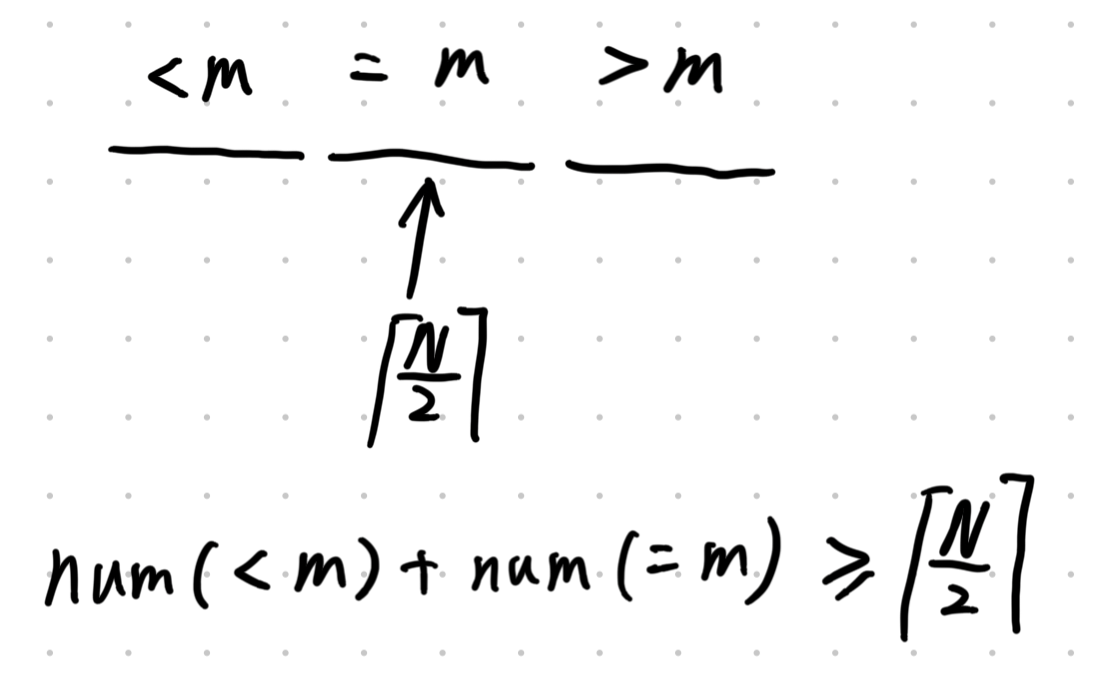🤖 Claude 苏格拉底式带教对话录原稿。每一步都是 mentor 提一个聚焦问题 → me 答 → 反复推进至完整算法。蓝色 callout 是 Claude,橙色 callout 是 zzy,原稿里 mentor 的反例 / 矫枉过正 / 用户吐槽全部逐字保留。
原题:CodeChef Starters 235 - Shift Game(Difficulty 2431)
背景
题目链接:https://www.codechef.com/problems/SHIFTGAME(CodeChef Starters 235,难度 2431)。
题面要点:给两个长度为 的 01 串 。每轮把 加进得分;若 则把 左移一位,否则把 左移一位。 个独立查询,每个查询给一个 ,问做完恰好 轮后的得分。约束 , 。
下面按算法带教(Socratic)方式逐步推进。蓝色 标注首次出现的关键术语 / 符号。
第 1 步:理解题目
🤖 Note: Claude (Mentor)
先用你自己的话讲讲:
- 游戏规则一句话总结:每次发生什么、得分加多少、谁会被左移?
- 关键观察: 都是长度 的 01 串,但 可以到 —— 你觉得这个数量级在暗示什么?
- 样例验证: 答案是 2,你能口算追一遍前 5 步、看看得分时刻在哪两步出现吗?
🧑 Note: zzy (Me)
okay,你先假设我理解题目了吧。
第 2 步:暴力解法 + 关键观察
🤖 Note: Claude (Mentor)
先把暴力解法的复杂度算清楚,再讨论怎么优化。
问 1(暴力):最直接的模拟法,每次取 ,加分,根据相等与否 left_shift。
- 单次 iteration 是 还是 ?(提示:left_shift 你打算怎么实现?)
- 次的总复杂度?
- 给定 , ,暴力为什么过不了?
问 2(关键观察 —— 这是这题的命根):left_shift 不会改变字符串的多重集,只是改变"指针"。换句话说,字符串本身永远是那个串,变的只是"当前从哪里开始读"。
那么状态只需要两个量描述:
其中 是 当前的起始指针, 是 当前的起始指针,都模 。
- 状态空间一共多少?
