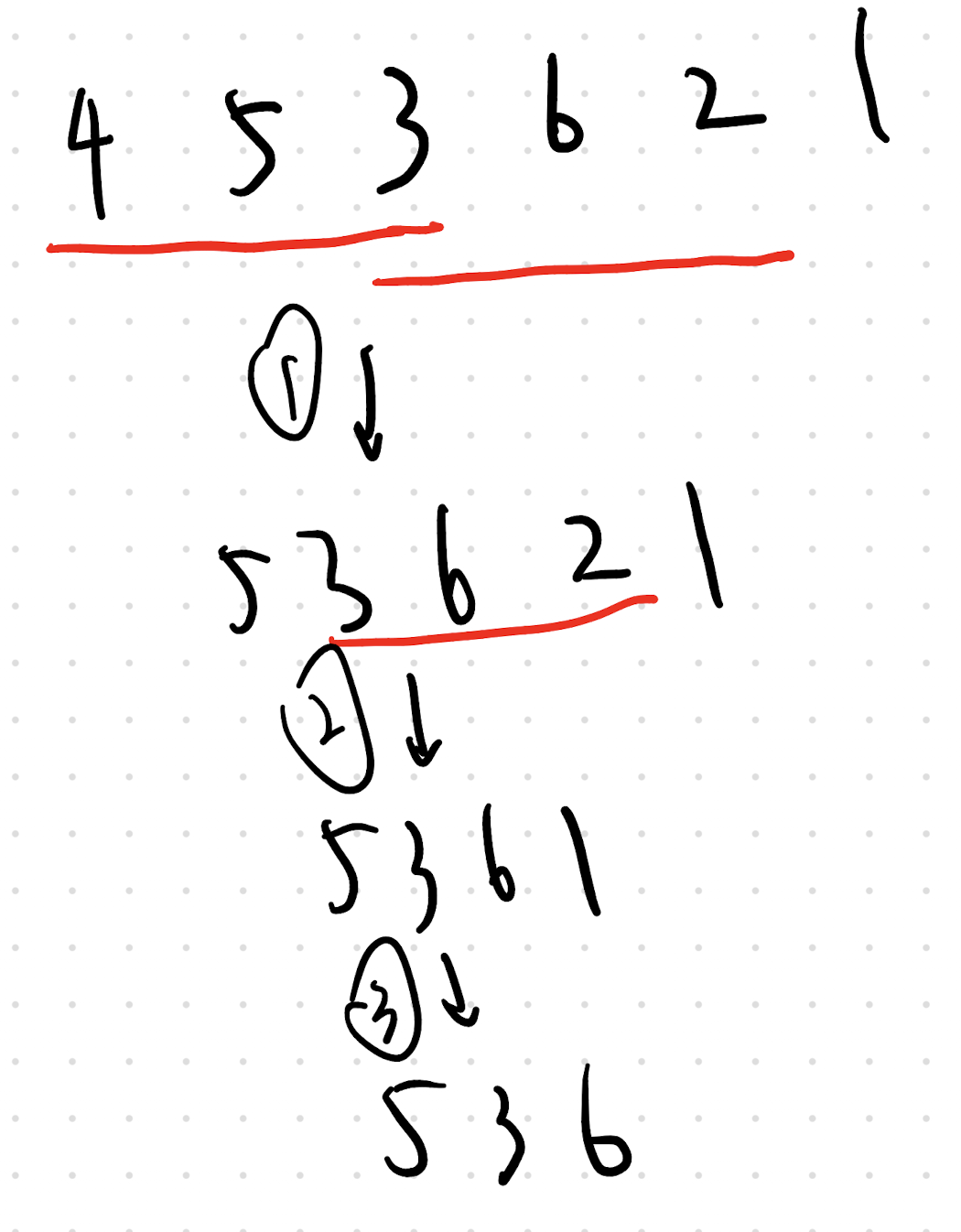题目大意
题目描述
给定一个长度为 的目标数组 。
现有一个与 等长的初始数组 ,对 进行恰好一次如下操作:
选择一个整数 ,并将数组 划分为 个连续且不重叠的子段。假设这 个子段的下标区间依次为 ,满足 ,,且对于所有的 ,都有 。
然后,对这 个子段分别独立地进行翻转操作。
即,选择的区间形如:

请求出有多少种不同的初始数组 ,可以通过上述操作变为目标数组 。由于答案可能很大,请输出其对 取模后的结果。
输入格式
第一行包含一个整数 (),表示测试用例的数量。
每组测试用例的第一行包含一个整数 (),表示数组的长度。
第二行包含 个整数 (),表示目标数组 的元素。
保证所有测试用例中 的总和不超过 。
输出格式
对于每组测试用例,输出一个整数,表示满足条件的数组 的数量对 取模后的结果。
样例输入
1 | 5 |
样例输出
1 | 4 |
样例解释
在第一组测试用例中,,以下 种数组 可以被转换为 :
-
对于 ,可以选择区间 和 进行翻转。翻转后数组变为 ,等于 。
-
对于 ,可以选择区间 进行翻转。
-
对于 ,可以选择区间 、 和 进行翻转。
-
对于 ,可以选择区间 和 进行翻转。
在第二组测试用例中,,以下 种数组 可以被转换为 :
-
对于 ,可以选择区间 和 进行翻转。
-
对于 ,可以选择区间 、 和 进行翻转。
