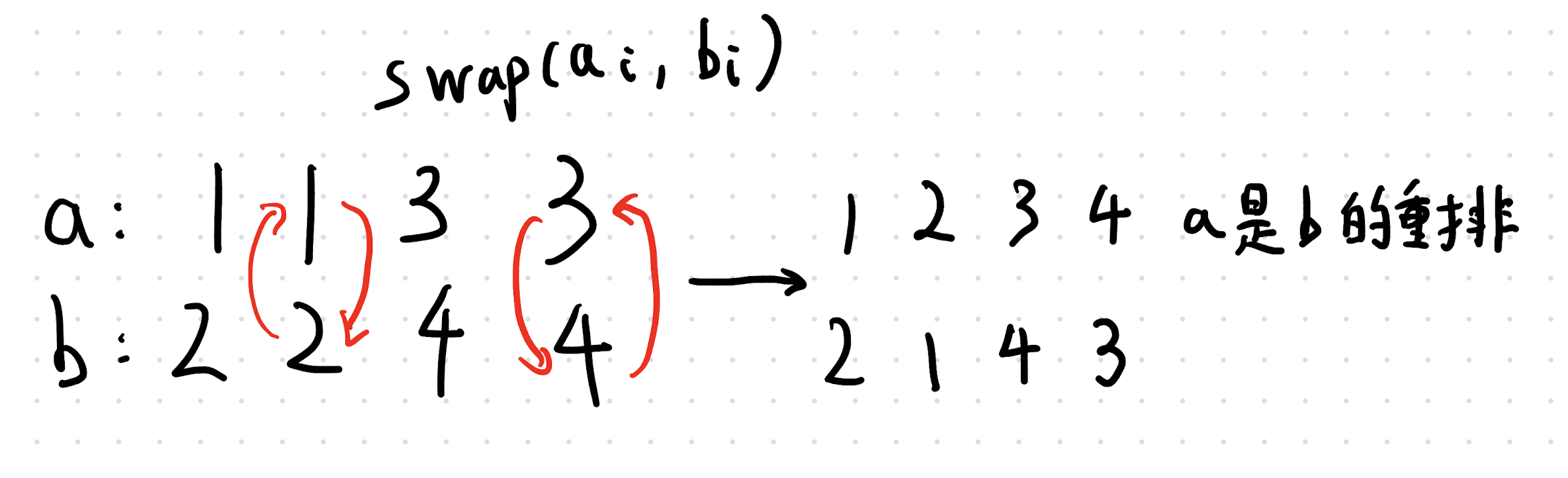题目大意
题目大意
有 张卡片排成一排,卡片上分别写着数字 ,初始时全部背面朝上。
你将使用以下“贪心”策略来进行翻牌游戏,每回合精确地翻开两张卡片:
-
如果你之前已经翻开过(且未被消除)两张数字相同的卡片,则直接翻开并消除它们。
-
否则,翻开从左到右第一张从未被翻开过的卡片,设其数字为 。
-
接着,如果之前已经翻开过另一张数字为 的卡片,则翻开并消除它。
-
否则,再次翻开从左到右第一张从未被翻开过的卡片。如果这两张卡片数字相同,则消除;如果不同,则重新翻回背面。
给定 和 ,要求构造一个 到 各出现两次的排列,使得上述算法恰好需要 个回合才能消除所有卡片。如果存在这样的排列,输出 YES 并输出该排列;否则输出 NO。
输入格式
第一行包含一个整数 (),表示测试数据组数。
