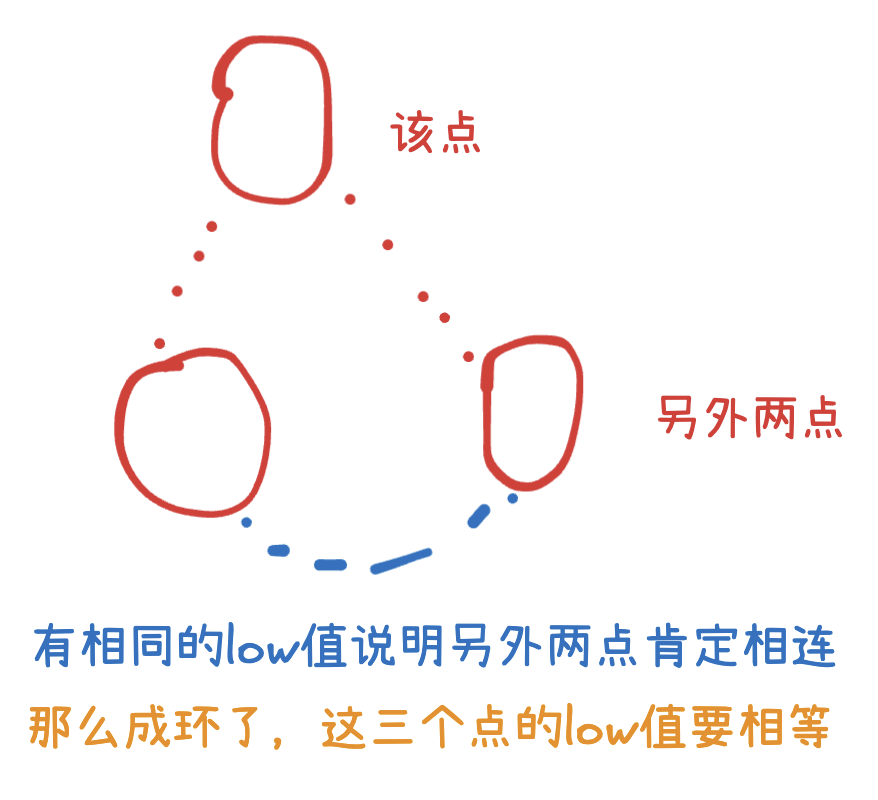
思路讲解
参考题解
https://ac.nowcoder.com/discuss/1452143
直接记忆化会导致TLE,所以我进行了一些小小的优化,具体见图
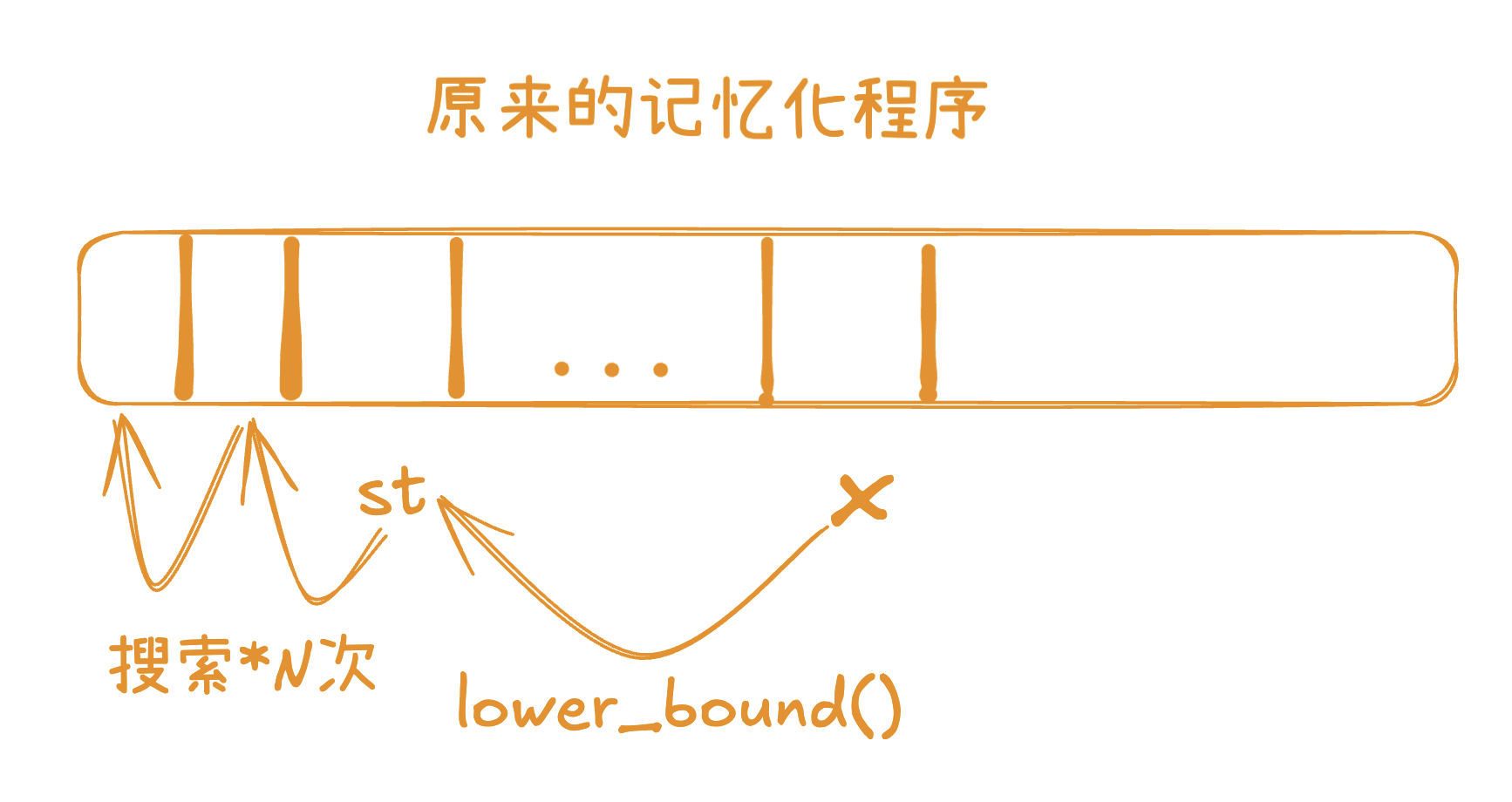
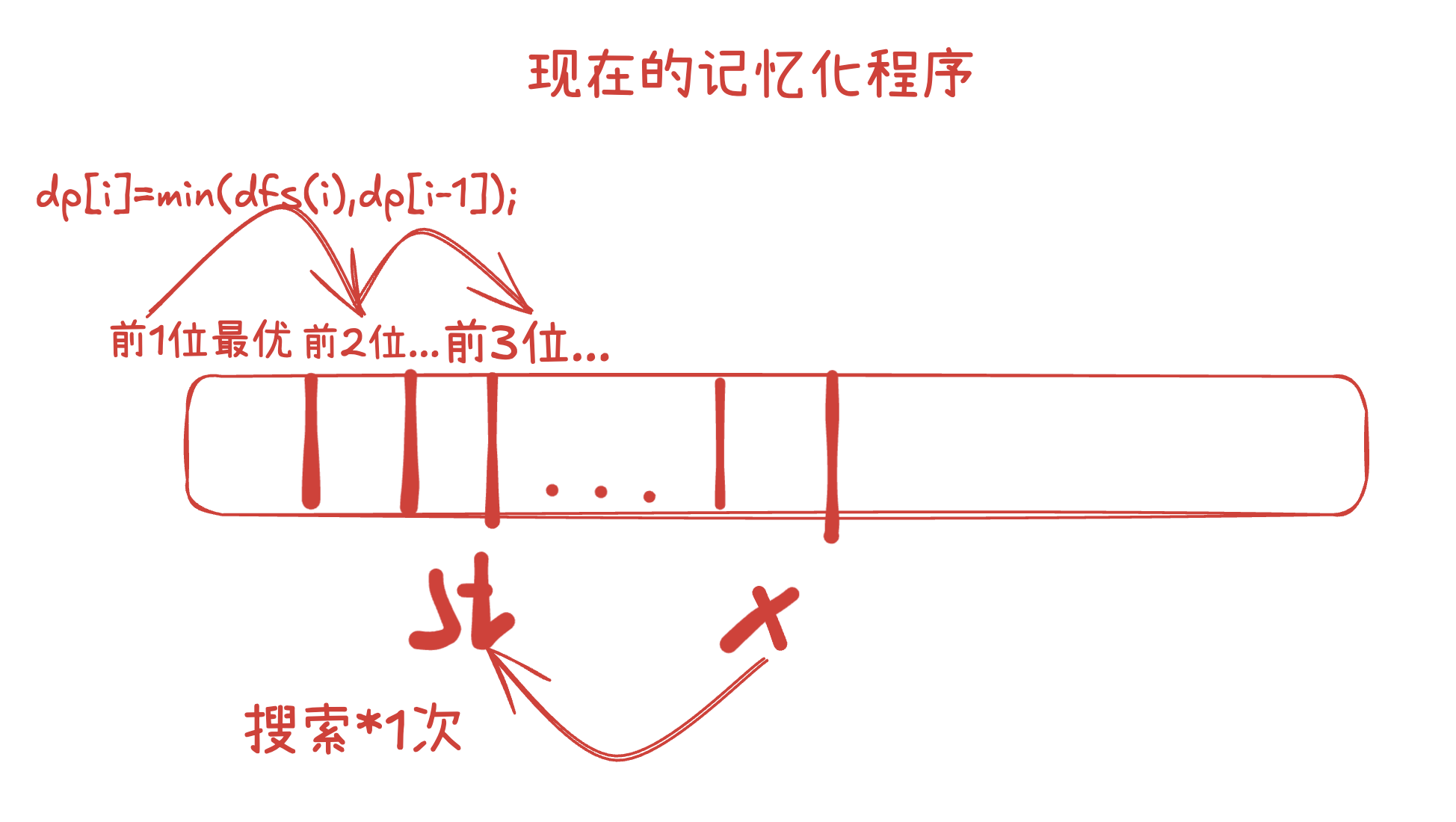
当然,改动之后dp里装的就是以前1~i位为末尾的最优的情况(最少的消耗)。
1
2
3
4
| for(int i=1;i<=N;++i){
if(i!=1) dp[i]=min(dfs(i),dp[i-1]);
else dp[i]=dfs(i);
}
|
所以这个程序其实是个伪装成记忆化搜索的递推!
那为什么不直接写递推那?还不是不太直接想的出来。。。
AC代码
AC
https://ac.nowcoder.com/acm/contest/view-submission?submissionId=74795179
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
| #include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <deque>
#include <queue>
#include <vector>
#include <set>
#include <map>