-
对于 ,可以选择区间 、、 和 进行翻转。
-
对于 ,可以选择区间 进行翻转。
-
对于 ,可以选择区间 和 进行翻转。
-
对于 ,可以选择区间 、 和 进行翻转。
-
对于 ,可以选择区间 和 进行翻转。
思路讲解
分析 rev 操作的一个重要公式是:
可以继续拓展:

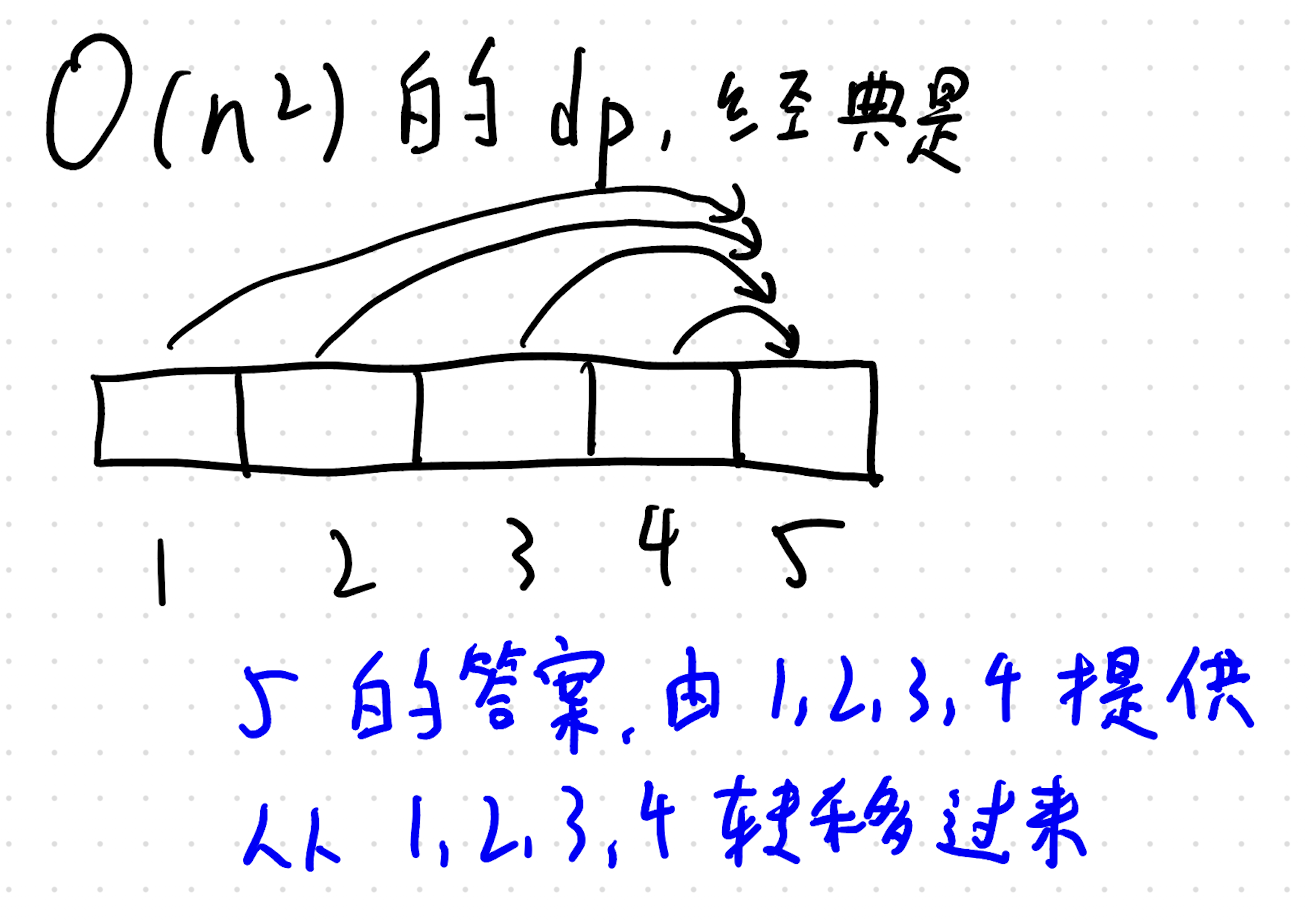
所以,我们要求转移时前缀相同,只采用这一后缀,即可得到独特的计数。
具体来讲,我们对这一后缀的要求是(在前缀相同的情况下)这一后缀无论如何划分,都达不到整体的效果。
1 | rev(S) != rev(任意对S的划分方法) |
比如说 [1, 2, 3, 4] 任何其他划分方式都达不到 rev([1, 2, 3, 4]) 的效果。




不过上面,opus4.6 给出的解释实际上不是很令人满意,因为带有非常明显的知道答案,凑出证明的痕迹。我们采用一种更加好的方法?(可能没有那么严谨,但是实际上是严谨的)

P4391 [BalticOI 2009] Radio Transmission 无线传输
我们不难发现,可以这种所谓的查找目标 ,其实就是查找周期,其实和查找周期的哈希实现一模一样(详见上面一道题目)。

相信看了我的这个解释,应该都能看出来这个东西。
其实,形如 ,其实是唯一一种形式,可以保证分段反转等于整体反转。
