题目描述
给定两个长度均为 n 的小写字母字符串 S 和 T。
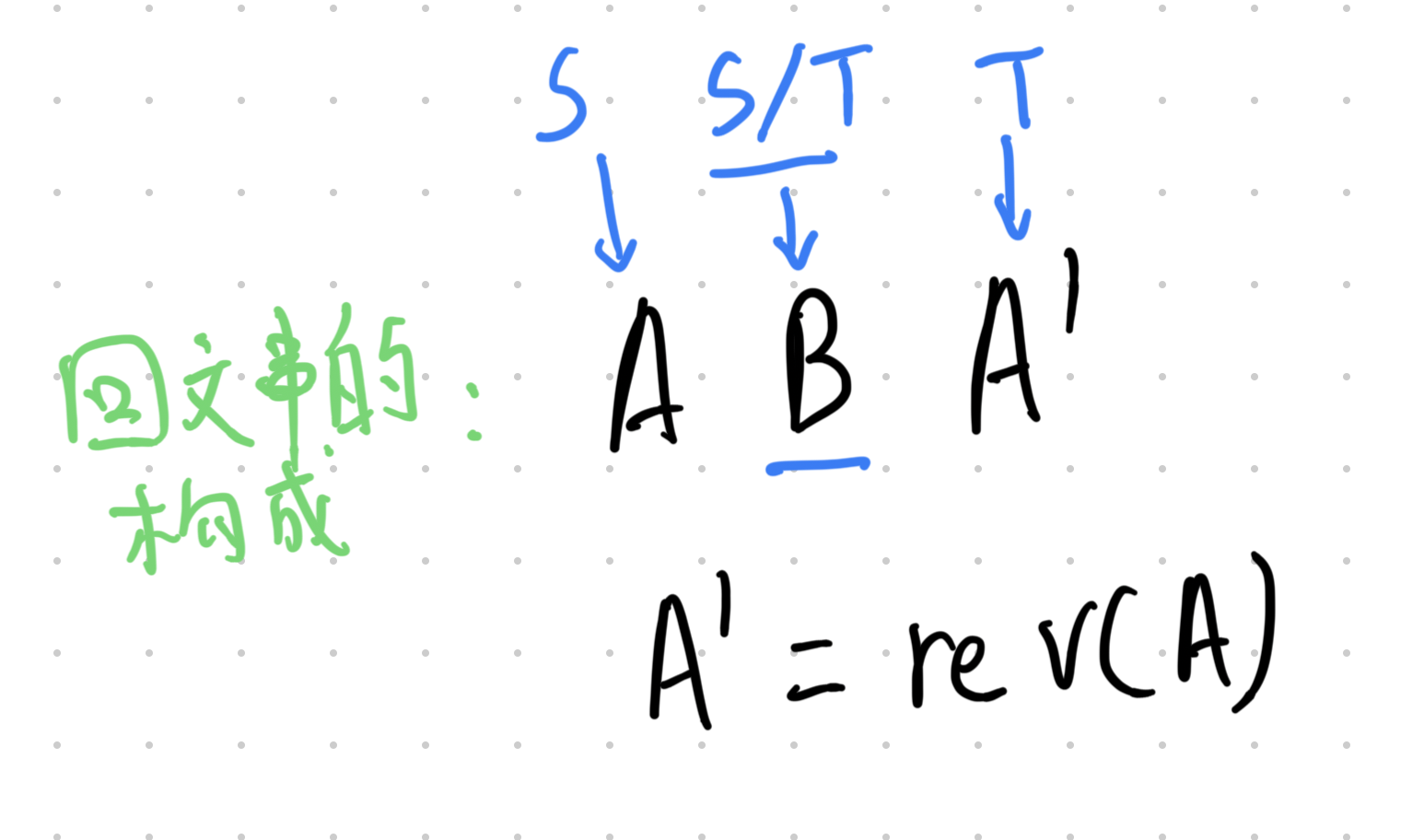
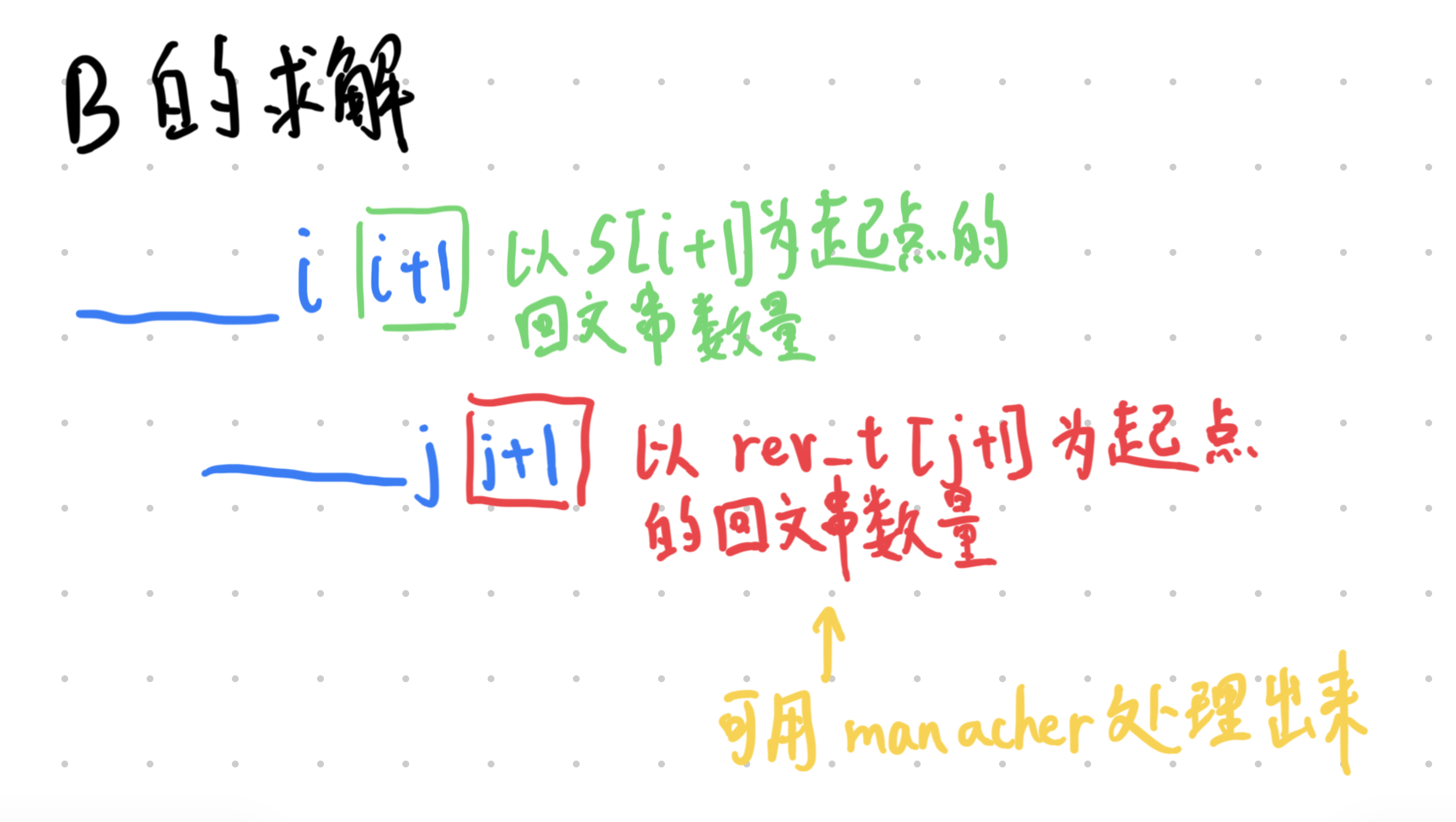
你需要在 S 中选取一个子串 S′,在 T 中选取一个子串 T′(空串不算作子串),并将 T′ 拼接在 S′ 的后面组成一个新的字符串。
求共有多少种选取方式,使得拼接后的新字符串是一个回文串。
注:选取方式由子串在原串中的起始和终止位置决定;回文串指正读和反读都相同的字符串。
输入格式
第一行输入一个整数表示测试组数 T(T≤10)。
接下来每组数据输入两行,分别表示字符串 S 和 T。
数据保证两个字符串长度相等且 n≤2000。
/* * */ #include<ext/pb_ds/assoc_container.hpp> usingnamespace __gnu_pbds; using ordered_set = tree<ll, null_type, less<>, rb_tree_tag, tree_order_statistics_node_update>; constint RANDOM = chrono::high_resolution_clock::now().time_since_epoch().count();
structchash { intoperator()(int x)const{ return x ^ RANDOM; } };
structU { using u128 = __uint128_t; staticconstexpr ll MOD = (1ULL << 61) - 1;
ll v; // always in [0, MOD)
// --- constructors --- U() : v(0) { }
U(ll x) { ll t = x % MOD; if (t < 0) t += MOD; v = (ll) t; }