接下来每组数据包含一行,包含两个整数 和 (,)。
保证所有测试数据中 的总和不超过 。
输出格式
如果不存在满足条件的卡片排列,输出一行 NO。
如果存在,输出一行 YES,并在下一行输出 个整数 (),表示卡片上的数字排列。如果有多个合法的排列,输出任意一个即可。
样例输入
1 | 6 |
样例输出
1 | YES |
样例解释
对于第一组样例,初始排列为 2 1 2 1,每回合的操作如下:
-
第 回合:翻开第一张未翻过的卡片(数字 ),之前没有记录,接着翻开下一张未翻过的卡片(数字 )。数字不同,翻回背面。此时记下前两张卡片的数字为 和 。
-
第 回合:翻开第一张未翻过的卡片(第三张,数字 ),由于之前已经翻开过数字为 的卡片(第一张),因此翻开第一张,两张卡片相同并消除。
-
第 回合:翻开第一张未翻过的卡片(第四张,数字 ),由于之前已经翻开过数字为 的卡片(第二张),因此翻开第二张,两张卡片相同并消除。
游戏结束,共花费 个回合。
对于第四组样例,初始排列为 1 2 3 1 2 3,每回合的操作如下:
-
第 回合:翻开第一、第二张从未翻过的卡片,数字分别为 和 。数字不同,翻回背面。
-
第 回合:翻开第三、第四张从未翻过的卡片,数字分别为 和 。数字不同,翻回背面。
-
第 回合:此时发现之前翻开过(且未消除)的卡片中存在两张数字相同的卡片(第一张和第四张均为 ),触发规则第一条,直接翻开这两张卡片并消除。
-
第 回合:没有两张已翻开且相同的卡片。翻开第五张卡片(数字 ),由于之前翻开过数字 (第二张卡片),因此翻开第二张卡片并消除。
-
第 回合:翻开第六张卡片(数字 ),由于之前翻开过数字 (第三张卡片),因此翻开第三张卡片并消除。
游戏结束,算法恰好在 回合赢得游戏。
