1)
#define SZ(a) ((long long) a.size())
#define fsp(x) fixed<<setprecision(x)
using namespace std;
#if 0 && defined(LOCAL)
namespace DBG {
template<typename T> void debug(T x);
void debug(bool x);
void debug(string x);
template<typename T> void debug(vector<T> v);
template<typename T, size_t N> void debug(array<T, N> v);
template<typename T> void debug(set<T> s);
template<typename T, typename U> void debug(pair<T, U> p);
template<typename T, typename U> void debug(map<T, U> m);
template<typename T>
void debug(T x) { cerr << x; } void debug(bool x) { cerr << (x ? "T" : "F"); } void debug(string x) { cerr << '"' << x << '"'; }
template<typename T> void debug(vector<T> v) { constexpr bool nested = requires(T t) { t.begin(); t.end(); }; int n = v.size(); cerr << "["; for (int i = 0; i < n; i++) { if constexpr (nested) { if (i) cerr << ","; cerr << "\n "; } else { if (i) cerr << ", "; } debug(v[i]); } if constexpr (nested) { if (n) cerr << "\n"; } cerr << "]"; }
template<typename T, size_t N> void debug(array<T, N> v) { constexpr bool nested = requires(T t) { t.begin(); t.end(); }; cerr << "["; for (size_t i = 0; i < N; i++) { if constexpr (nested) { if (i) cerr << ","; cerr << "\n "; } else { if (i) cerr << ", "; } debug(v[i]); } if constexpr (nested) { if (N) cerr << "\n"; } cerr << "]"; }
template<typename T> void debug(set<T> s) { cerr << "{"; int f = 0; for (auto x: s) { if (f++) cerr << ", "; debug(x); } cerr << "}"; }
template<typename T, typename U> void debug(pair<T, U> p) { cerr << "("; debug(p.first); cerr << ", "; debug(p.second); cerr << ")"; }
template<typename T, typename U> void debug(map<T, U> m) { cerr << "{"; int f = 0; for (auto &[k, v]: m) { if (f++) cerr << ", "; debug(k); cerr << ": "; debug(v); } cerr << "}"; }
void _dbg() { cerr << endl; }
template<typename T, typename... A> void _dbg(T x, A... a) { debug(x); if (sizeof...(a)) cerr << ", "; _dbg(a...); }
}
#define dbg(x...) cerr << "[" << setw(7) << #x << "] = ", DBG::_dbg(x)
#define cend cerr<<"\n---------------------------------------------------\n"
#define cEnd cerr<<"\n***************************************************\n"
#define myAssert(x) assert(x)
#else
#define dbg(x...) 11
#define cend 45
#define cEnd 14
#define myAssert(x) 14
#endif
using ll = long long;
using ull = unsigned long long;
using DB = double;
using i128 = __int128;
using CD = complex<double>;
static constexpr ll MAXN = (ll) 1e6 + 10, INF = (1ll << 61) - 1;
static constexpr ll mod = 998244353;
static constexpr double eps = 1e-8;
const double PI = acos(-1.0);
ll lT, testcase;
ll get_median(vector<ll> A) {
sort(all(A));
return A[SZ(A) / 2];
}
void preSumCompute(const vector<ll> &A, vector<ll> &preBtm, vector<ll> &preLtm, ll M) {
preBtm.resize(SZ(A) + 1);
preLtm.resize(SZ(A) + 1);
for (int i = 0; i < SZ(A); ++i) {
int valBt = (A[i] >= M);
int valLt = (A[i] <= M);
preBtm[i + 1] = preBtm[i] + valBt;
preLtm[i + 1] = preLtm[i] + valLt;
}
}
bool checkLr(const vector<ll> &preBtm, const vector<ll> &preLtm, ll l, ll r) {
ll len = r - l + 1;
ll valBt = preBtm[r + 1] - preBtm[l];
ll valLt = preLtm[r + 1] - preLtm[l];
ll len2 = (len + 1) / 2;
return valBt >= len2 && valLt >= len2 && (len & 1);
}
void Solve() {
ll N;
cin >> N;
vector<ll> A(N);
myAssert(get_median({1,3,2})==2);
for (int i = 0; i < N; ++i) {
cin >> A[i];
}
ll med = get_median(A);
vector<ll> preBtm, preLtm;
preSumCompute(A, preBtm, preLtm, med);
dbg(preBtm);
dbg(preLtm);
vector<ll> dp(N + 1, -INF);
dp[0] = 0;
for (int r = 0; r < N; ++r) {
for (int l = 0; l <= r; ++l) {
if (checkLr(preBtm, preLtm, l, r)) {
dp[r + 1] = max(dp[r + 1], 1 + dp[l]);
}
}
}
dbg(med);
dbg(dp);
cout << dp.back() << "\n";
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
#ifdef LOCAL
cout.setf(ios::unitbuf);
#endif
cin >> lT;
for (testcase = 1; testcase <= lT; ++testcase)
Solve();
return 0;
}
|
心路历程
从 mentor.tex 对话录里提炼出的 3 次主要卡壳:
-
**第一次摔:**理解错题意,以为子数组可以重叠(其实是滑动窗口的概念)。题面里 k 序列严格递增、首尾相接才是合法划分——每个元素恰好属于一段。
-
**第二次摔:**写区间中位数判定时想用「区间内 m 的个数 > ⌈len/2⌉」当条件,被反例 [1,2,3],m=2 打回——这是「严格多数」、比「中位数 = m」强。换成 ±1 编码 + 两套前缀和才对。
-
**第三次摔:**dp 默认 0 初始化,dp[r+1]=max(…,1+dp[l]) 把不可达的 dp[l] = 0 当成合法 base,段数被高估。改成 dp(N+1, -INF); dp[0] = 0 后 AC。
关键教训写进了板子 §debug 章节:DP 不可达状态必须用 -INF 显式标识——base 之外一律 -INF(求 max)/ INF(求 min),0 只能用于「计数 / 无贡献」语义。
附件
与 Claude 的全过程对话录 LaTeX 编译产物(mentor.pdf)。
mentor.pdf — 带教对话录