// explicit U(ull x) { // ll s = (x & MOD) + (x >> 61); // if (s >= MOD) s -= MOD; // v = s; // }
// --- core ops --- staticinline ll add(ll a, ll b){ ll s = a + b; if (s >= MOD) s -= MOD; return s; }
staticinline ll sub(ll a, ll b){ return (a >= b) ? (a - b) : (a + MOD - b); }
staticinline ll mul(ll a, ll b){ u128 t = (u128) a * b; // < 2^122 ll s = ll(t & MOD) + ll(t >> 61); // 1-step fold if (s >= MOD) s -= MOD; // at most one subtract needed return s; }
// --- operator overloads --- U &operator+=(const U &o) { v = add(v, o.v); return *this; }
U &operator-=(const U &o) { v = sub(v, o.v); return *this; }
U &operator*=(const U &o) { v = mul(v, o.v); return *this; }
friend U operator+(U a, const U &b) { a += b; return a; }
friend U operator-(U a, const U &b) { a -= b; return a; }
friend U operator*(U a, const U &b) { a *= b; return a; }
friendbooloperator==(const U &a, const U &b) { return a.v == b.v; } friendbooloperator!=(const U &a, const U &b) { return a.v != b.v; } friendbooloperator<(const U &a, const U &b) { return a.v < b.v; } friendbooloperator>(const U &a, const U &b) { return a.v > b.v; } friendbooloperator<=(const U &a, const U &b) { return a.v <= b.v; } friendbooloperator>=(const U &a, const U &b) { return a.v >= b.v; } };
const U base = 131;
// AC https://vjudge.net/solution/65151535 string matching 测试了find函数功能 // 2025/11/4 // AC https://www.luogu.com.cn/record/245201000 测试了这个push,pop,以及增强get鲁棒性。 structHS { // 字符串哈希模版 vector<U> hs, powBase; U hashval; ll n; string s; // 需要注意的是,字符串哈希和数字一样,都是越前面是越高位。 // 内部采用 0-based 下标,hs[i] 表示 s[0..i] 的哈希值。 HS(const string &ls) { // 使用const 引用才能绑定到常值对象上 n = SZ(ls); s = ls; hs.assign(n, 0); powBase.assign(n + 1, 0); powBase[0] = 1; for (ll i = 1; i <= n; ++i) { powBase[i] = powBase[i - 1] * base; } if (n > 0) { hs[0] = U(s[0]); for (ll i = 1; i < n; ++i) { hs[i] = hs[i - 1] * base + U(s[i]); } hashval = hs[n - 1]; } else { hashval = 0; } }
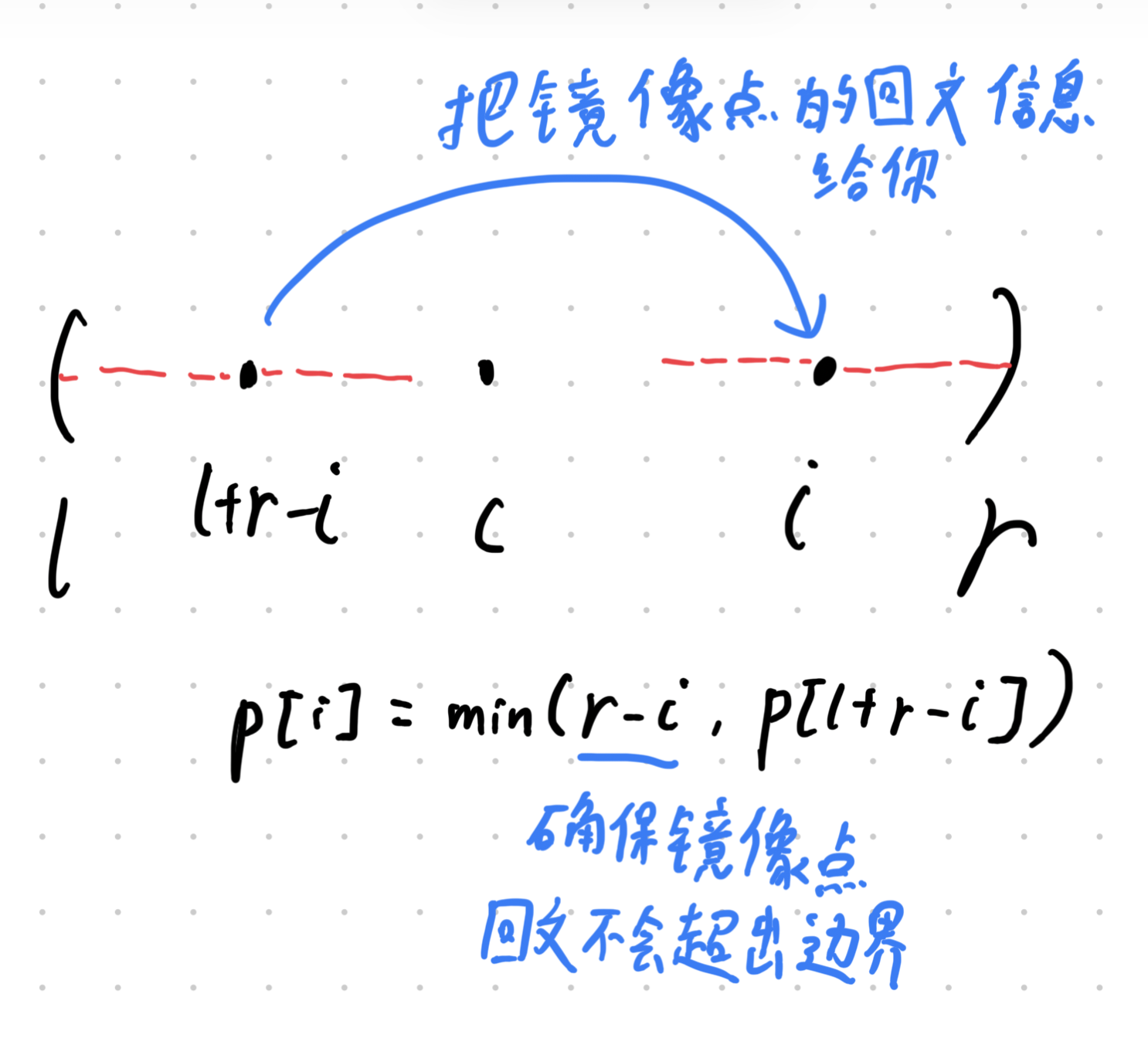
// get(l, r): 返回 s[l..r] 的哈希(0-based, inclusive) // 函数有一定鲁棒性,即使遇到超界问题也能自动纠正 U get(ll l, ll r){ if (n == 0) return0; l = max(0ll, l); r = min(n - 1, r); if (l > r) return0; if (l == 0) return hs[r]; return hs[r] - hs[l - 1] * powBase[r - l + 1]; }
// get(l): 返回 s[l..n-1] 的哈希(0-based) U get(ll l){ returnget(l, n - 1); }
// 返回ls在s中的出现次数 ll find(const string &ls){ U hxfind = 0; ll m = SZ(ls); if (m == 0) return n + 1; if (m > n) return0; for (ll i = 0; i < m; ++i) { hxfind = hxfind * base + ls[i]; } ll res = 0; for (ll r = m - 1; r < n; ++r) { U hx = get(r - m + 1, r); if (hx == hxfind) { res++; } } return res; }