- 这意味着什么?(关键词:循环)
🧑 Note: zzy (Me)
状态空间是 的呀,是意味着循环,但是 的循环我们不能接受啊。
第 3 步:寻找更紧的循环节
🤖 Note: Claude (Mentor)
完全对!这就是关键卡点。 个状态意味着循环节最坏 ,确实接受不了。需要更深入的观察。
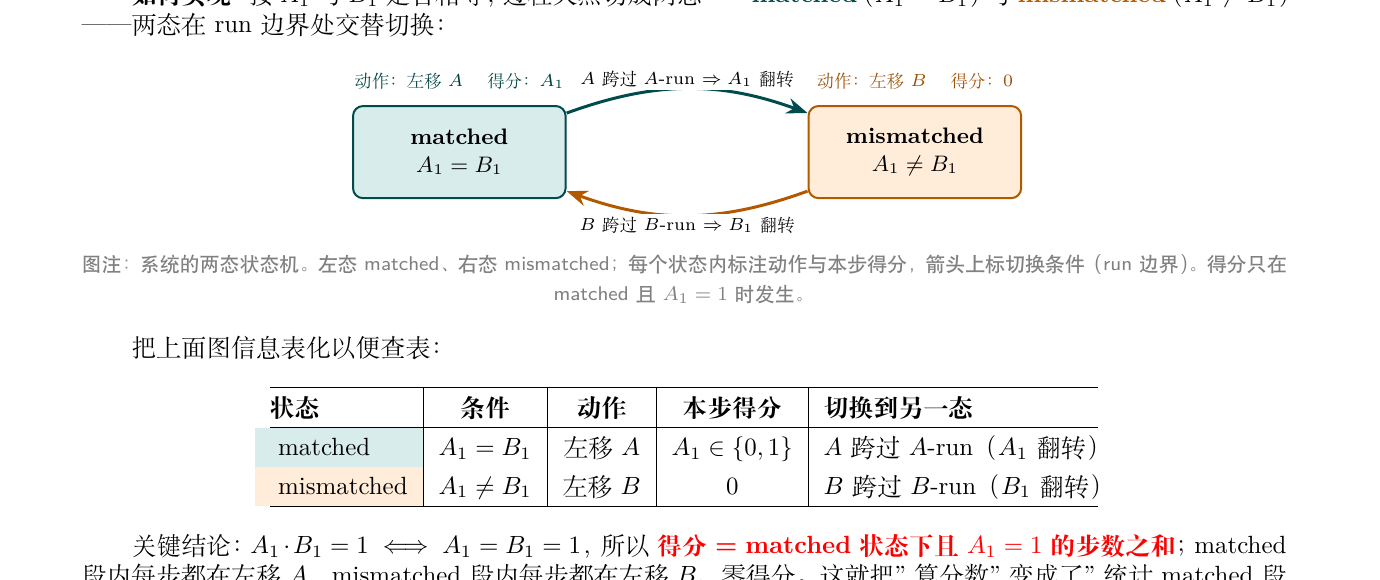
来看转移规则:
- : (只有 指针动)
- : (只有 指针动)
问 3(最关键的观察):不管哪种情况,每一步 都恰好增加 1。所以 步之后 (在某个模意义下成立)。那么真正的"自由变量"其实只有一个 —— 给定 ,只要知道 是多少, 就定了( )。 - 这把状态空间从 降到了 ,对吗?
- 那循环节最多多长?
- 进一步:在前 步里, 指针走过多少步(记作 ), 指针走过多少步( ),有没有什么结构?
先回答前两个,第三个是下一阶段的钩子。
🧑 Note: zzy (Me)
哦,你的意思就是说,给定了 ,知道了 , 就确定了是吧,所以说状态数只有 。okay,我现在已经理解这个状态为什么只有 个了,但是问题是, 虽然给定了,但是每次都是不同的 呀,如果按照这样子,不就变成了 了吗?也不行啊。
🤖 Note: Claude (Mentor)
好问题,这是这题第二个关键卡点。但你这里把两件事混在一起了 —— 我们把它拆开。
关键再框:轨迹是 query 无关的。
- 不管你有多少个 query、 是多少,整个游戏只演化出唯一一条序列
- query 只是问"这条序列在第 步时分数是多少",并不会改变序列本身。
- 所以正确的姿势是:先 precompute 一次,再 个 query 各自 查表。总复杂度 而不是 。
那现在真正的瓶颈在哪? 可以到 ,整条轨迹至少要走到这个长度才能给出答案 —— 表存不下也算不动。
所以问题精简成一个:
“一条 query 无关的、长度可以到 的轨迹,怎么用 空间表示?”
