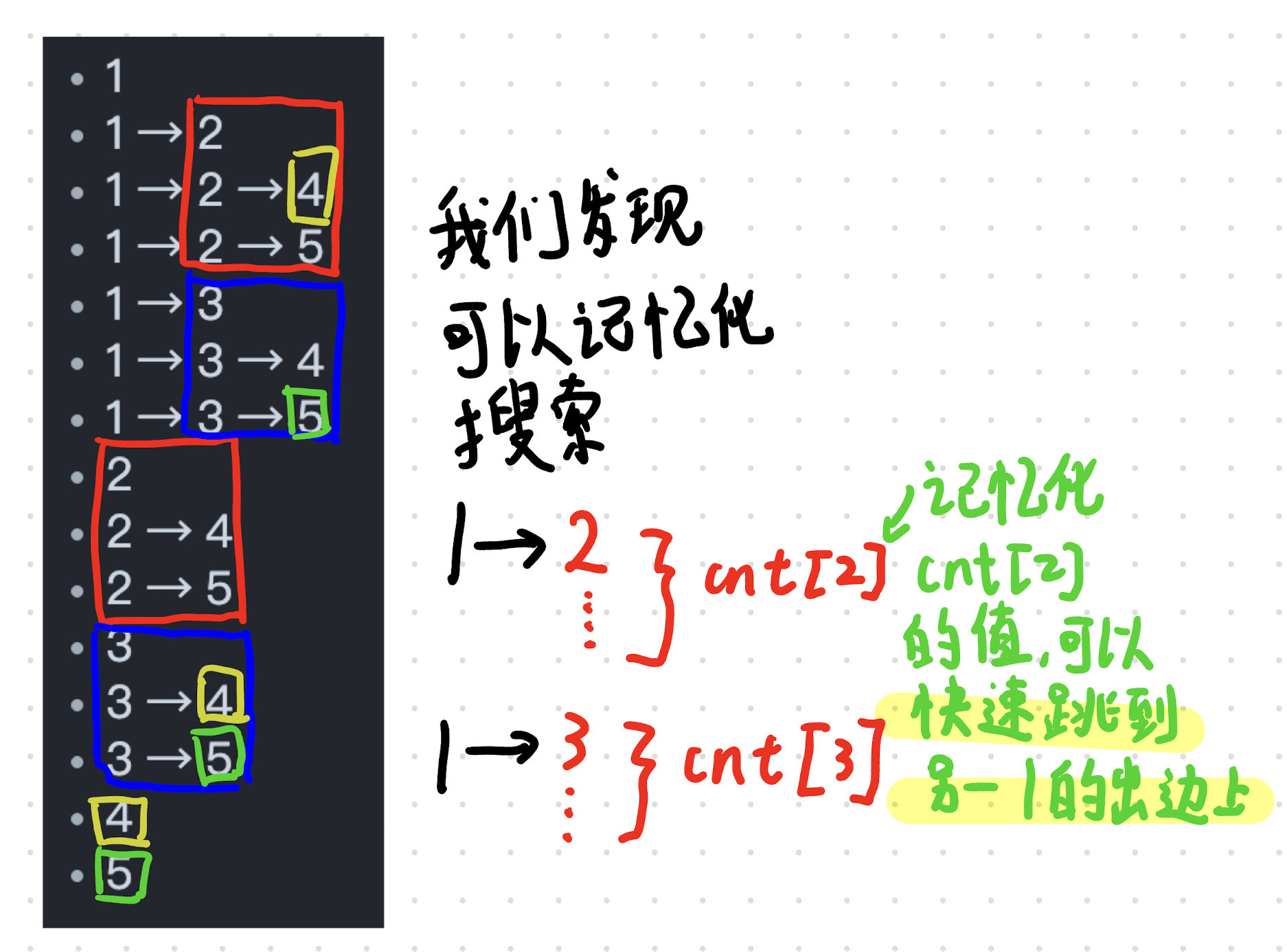
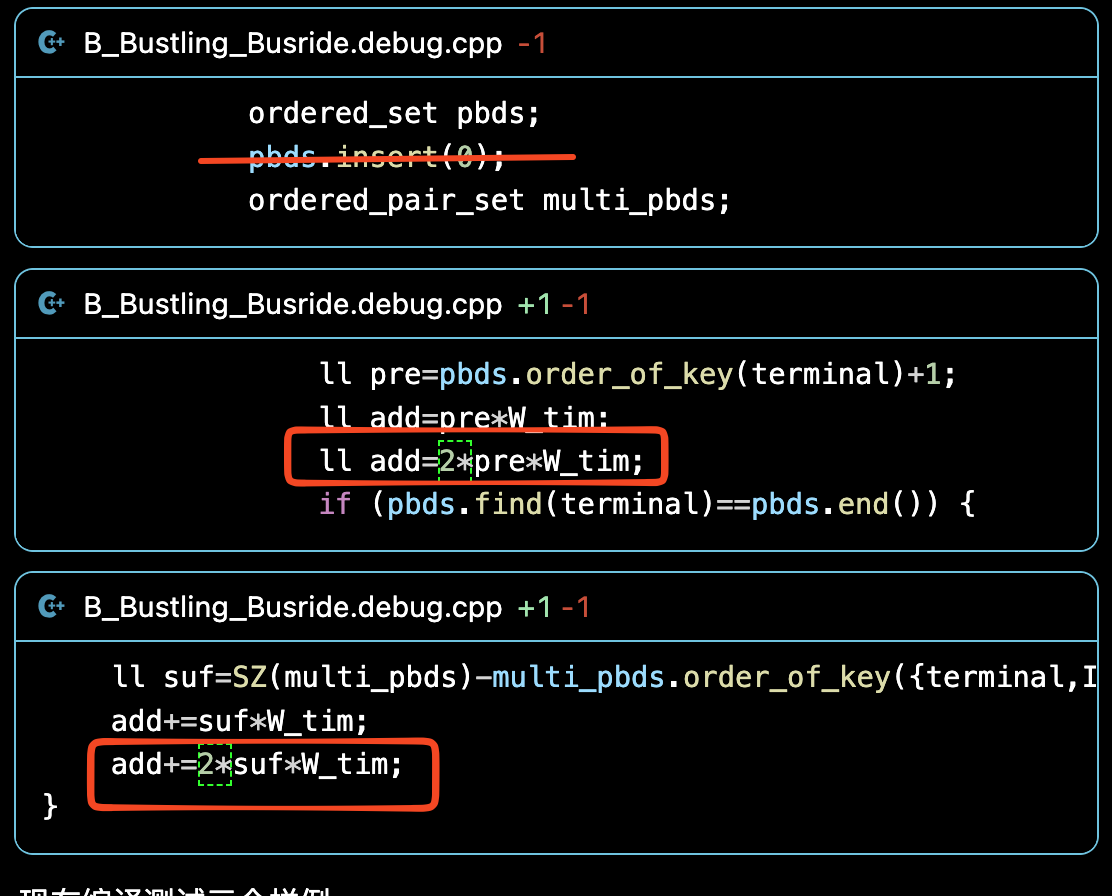
for (int i=0;i<N;++i) { for (int len=1;len<=10;++len) { if (i-len+1<0) { break; } // 一个 string view 啊,这个 view 就是从 i 减 len 加一开始,长度为 len 的一个 view。 string_view s_view(s.data()+i-len+1,len); ll valid_num=0; // 这个循环就是计算 valid num 的数量。说白了就是长度为 len 的合法单一划分数量。 for (auto &ls:len_words_mtx[len]) { bool ok=true; for (int j=0;j<SZ(ls);++j) { if (ls[j]==s_view[j] || s_view[j]=='?') {
}else { ok=false; } } if (ok) { valid_num++; } } // 从 i - len 处转移,一共有 valid num 种转移方法,所以说是乘法原理。 // 注意 i - len 为小于零的时候是空,也是 1 种合法的方案。 dp[i]+=(i-len<0?1:dp[i-len])*valid_num; dp[i]%=mod; } }