注意啊,这是一个翻牌游戏,就是一开始你是不知道这些数字,它的大小,你需要翻开来你才知道。

思路讲解
这个题实在是太简单了,我操,哎呀,真的是后悔为什么没看这题。
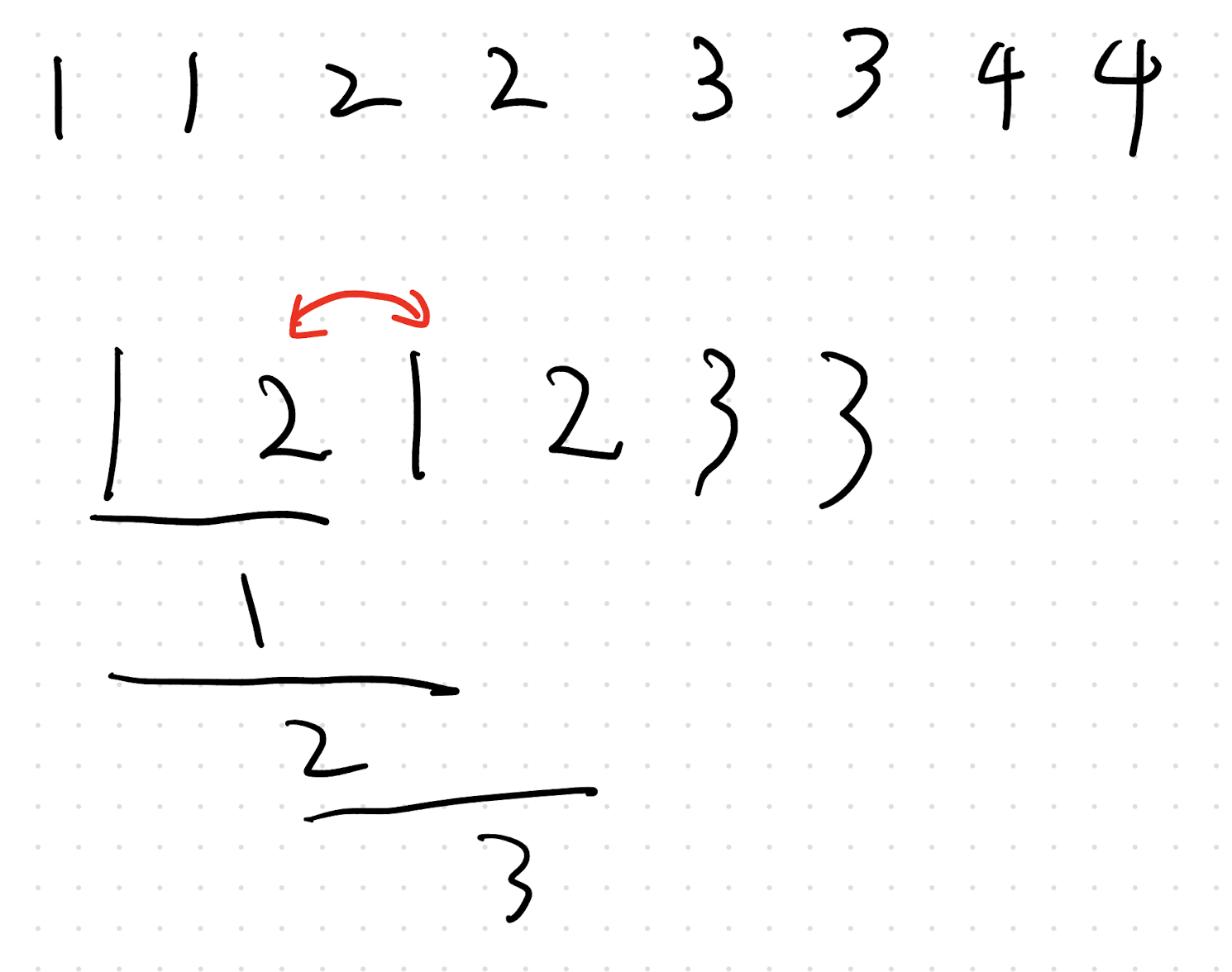
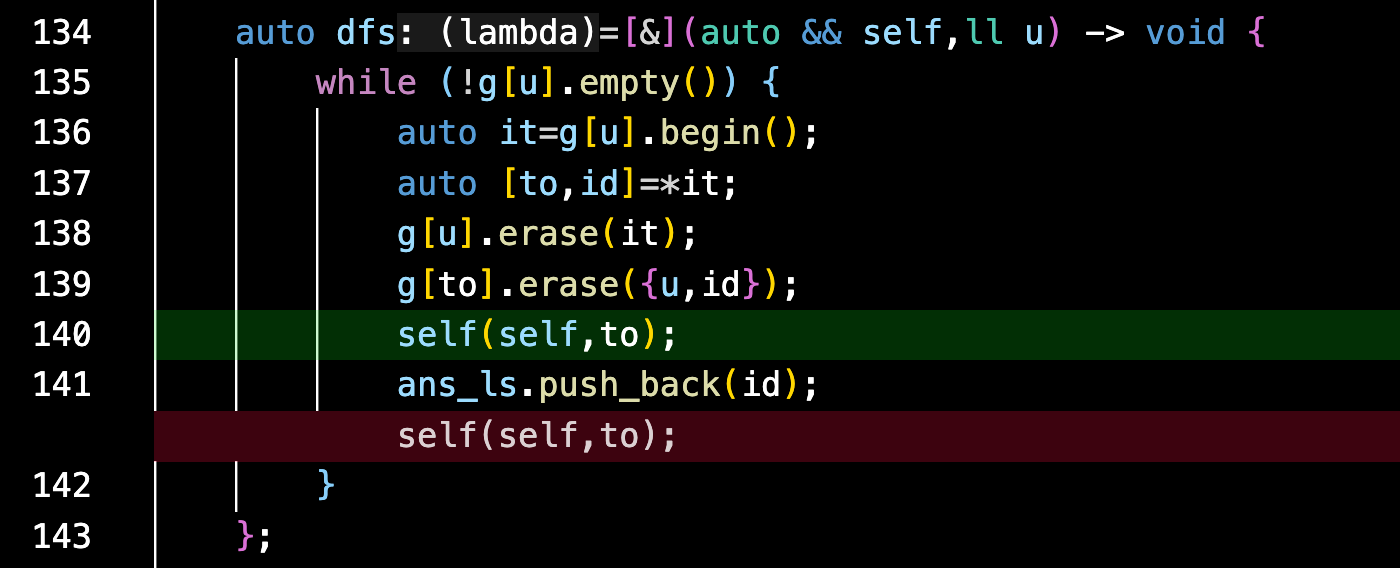
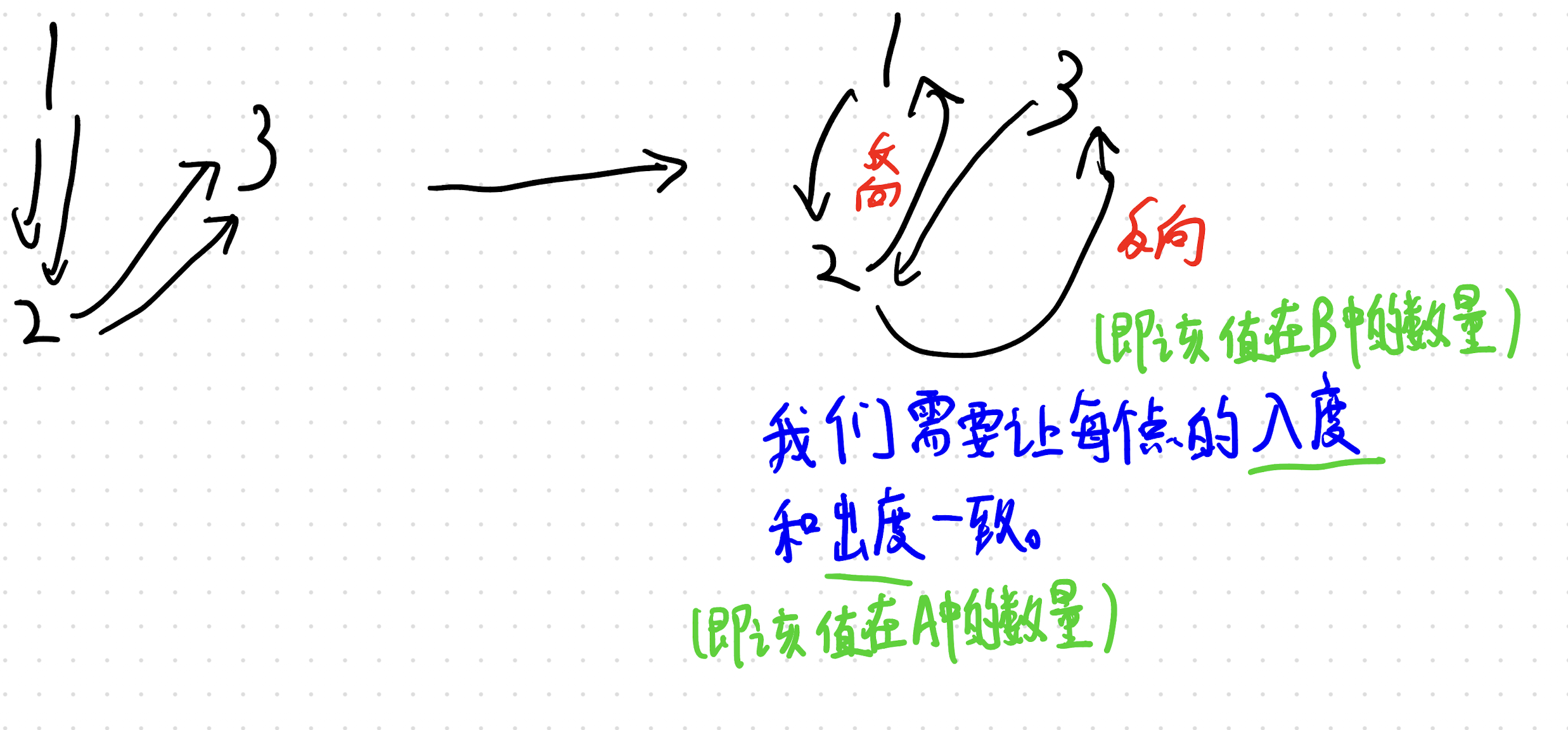
不难发现,在这种位置交换一下,就会增加一次这个轮数,那么你就把所有的这些位置,就是你就交换他要求的这个轮数啊,当然是比N多的这个轮数然后就就好了。也就是把我们所找到的这个位置交换我们代码当中的REM次就可以了。
1 | ll rem=K-N; |
AC代码
https://codeforces.com/contest/2202/submission/364156796
1 | /** |