来到 第 4 步。
第 4 步:周期 = 把无穷轨迹压回
🤖 Note: Claude (Mentor)
单看这条轨迹本身(先不管 query),你觉得它是不是周期的?为什么?
提示:动力系统的"状态"你刚才已经数清楚了 —— 在某种意义下只有 个值。有限状态 + 确定性转移 必然会推出什么?
🧑 Note: zzy (Me)
当然是周期的呀,现在的问题是,我们是用 来唯一标识一个状态的,我们现在要想办法把这个状态数量降下来,将带这个 ,你懂吗?之前降的这个方法被我否定了。
🤖 Note: Claude (Mentor)
对,正中要害。 是 个,太多;之前那个"给定 就只剩 “是 依赖 query 的,对建立周期没用 —— 我们要的是 query 无关、真正只有 个状态 的视角。
提示:与其每一步都跟踪状态,只在关键路标处取样。最自然的路标: 指针刚好走完一整圈的瞬间(即 是 的倍数)。
请你想一下:在这种” 整圈"的瞬间, 长什么样?只有几种可能?
🧑 Note: zzy (Me)
首先,这个 是 1-based 还是 0-based?我们姑且认为是 0-based 的吧,那么就是 , 不动保持为 0 可能的,已经移动了很多也是可能的吧?是我理解的有问题吗?
🤖 Note: Claude (Mentor)
对,按 0-based 走( 索引 ,初始 )。但" 走完整圈"不是 ,是 —— 你把"指针指到最后一个字符"和"指针走过最后一个字符再回到起点"混了:
- 第一步开始时 (指着 )。
- 经过 次 之后 ,此时 ,正好回到指着 —— 真正走完了一圈。
- 所以 anchor 时刻 (不是 )。
至于你说的 ,那部分理解完全对: 可以是 0(一动没动),也可以是任何已经走过的位置,所以 可以取 任一值。
合起来:anchor 时刻状态 ,第二个分量在 里取。
✅ anchor 状态可以被一个量完全刻画,恰好 种 —— 这就是我们要的 query 无关 态视角。
🤖 Note: Claude (Mentor)
继续推进。从当前 anchor 出发再走到下一个 anchor(即 再走完一整圈),这段时间里 一共增加了多少?换句话说,新 anchor 的 与旧的差多少?
🧑 Note: zzy (Me)
这个需要走一遍才知道吧?
🤖 Note: Claude (Mentor)
对,必须走一段才知道,这道题就是没法直接给出 增量的闭式 —— 得 simulate。但你这一句话其实已经暗含了完整算法的样子:先模拟、在每个 anchor 处把当前 记下来,等某个 第二次出现,就抓到了周期。
那下一个问题(一个):你打算让 simulate 跑到什么时候停下?也就是停止条件 / 跑完时手里都拿到了什么?
🧑 Note: zzy (Me)
这个好解决,使用记忆化就可以了,如果 的出现已经出现了周期性,就是已经回到了以前记忆化的点,那么就是找到了周期,就可以结束了。
🤖 Note: Claude (Mentor)
✅ 对的,停止条件就是 anchor 处的 第二次撞上 —— 周期抓到、可以结束。
那下一个问题(一个):simulate 跑的过程中,你打算把哪些数据存下来,使得后面任意一个 query 给一个 (可以到 ),都能 把得分算出来?
🧑 Note: zzy (Me)
在跑的过程中,vis 数组首先设置一个 ,然后主要是记录一下这个 点是第几次走到的即可。
🤖 Note: Claude (Mentor)
cycle detection 这部分对了(vis[j\_modN]存第几次走到,再次撞上就停)。但只这个还不够答 query —— 还要把得分本身记下来。
simulate 边跑边存的两个数组:
vis[j\_modN]:第几个 anchor 第一次走到 。第二次撞上就抓到周期。score[t]:第 个 micro-step 时的累积得分(前缀和,逐步累加 )。
假设 simulate 最终在第 步检测到周期、周期前缀长度 、周期长度 、一个完整周期得分增量 。那么对 query :
查询 ,precompute 量级( 至多到第 个 anchor,micro-step 数被段数 段长 bound 住)。
现在思路完整了:可以去写代码。建议:
- 主源文件放
src/Shift\_Game.cpp(与现有目录约定一致) - simulate 阶段就是个 while 循环,每步 ,遇到 anchor 时检查
vis - query 阶段直接套上面的分段公式
写完告诉我。
🧑 Note: zzy (Me)
确实还是要记录一手得分啊,这个主要是因为我们之前的重点都放在这个周期检测上了。
我有一个问题啊:纯模拟的话,这个时间复杂度是不是有问题呢?这完全有可能变成是 的吧。
🤖 Note: Claude (Mentor)
你抓得对。pure simulation 单段最差能到 ,整体 走不动。
极端例子: $A = $1010…(严格 0/1 交替), $B = $11…100…0(前半全 1 后半全 0)。 每次切字符, 都得跨过 中间的"块边界"才能找到下个匹配 —— 一次跨越 步。 一段内切换 次,总 。
注意上面那个例子的"罪魁": 严格 0/1 交替—— 每个位置都是"切字符",每次都强迫 重新跨过 的块边界。换个角度看:
问题:反过来,如果 里有连续相同字符的段(比如 $A = $11100100,开头有一段111),在这同字符段内部相邻的两个 A-advance 之间, 还需要 wait 吗?为什么?