不过快速检查一个字符串是否有真前后缀相同,显然是使用 kmp(前缀数组,前缀数组就是这么定义的,能不好吗?) 还是比较好的,使用字符串哈希时间复杂度不是很优秀。
好,现在问题就来到了,我们怎么样求 是否有这个真前后缀匹配情况?

哈哈,其实解决这个问题的方法也很简单,那么就是跑 n 遍 kmp 就可以了,这道题目不是 的嘛。绷不住了。
1 | vector<ll> kmp(ll N,const vector<ll> &A){ // 返回总前缀数组pi |
最后的这个 dp 代码:
1 | for (int l=1;l<=N;++l) { |
AC代码
AC
https://codeforces.com/contest/2205/submission/365177121
这个代码跑的好快啊,竟然
1 | /** |
心路历程(WA,TLE,MLE……)
要好好想清楚这个 dp 是从哪里转移过来的,是从 l-1 转移过来的。
1 | for (int l=1;l<=N;++l) { |
下面是废掉的 AI 提示
题意转化
题目要求:给定目标数组 ,有多少个不同的初始数组 ,使得存在某种将 切成若干连续段后分别翻转能得到 。
由于"分段翻转"是自逆操作(对同一分段再做一次翻转就还原), 能变成 当且仅当 用同样的分段翻转能变成 。因此问题等价于:
把 切成若干连续段并分别翻转,能得到多少种不同的数组?
