给定一个长度为 n n n p p p n n n a a a
你可以进行任意次操作,每次操作选择一个下标 i i i 1 ≤ i < n 1 \le i < n 1 ≤ i < n
也就是说,每次选两个相邻元素,把其中一个的值复制到另一个上。
判断是否能通过若干次操作,把排列 p p p a a a
样例解释:
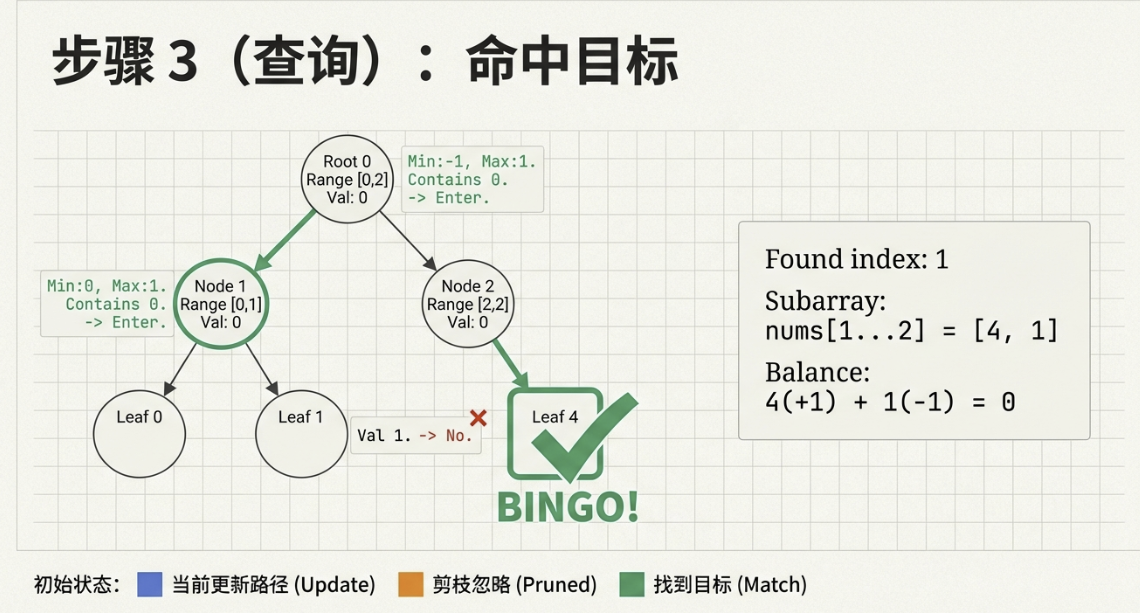
第一组:p = [ 1 , 2 , 3 ] p = [1, 2, 3] p = [ 1 , 2 , 3 ] a = [ 1 , 2 , 2 ] a = [1, 2, 2] a = [ 1 , 2 , 2 ] i = 2 i = 2 i = 2 p 2 p_2 p 2 p 3 p_3 p 3 [ 1 , 2 , 2 ] [1, 2, 2] [ 1 , 2 , 2 ] a a a YES。
第二组:p = [ 3 , 1 , 2 , 4 ] p = [3, 1, 2, 4] p = [ 3 , 1 , 2 , 4 ] a = [ 3 , 4 , 2 , 2 ] a = [3, 4, 2, 2] a = [ 3 , 4 , 2 , 2 ] a a a NO。
第三组:p = [ 1 , 3 , 2 , 5 , 4 ] p = [1, 3, 2, 5, 4] p = [ 1 , 3 , 2 , 5 , 4 ] a = [ 3 , 3 , 3 , 5 , 4 ] a = [3, 3, 3, 5, 4] a = [ 3 , 3 , 3 , 5 , 4 ] i = 1 i = 1 i = 1 p 2 p_2 p 2 p 1 p_1 p 1 [ 3 , 3 , 2 , 5 , 4 ] [3, 3, 2, 5, 4] [ 3 , 3 , 2 , 5 , 4 ] i = 2 i = 2 i = 2 p 2 p_2 p 2 p 3 p_3 p 3 [ 3 , 3 , 3 , 5 , 4 ] [3, 3, 3, 5, 4] [ 3 , 3 , 3 , 5 , 4 ] a a a YES。
使用类似于双指针的做法,判断这个 A 数组是去重以后是否是 P 数组 P 排列的子序列。具体来说,在实现当中,我们是使用 P 排列去对应 A 的这个数组,去对应 A 数组,就是你可以理解为我们用一个 PI 去消 AJ 去消 A 数组中的元素,那么这个 pi 当然是可以一直消一直消,可以消除连续的 aj 的元素,只要 aj 和 pi 相等,连续的相等就可以。但是 pi 一旦遇到了第一个和自己不相等的 aj 就会停下来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void Solve () ll N; cin >> N; vector<ll> P (N+2 ) ,A (N+2 ) ; for (int i=1 ;i<=N;++i) { cin>>P[i]; } for (int i=1 ;i<=N;++i) { cin>>A[i]; } ll bp=1 ; for (ll i=1 ;i<=N;++i) { bool isbreak=false ; for (ll j=bp;j<=N;++j) { if (P[i]!=A[j]) { bp=j; isbreak=true ; break ; } } if (!isbreak) { bp=N+1 ; } } if (bp==N+1 ) { cout<<"YES\n" ; }else { cout<<"NO\n" ; } }
AChttps://codeforces.com/contest/2197/submission/362443575