🧑 Note: zzy (Me)
不需要啊,我们可以使用方法快进啊,就是把一整段看成一个数字,这样子每一次至少有一个段要前进。
🤖 Note: Claude (Mentor)
✅ 正中要害。run 内 不动 —— 处理一整个 run 只需要做一次"在 里找下个等于 run 字符的位置",run 里剩下的 A-advance 都是即时 match。
所以原本一段 A 整圈是 个 micro-step,现在压缩成 个 run-step( 的 run 数)。配一张" 里下一个 0/1 在哪"的辅助表,每个 run-step 是 ,单段 。
但这事还没完。再回头看那个最坏例子: $A = $1010…是严格交替, 。单段 ,cycle detection 至多 段 → 总 。run-collapse 没把屋顶顶破,只是把常数压下来了。
问题:现在的瓶颈是"一次 (一段 A 整圈)需要 次 复合"。能不能把一次 从 加速到 ?这样总复杂度变成 。提示:A 的 run 字符是严格 0/1 交替的——这意味着每次复合的两个 都是 这两个固定函数轮替。
🧑 Note: zzy (Me)
哦,我懂了,严格 交替的话,那么理论上来说,我们采用这个状态表示法,只需要知道 当前处于 0 还是 1, 当前处于 0 还是 1,那么就知道了之后的所有情况,因为后面是严格 0、1 交替的。
🤖 Note: Claude (Mentor)
✅ 你抓到了关键的一半:run 字符固定交替 → 首字符决定全部。
小偏差: 不是 0/1 二元, 是 的具体位置(你可能把" 这个位置"和" 这个位置上的字符"混了)。状态空间还是 个。
但"交替"这个性质不仅决定了 run 字符的排列,还有一个直接的算法学含义。
问题:把 的连续两个 run 处理看成一组(先做 再做 )。第 1 组(处理 run 0 + run 1)复合出的函数,和第 2 组(处理 run 2 + run 3)复合出的函数 —— 是不是同一个函数?为什么?
🧑 Note: zzy (Me)
我觉得啊,你说说看,你是不是过度数学化???你说这个东西和函数有什么关系啊???
🤖 Note: Claude (Mentor)
吐槽收到,“函数复合"这个词确实是装的——本质就是"跳法”。重说一遍:
处理一段 A 的 run,本质就是让 跳到 里下一个等于这个 run 字符的位置。跳法只看 run 字符是 0 还是 1,是个"给定起点 ,落到哪里"的固定规则。
把"连续处理两个 run"打包成一对:
- 第 1 对:先跳到下一个 ,再跳到下一个
- 第 2 对:先跳到下一个 ,再跳到下一个
- 第 3 对:…
重新提问:第 1 对的"跳法"和第 2 对的"跳法" —— 是不是完全一样?(“跳法”= 给定起点 ,结束时落在哪里的那个固定规则。)
🧑 Note: zzy (Me)
其实跳法就是,如果字符一样,就将 的这段 run 跳过,记分,如果字符不一样,就先跳过 的这段 run,那么就回到了第一种情况。
🤖 Note: Claude (Mentor)
✅ 对——跳法的逻辑只看字符匹配(equal / unequal),完全不依赖 pair 序号,所以第 1 对、第 2 对、…、第 100 对都是同一个规则。
🧑 Note: zzy (Me)
A run skip 应该是指跳过 嘛,那跳过 的话那么 指针肯定是没动的呀。
还有这个 ,我们之前讨论过吗?这都是什么东西?