核心观察:何时两种切法产生同一结果
设切法 1 的最后一段是 ,切法 2 的最后一段是 ()。经过推导可知,它们在位置 到 上的值相同当且仅当:
即子串 具有周期 。
关键引理:非本原段可以缩短
若 具有周期 (即该子串不是"本原的"),则所有以 为最后一段能产生的结果,都能通过以 为最后一段来实现。
证明思路:将最后一段 的前 个字符"吸收"到前缀中——由于周期性,这前 个翻转后的值恰好等于对 的某种合法分段翻转结果(具体地,用切点 把它分成两段,其中 )。
推论:本原段之间不产生重复
若两个最后一段 和 都是本原的(最小周期等于自身长度),则 时它们产生的结果集合完全不交。因为若有交集,较长的那个子串就会有周期 ,与本原性矛盾。
DP 公式
设 为 能产生的不同结果数。由以上分析:
其中 。每一项互不重叠,无需容斥。
如何判断本原性
子串 是本原的当且仅当它的最小周期等于其长度。利用 KMP 的失配函数(failure function):长度为 的字符串的最小周期为 ,因此本原等价于 。
对于固定的终点 ,我们考虑反串 ,则子串 对应 的前缀 。对 跑一次 KMP 即可得到所有前缀长度 处的 ,从而判断哪些 对应本原段。
复杂度
对每个 ,KMP 和求和各 ,总复杂度 。,完全可行。
这是个好问题,我来讲清楚。
你的疑惑
证明"非本原段可被更短段覆盖"时,我们说:
切法 1(最后一段 )和切法 2(最后一段 )给出同一个结果 。
你的疑问是:“这要求两个切法的前缀部分产生相同的值,但 dp 本身在数不同的结果,这不矛盾吗?”
其实不矛盾,因为两个前缀是不同长度的对象
关键: 和 不是同一个东西。
- :是 的某个结果(长度 )
- :是 的某个结果(长度 )
是从 扩展出来的:保留 的前 个位置,再附加 的某种分段翻转结果。
用样例 1 具体看
,,,,。
切法 1:最后一段 ,前缀为空。
切法 2:最后一段 ,前缀是 的某个结果。
要得到同一个 :
- 位置 4 ✓(周期条件保证 )
- 前缀 必须
问题: 是 的一个合法结果吗?
是的!用分段 :。✓
所以 确实存在于 中。不需要"凭空创造",它本来就是 的 个结果之一。
逻辑链条
整个推理没有循环:
- 给定一个具体的结果 ,它来自非本原的最后一段
- 我们构造一个 :把 后面接上 的一种特定分段翻转
- 由于分段翻转是合法操作, 一定是* 的一个可达结果*(它在 中)
- 由于周期条件,(同一个结果)
- 所以 已经被更短的最后一段 覆盖了
不需要假设"前缀相同"—— 是从 推导构造出来的,不是假设出来的。而且 (长度 )和 (长度 )是不同长度的前缀,不存在"不允许相同"的问题。
好的,我用前三个样例来逐步模拟。
回顾算法核心
- (空前缀,一种结果)
- 对每个终点 ,构造反串 ,对 求 KMP 失配函数
- 的前缀长度 对应子串 (即以 结尾、长度为 的最后一段)
- 意味着该子串是本原的(最小周期 ),对 有贡献
- 意味着存在更短周期,该段产生的结果被更短段"覆盖",跳过
样例 1:,答案
:
| 本原? | 对应子串 | |||
|---|---|---|---|---|
| 1 | 0 | 是 |
:
| 本原? | 对应子串 | |||
|---|---|---|---|---|
| 1 | 0 | 是 | ||
| 2 | 1 | 否 | ,周期 1 | |
| 时 有周期 1(两个字符相同),非本原,跳过。 |
含义: 无论怎么切(切或不切),翻转后都是 ,只有 1 种结果。
:
| 本原? | 对应子串 | |||
|---|---|---|---|---|
| 1 | 0 | 是 | ||
| 2 | 0 | 是 | ||
| 3 | 0 | 是 | ||
| 三段都是本原的! |
含义: 的三种不同结果是:
- 最后一段 ():前缀 有 种结果