#include <unordered_map>
#include <unordered_set>
#include <cmath>
#include <bitset>
#include <iterator>
#include <random>
#include <iomanip>
#include <cctype>
#include <array>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
typedef pair<ll,ll> pll;
typedef array<ll,3> arr;
const ll MAXN=static_cast<ll>(1e5)+10;
struct abVal{
ll a;ll b;ll val;
bool operator<(const abVal &other) const{
return a<other.a;
}
};
vector<abVal> info(MAXN);
ll N,M,sumVal;
ll dp[MAXN];
bool cmp(abVal a,abVal b){
return a.a<b.a;
}
ll dfs(int x){
if(x==0) return sumVal;
if(dp[x]!=-1) return dp[x];
ll st=lower_bound(info.begin()+1, info.begin()+x, abVal{info[x].a-M,9999999,9999999})-info.begin()-1;
if(st==0){
dp[x]=min(sumVal-info[x].val+info[x].b,sumVal);
return dp[x];
}
dp[x]=min(dfs(st)-info[x].val+info[x].b,dfs(st));
return dp[x];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>N>>M;
for(int i=1;i<=N;++i){
cin>>info[i].a;
}
for(int i=1;i<=N;++i){
cin>>info[i].b>>info[i].val;
sumVal+=info[i].val;
}
sort(&info[1],&info[N+1],cmp);
memset(dp, -1, sizeof(dp));
for(int i=1;i<=N;++i){
if(i!=1) dp[i]=min(dfs(i),dp[i-1]);
else dp[i]=dfs(i);
}
ll ans=sumVal;
for(int i=1;i<=N;++i){
ans=min(ans,dp[i]);
}
cout<<ans<<'\n';
return 0;
}
|
心路历程(WA,TLE,MLE……)
直接记忆化会喜提TLE
https://ac.nowcoder.com/acm/contest/view-submission?submissionId=74794988