🤖 Note: Claude (Mentor)
两条都对:
- “A run skip” 字面就是只跨 、 不动——你的解读对,我之前偷懒把 “A skip + B skip 预处理” 打包进同一个名字,不严谨。
- 我之前直接拿来用没定义,我的锅。
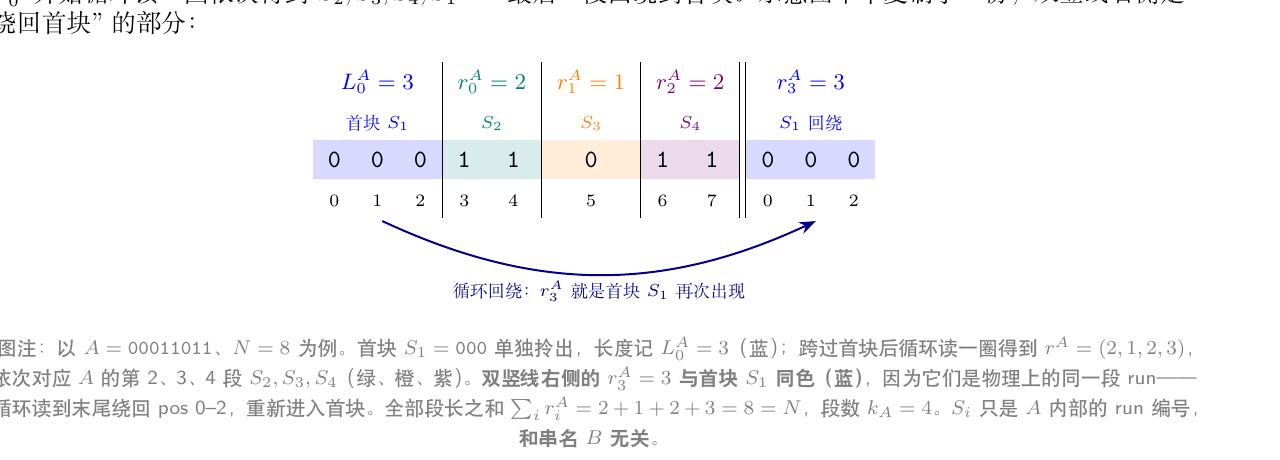
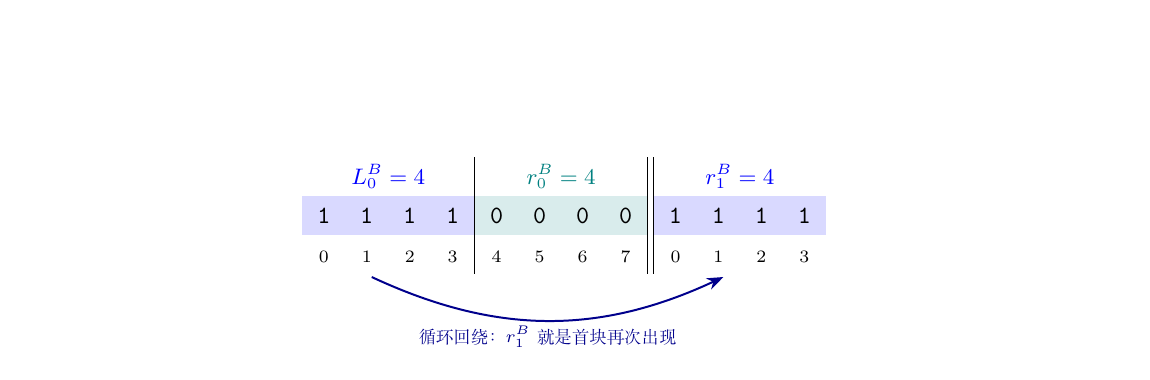
术语(统一一下): - 第 个 run 的长度; 第 个 run 的长度
- 第 个 run 的字符(0 或 1); 同理
- 的 run 数
把你之前描述的两个原子操作分别命名: - A run skip:状态字符相等时用, 、 不动、得分
- B run skip:状态字符不等时用, 、 不动、不得分
一个 round(从字符相等态起步) “A run skip” “B run skip”。
下一步问题:一个 round 让 一共推进了多少?写成 的形式。
🧑 Note: zzy (Me)
一个 round 让 推动了这个 啊, 。
🤖 Note: Claude (Mentor)
✅ 对。一 round 让 推进 ( 是 round 起始时 的 run 索引)。每 round 后 和 各 (分别模 )。
下一步问题: 一整圈 个 round。一整圈结束后 推进了多少?(用 求和表达。)
🧑 Note: zzy (Me)
如果是 个 round,那么就是加前 个 ,当然,这个 是循环往复的。
🤖 Note: Claude (Mentor)
✅ 对。一整圈结束后 推进 ( 跳了 次,每次过完 1 个 run,下标循环模 )。
下一步问题:query 给一个 (最坏 ),我们最终需要算" 个 round 之后的 ", 也可能到 。一个 round 的 transition 是 ,单次 ,但循环 次 完全过不去。怎么 算这个"同一个 transition 重复 次"的结果?