- 最后一段 ():前缀 有 种结果
- 最后一段 ():前缀为空, 种
:
| | | | 本原? | 对应子串 | 说明 |
| — | — | — | — | — | — |
| 1 | | 0 | 是 | | |
| 2 | | 0 | 是 | | |
| 3 | | 1 | 否 | | 周期 2() |
| 4 | | 1 | 否 | | 周期 3() |
: 的前缀 等于后缀 ,,最小周期 ,非本原。这意味着用 做最后一段的所有结果,都能被更短的最后一段覆盖。
: 的前缀 等于后缀 ,,最小周期 ,非本原。同理跳过。
验证:4 种不同的 分别是:
- 最后一段 (),前缀 有 3 种结果
- 最后一段 (),前缀 有 1 种结果
共 4 种。
样例 2:,答案
: ,fail。。
: ,fail。两段都本原。
(:切或不切给出 和 ,2 种结果)
: ,fail。三段都本原(所有字符互不相同)。
:
| 本原? | 对应子串 | |||
|---|---|---|---|---|
| 1 | 0 | 是 | ||
| 2 | 0 | 是 | ||
| 3 | 0 | 是 | ||
| 4 | 1 | 否 | ,周期 3() | |
| 只有 被排除(整段 有周期 3)。 |
验证:7 种 的来源:
- 最后一段 ():前缀 有 4 种 4 个
- 最后一段 ():前缀 有 2 种 2 个
- 最后一段 ():前缀 有 1 种 1 个
,且这三组之间无重复(因为每组的最后一段是本原的,不同本原段不产生交叉)。
样例 3:,答案
更快速地走一遍:
| fail 数组 | 本原的 值 | DP 转移 | |||
|---|---|---|---|---|---|
| 0 | — | — | — | — | 1 |
| 1 | 1 | 1 | |||
| 2 | 1, 2 | 2 | |||
| 3 | 1, 2, 3 | 4 | |||
| 4 | 1, 2, 4 | 7 | |||
| 5 | 1, 3, 5 | 10 | |||
| 6 | 1, 2, 3, 6 | 22 | |||
| 最后一行详细解释: | |||||
| ,KMP 失配函数: |
- :,前缀 = 后缀 ,,周期 ——对应 有周期 3(),非本原,跳过
- :,前缀 = 后缀 ,,周期 ——对应 有周期 3(,),非本原,跳过
最终:
直觉总结
每一步的逻辑可以这样理解:
- 要计算 ,我们枚举"最后一段"的长度 ,即 。
- 如果这一段是本原的(没有更短的周期),它产生的结果是"全新的",不会和其他长度的最后一段重复。贡献 。
- 如果这一段非本原(有周期 ),说明它的效果能被更短的最后一段完全覆盖——直觉上,多余的"重复部分"可以被吸收进前缀中用另一种合法切法表达。所以跳过,避免重复计数。
- 不同的本原最后一段之间绝不产生重复:若两个本原段产生了相同结果,较长的那个就会出现周期,与本原性矛盾。
所以整个 DP 既不遗漏也不重复,恰好精确计数。
好的,我用样例 1()来把这件事彻底讲清楚。
一、什么是"本原"
子串 是本原的,就是说它不存在比自身长度更短的周期。
具体几个例子(都来自样例 1):
- :(),没有周期 1。最小周期 长度。本原。
- :,有周期 1 。非本原。
- :,有周期 2 。非本原。
- :,有周期 3 。非本原。
二、非本原段为什么不贡献——用具体例子看"冗余"
例子 A:,周期 2,非本原
我们在计算 时,考虑最后一段 (,)。
用 做最后一段时:
- 位置 2, 3, 4 的值
- 前缀 只有 种结果
- 唯一产生的完整结果:
现在我来证明,这个结果已经被更短的最后一段覆盖了。
用 做最后一段(,): - 位置 4 的值
- 前缀 有 种结果
的 3 种结果之一:用分段 ,得 。
拼起来: —— 和上面一模一样!