源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 #include <bits/stdc++.h> #define all(vec) vec.begin(),vec.end() #define lson(o) (o<<1) #define rson(o) (o<<1|1) #define SZ(a) ((long long) a.size()) #define debug(var) cerr << #var <<" = [" <<var<<"]" <<"\n" ; #define debug1d(a) \ cerr << #a << " = [" ; \ for (int i = 0; i < (int)(a).size(); i++) \ cerr << (i ? ", " : "" ) << a[i]; \ cerr << "]\n" ; #define debug2d(a) \ cerr << #a << " = [\n" ; \ for (int i = 0; i < (int)(a).size(); i++) \ { \ cerr << " [" ; \ for (int j = 0; j < (int)(a[i]).size(); j++) \ cerr << (j ? ", " : "" ) << a[i][j]; \ cerr << "]\n" ; \ } \ cerr << "]\n" ; #define debug3d(a) \ cerr << #a << " = [\n" ; \ for (int i = 0; i < (int)(a).size(); i++) \ { \ cerr << " [\n" ; \ for (int j = 0; j < (int)(a[i]).size(); j++) \ { \ cerr << " [" ; \ for (int k = 0; k < (int)(a[i][j]).size(); k++) \ cerr << (k ? ", " : "" ) << a[i][j][k]; \ cerr << "]\n" ; \ } \ cerr << " ]\n" ; \ } \ cerr << "]\n" ; #define cend cerr<<"\n-----------\n" #define fsp(x) fixed<<setprecision(x) using namespace std;using ll = long long ;using ull = unsigned long long ;using DB = double ;using CD = complex<double >;static constexpr ll MAXN = (ll)1e6 +10 , INF = (1ll <<61 )-1 ;static constexpr ll mod = 998244353 ; static constexpr double eps = 1e-8 ;const double pi = acos (-1.0 );ll lT,testcase; void Solve () ll N; cin >> N; vector<ll> P (N+2 ) ,A (N+2 ) ; for (int i=1 ;i<=N;++i) { cin>>P[i]; } for (int i=1 ;i<=N;++i) { cin>>A[i]; } ll bp=1 ; for (ll i=1 ;i<=N;++i) { bool isbreak=false ; for (ll j=bp;j<=N;++j) { if (P[i]!=A[j]) { bp=j; isbreak=true ; break ; } } if (!isbreak) { bp=N+1 ; } } if (bp==N+1 ) { cout<<"YES\n" ; }else { cout<<"NO\n" ; } } signed main () ios::sync_with_stdio (false ); cin.tie (nullptr ); cout.tie (nullptr ); #ifdef LOCAL cout.setf (ios::unitbuf); #endif cin >> lT; for (testcase=1 ;testcase<=lT;++testcase) Solve (); return 0 ; }