🧑 Note: zzy (Me)
你是想用倍增吗?但是我感觉倍增有点困难啊,因为这个每次的 都不一样,那么这个增量也不大好计算吧。
🤖 Note: Claude (Mentor)
你的直觉准。per-round 倍增的 state 必须能完整决定下一段 transition 增量:
- 增量 ,依赖
- 得分增量 ,依赖 和
所以 state ,空间 最坏 ,倍增表 存不下。
下一步问题:能不能换一个"更粗的 unit",让 state 空间变小?提示往"哪个量在固定 round 数之后会 reset / 回到原值"那个方向想。
🧑 Note: zzy (Me)
哦,我懂你的意思了, 肯定是不需要的,你的倍增表,第一维是这个 ,第二维是这个阶数,然后进行递推就好了。
🤖 Note: Claude (Mentor)
✅ 正中要害。“A 整圈”( 个 round)这个 unit 上:
- state 只剩 ( 在一个整圈内自动循环 ,是固定序列,不算独立 state)
- transition:
倍增表jump[ $k_B$ ][ $p$ ]存"从 出发、跳 个 A 整圈"之后的 。state 空间 、 层,总 ,能存。
下一步问题:写出递推:jump[ $k_B$ ][ $p+1$ ]怎么从jump[ $\cdot$ ][ $p$ ]算出来? 怎么合?
🧑 Note: zzy (Me)
这个之前我就已经想过了,就是最经典的倍增表转移:从jump[ $k_B$ ][ $p$ ]和jump[jump[ $k_B$ ][ $p$ ]. $k_B'$ ][ $p$ ]的地方转移, 应该直接加起来即可。
🤖 Note: Claude (Mentor)
✅ 经典递推没毛病。跳过这步,看更糙的 base case:jump[ $k_B$ ][0](一次 A 整圈,从 起步)。
前两个分量直接:
- $Delta j = $ 从 起 个连续 的循环求和 → 前缀和
下一步问题: 才是难的一块:
朴素对每个 算需要 , 个 总 ,不行。
怎么把每个 压到 ?提示:注意 和 都是严格 0/1 交替的(按 run 定义)。
🧑 Note: zzy (Me)
肯定也是没必要朴素计算的呀,知道 的字符 ,以及起始位置 块的 ,说白了,我们只需要看 中有多少个 是 1,把它们和长度乘起来加上去就可以了。
🤖 Note: Claude (Mentor)
方向对,但有一个小裂缝: 求和里是 两者都 ,不光看 。补一下:
都按同 parity 交替: 、 。所以两者要么 对所有 同时相等,要么 对所有 同时不等:
- 若 :AND 条件简化为 , ,其中 中 1 的总个数
- 若 :永远不可能同时 ,
所以 二选一,由 是否 决定。 每个 ,完美。
Preprocess 收尾:base case ,递推 。query 之前所有数据都齐了。
下一步问题:query 来了,给你一个 ( )。用jump表怎么走?描述一下流程(从 、 、 起步,到答案输出)。
🧑 Note: zzy (Me)
不对不对,你把问题复杂化了。一个 round 中 肯定会前进一次、 也肯定会前进一次,那么如果块的 是 1 的话,必定在 round 中加上块长这个答案。我说的难道不对吗?
🤖 Note: Claude (Mentor)
你完全对,我搞复杂了。 错在我隐含假设"round 永远是 A skip 先 B skip 后"这个顺序,但 case B( )起始 state unequal,要先做一次额外 B skip 才进入 round。这次 B skip 让 下标多偏 1,刚好抵消我担心的不匹配。重算:
case A( ,state 起始 equal):
- round 的 A skip 时 state (同 parity 交替对齐)
case B( ):- 额外 B skip 一次: , ,state 变 equal
- 之后 个 round 与 case A 同形:A skip 时 state
- 同样
所以 永远成立、不依赖 。倍增表里这一项是常量,甚至不必每个 单存。
补一句关于 :case A 是 个连续 的循环求和;case B 多一个起始 。处理上把 case B 的"额外 B skip"放在 binary lifting 之前单独算掉,之后均匀按 case A 走。
下一步问题(重发):query 给一个 。用jump表怎么走?描述完整流程(从初始 state 到答案输出)。
🧑 Note: zzy (Me)
不对啊,我们为什么要假设 round 有先后顺序呢?把 round 看成 " 走一步、 走一步",谁先谁后不重要,不行吗?