第一行包含四个整数 n,b,r,w (1≤n,b≤105,1≤r,w≤106),分别表示乘客总数、站点总数、公交车发车间隔、上下车每人次的耗时。
第二行包含 b 个整数 di (1≤di,∑di≤106),表示从第 i−1 站行驶到第 i 站所需的时间。
第三行包含 n 个整数 ti (1≤ti≤b),按队列顺序给出第 i 个人的目的地站点编号。
这个 Opus 4.6给出的提示非常好,就是二分还是二分那个答案,答案就是最大的到达时间。但是,然后我们给出了一个中间量,我们给出了一个中间量,这个中间量是什么呢?这个中间量就是一辆车可以最长运行多长时间。不过我们其实没有意识到一件事情啊,就是其实一辆车可以最长运行多长时间,可以非常自然的使用这个答案推出来。
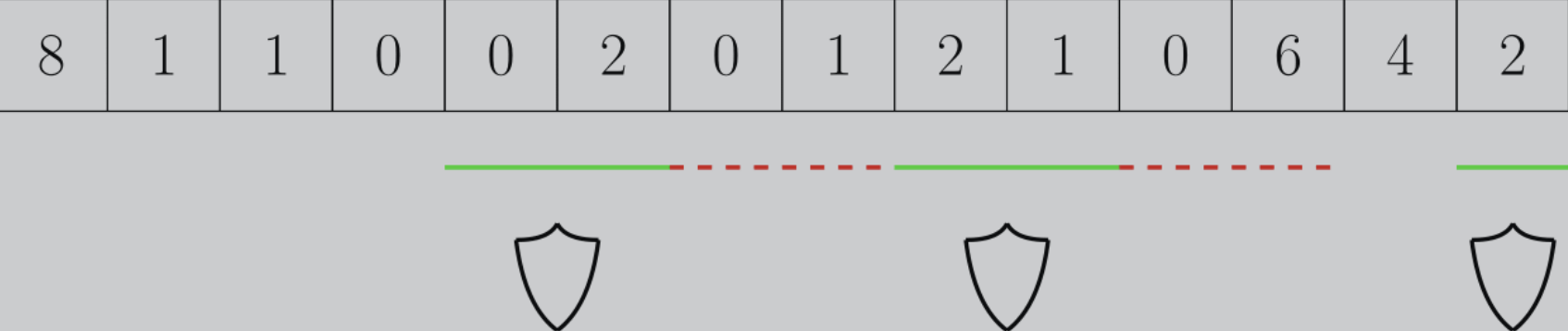
那么初始的可行域是从一,就是初始的可行域的左起点是 Max 一和 P 减 d 加一。右起点就是 P。然后在后面的过程当中,我们去不断的更新左起点。一旦当左起点它比右起点还大的时候,左起点比右起点大的时候呢,这个时候就说明我们需要新开一个区间了。然后我们新开区间的左起点,就是可行域的左端点,就是 L 加2乘以 d 和 P 减 d 加一中取一个 max 如果说然后这个可行域的 R 就是 P 。如果说 L 大于 R 那就说明就进不了可行域。就这个是错的,就 return false 就好了。