🤖 Note: Claude (Mentor)
对,你的抽象更省力。 把 round 看成 " 进 1 个 run 进 1 个 run",顺序无关:
- 推进 , 推进
- state 在每 round 起始处都是 equal(归纳:相等态下 , 各跨 run 后 仍相等)
- 所以 A skip 时 state ,得分
case A/B 唯一区别落在起始 state:case B 起始 state unequal,要先做一次 “pre-round B skip”(消耗 micro-step、 、不得分),把 state 调成 equal;之后 rounds 完全统一。
所以最终算法骨架:
- 起始 state unequal pre-round B skip 一次
- 倍增表跳大段(每段 rounds 1 个 A 整圈, 、 个连续 的循环和)
- 剩余预算落在某 anchor 内,用 round 级前缀和定位到具体 round
- 落在 round 内,判断 A skip 还是 B skip phase,算 partial score
下一步问题:query 给 ,用jump表怎么走?描述完整流程(从初始 state 到最终答案输出)。
🧑 Note: zzy (Me)
不是,我就是要纠正你,哪里来的 “pre-round B skip”?为什么要先走一步?按照我的抽象,这一步是可以忽略的呀。
🤖 Note: Claude (Mentor)
你完全对,“pre-round B skip” 是我多加的,抱歉。 在你的 atomic round 抽象下根本不需要它——round 这个原子单元已经包含了 “B 推进 1 + A 推进 1”,本来就涵盖了"B 先动"那次。我下意识把 “case B 起始 B 先 skip 然后 A skip” 翻译成 “preprocess + 后续 (A-first) round” 两步,但其实就是 round 内部的两步,端到端 (k_A, k_B, j, s) 结果和"一个 round"完全一致。
校正算法骨架:
- 无 preprocess,直接从 round 0 起步走 binary lifting
- 每 anchor( round): 、 个连续 的循环和(从当前 起)、
- Within last anchor partial:用 round 级前缀和定位到具体 round
- Within last round partial:唯一保留的 case 痕迹——case A(初始 state equal)round 内是 A skip 在前、case B 是 B skip 在前。不同顺序决定 partial 落在哪个 phase 上、得分是否要加 partial A skip 的贡献
下一步问题:query 给 ,用jump表怎么走?描述完整流程。
🧑 Note: zzy (Me)
跳吗就使用倍增常用流程,用全部的力气去跳,从高位到低位尝试,累加这个 ,如果累加 超过了 ,就说明超了,跳过这层。最后就是剩余 的一段东西了。
🤖 Note: Claude (Mentor)
✅ 经典倍增 query 模板:从高 到低 试jump[ $k_B$ ][ $p$ ],能塞进 就 take、否则 skip 这层。
小校正:累加比较的不是 ,是 (一次 jump 消耗的 micro-step 总数)。一次 anchor 跳里:
只算 指针推进的距离。 指针跑完每个整圈是 步、 个整圈就是 步。
倍增结束后剩 $K_text{remaining} < $ (一个 anchor 的 )。这意味着:剩 个完整 round 可能还有半个 round。
下一步问题:这剩下的 round 段怎么处理?用什么定位 落在哪个 round、然后落在该 round 的哪个 phase?
🧑 Note: zzy (Me)
这个 段确实没什么思路啊,可以再提示一下吗?
🤖 Note: Claude (Mentor)
提示:anchor 内 个 round,第 个 round 的 micro-step cost 是
你已知 严格小于这 个 cost 的总和。
问题归化成:给定一个长度 的非负序列,找 落在前缀和的哪一段。
下一步问题:用什么标准技巧 解?
🧑 Note: zzy (Me)
我懂了,你的意思是继续细分——从大 到小 ,小 之内就比较好解决了。这个可以用二分解决。
🤖 Note: Claude (Mentor)
✅ 二分 前缀 定位 round 。
配 前缀:
- 部分: (从 run 0 起的标准前缀和)
- 部分: (从 起 个 的循环和,用 配 floor / mod 算)
二分定到 round 后, 进一步缩到 round 内部( 个 round 的 partial )。这一 round 含 A skip B skip 两个 phase。
下一步问题:这两 phase 在该 round 内的顺序由什么决定? 落在第一个 phase 和落在第二个 phase 时,partial score 分别怎么算?
🧑 Note: zzy (Me)
循环前缀和实现上可以用 技巧解决。
partial score 分两种情况:
- unequal (case B):先 动、再 动。 动时若 则记分。 推进步数
- equal (case A):先 动、后 动。 动时若 则记分。 推进步数 (写错了,应是 )
🤖 Note: Claude (Mentor)
方向都对,两个小校正:
- equal 情形:A 推进步数 ,不是 。partial 还没满 时 A 只推进 partial 步、满了就推进 步、永远不超 。
- 技巧:把 拼成长度 的数组 、对它做 prefix sum ,则 对 直接成立(within-anchor 时 满足)。
至此算法链完整:
- preprocess( 、prefix_la、 prefix_lb、jump 倍增表):
- per query(determine case 倍增主循环 within-anchor 二分 within-round partial):
- 总:
时约 量级,1–2s 稳过。
下一步:去写代码,目标文件src/Shift\_Game.cpp。注意几个边界: - 全 0 / 全 1( 单调情形)
- 全 0 / 全 1( 单调情形)
- 起始 case 判断( ?)
- 边界(直接返回 0)
写完告诉我。
🧑 Note: zzy (Me)
书写过程中,是不是需要注意首段的特殊性?因为首段和末尾段不一定不同,可能出现字符趋同情况,破坏 0/1 严格交替的特性。
🤖 Note: Claude (Mentor)
漂亮的 catch,这是真实的边界,我之前漏了。
问题: (或 )当成线性串读 run 时,第一段和末尾段可能字符相同——但 实际是循环串,末尾 run 和开头 run 在循环视角下相邻,应合并成一个循环 run。否则会出现 这种"两个相邻同色 run",破坏前面所有" 严格 0/1 交替"的归纳前提。
例: $A = $00110,线性 runs , (奇)。循环视角下末尾的0和开头的00应合并成000,循环 runs , (偶)。
处理:preprocess 时检查 ?
- 是:合并线性末尾 run 和第一个 run, ,新 $la[0] = $ 末段长 首段长
- 否:直接用线性 runs
合并后 必为偶(或 当 单色)。 同理。 一次性处理,不影响主算法复杂度。
边界清单补一条进去,继续去写代码。
🧑 Note: zzy (Me)
(待回答 …)
心路历程(WA → TLE → AC)
最初的代码是按这份 mentor.tex 推导出来后写出来的。提交三次才稳:
-
🐛 WA(提交 1268875897)—— 倍增表外层循环写反:原写法外层
i内层p,但递推jump[i][p] = jump[i][p-1] ∘ jump[jump[i][p-1].blockB][p-1]读到的jump[i'][p-1]在 i’ 那行还没轮到时是默认 0,jb / score 双重少算。对拍 seed 11 命中,K=45 应得 16 实出 11。修:把外层换成for (int p = 1; p < LEV; ++p)。教科书级倍增坑。 -
🐛 WA 同发现:「B 全 1、A 非常数」特判分支从「A 全 1」分支复制粘贴错——内层条件
if (B[0] == '1')永真,把所有 K 直接吐出。正确逻辑:B 永远 = 1,A 走到第一个 0 就卡死,得分 =min(K, la0)(A 前导 1 的长度)或 0(A 前导 0)。 -
⏱️ TLE(提交 1268882247)—— 修对算法后 subtask 1/2 卡 3.01s。三处常数:(a)
vector<vector<BlScJb>>(Rb, vector<BlScJb>(42))是 Rb=10⁶ 次小堆 alloc + 24MB vector header;(b) cal_ans 用i128比ull慢 2-3×(实测求和上界 4×10¹⁸ 仍在 ull 内);© 42 层倍增写死,N=10⁶ 时其实 21 层够用(2^p · N > K_max的层根本 take 不到)。 -
✅ AC 1268899055:层主序单块 alloc
vector<BlScJb> jump(LEV * Rb)、ull替换i128、LEV 自适应。本机 N=Q=10⁶ 接近全交替最坏 case 0.9~1.0s,CodeChef 全 13 subtask 通过。
📌 教训提炼:
-
倍增 / ST 表,外层永远是 level p,先填整层再算下一层
-
对拍是检测算法 bug 的硬通货——上一轮没对拍只看代码漏掉了
-
WA 修完先看 TLE 风险:i128 / 嵌套 vector / log 层数硬编码都是常数因子噩梦
AC 代码
提交记录:
-
WA → 1268875897(倍增循环序错)
-
TLE → 1268882247(i128 + 嵌套 vector 太重)
-
AC → 1268899055(层主序单块 alloc + ull + 自适应 LEV,全 13 subtask 通过)
源码 Shift_Game_clean.cpp 见本节下方折叠块(由 raw API 附加)。
📎 附件
mentor.pdf—— 完整带教对话录的 PDF 编译版(见末尾 PDF 块)