所以最后一段 的唯一贡献 已经被最后一段 包含了。如果我们同时计算两者,就会重复计数。
为什么这行得通? 关键就在周期。 有周期 2,意味着 。
对比两种最后一段在位置 4 上的表现: - 最后一段 :位置 4 得到的是 (翻转后,段首跑到段尾)
- 最后一段 :位置 4 得到的是
正是周期条件保证的! 这使得位置 4 的值一致。而被"多出来"的位置 2, 3 则可以交给前缀去处理——用 的某种分段来产生需要的 。
例子 B:,周期 3,非本原
用 做最后一段(整段翻转):
- 结果
这能被更短的最后一段覆盖吗?周期 ,所以对应更短的最后一段 。
用 做最后一段: - 位置 4
- 需要前缀
能产生 吗?用分段 :。可以!
拼起来: —— 又是同一个结果!
核心机理相同: 有周期 3,意味着 。所以位置 4 上:长段给出 ,短段给出 ,一致。多出来的位置 1, 2, 3 交给前缀来处理。
三、本原段为什么能贡献——它的结果是"全新的"
例子 C:,本原
用 做最后一段(,):
- 位置 3, 4
- 前缀 有 种结果
- 唯一结果:
这个结果能不能被最后一段 ()覆盖?
用 :位置 4 。
但我们需要位置 4 (来自 翻转后的 )。
,不可能! 所以 绝不可能从最后一段 产生。
根本原因:要想让 和 在位置 4 上给出相同的值,需要 (即周期 1)。但 。 是本原的,没有周期 1。所以两种最后一段在位置 4 上必然给出不同的值,从而产生不同的结果。
四、总结原理
对于最后一段 (长度 ),考虑"更短一截"的最后一段 (长度 ):
两者在位置 到 的重叠区域上:
- 长段 翻转后,位置 得到
- 短段 翻转后,位置 得到
两者相等要求:
这恰好就是周期 的定义!
所以:
- 有周期 (非本原) 重叠区域值完全一致 多出来的 个位置可以交给前缀处理 长段的所有结果都被短段覆盖 不贡献(计入则重复)
- 没有任何周期 (本原) 对任何更短的段,重叠区域上至少有一个位置值不同 结果一定不同 贡献是全新的
这就是为什么 DP 转移中只统计本原段:本原 = 不可替代 = 贡献新结果,非本原 = 可以被更短段覆盖 = 已经被计算过了。
这个问题有一个非常优雅的数学观察。
核心:交换两块
设在 中,切点在 。令:
那么:
- 分段翻转的结果 (先放 再放 )
- 整体翻转的结果 (这是翻转拼接的标准性质:)
所以问题变成:
即:两个字符串是否在拼接运算下交换。
字符串交换的经典定理
有一个经典结论:
两个非空字符串 和 满足 ,当且仅当存在一个字符串 ,使得 ,()。
也就是说, 和 必须都是同一个基本串的若干次重复。
用具体例子感受
例子 1:,切点 。
,显然 。(,)
验证:分段翻转 ,整体翻转 。相等 ✓
例子 2:(样例 1 中),切点 。
,。。
和 不是同一个基本串的幂次(因为长度 2 和 1 的公共基本串只能长度 1,那就要求 ,但 ),所以不交换 ✓
例子 3:,切点 。
,,。所以 。
验证:,。相等 ✓
等价的周期条件
也可以翻译成周期语言:
设 ,。则:
这是因为"两块能交换"等价于整个串由一个长度为 的基本单元循环构成。
实际计算方法
在代码中,判断"分段 rev 整体 rev"最实用的方式是字符串哈希:
对 预处理多项式哈希(前缀哈希 + 逆序前缀哈希),就可以 比较任意子串、翻转子串。具体地:
- 计算 :用 的哈希和 的哈希拼接
- 计算 :用 的哈希和 的哈希拼接
- 两者相等则分段 rev 整体 rev
或者更直接地:检查 对所有 是否成立(周期 条件),同时检查 对所有 是否成立(周期 条件)。两个条件都满足才行。
总结:分段翻转和整体翻转是否相同,本质上就是问两个翻转后的块能否交换顺序,即 。这当且仅当 和 是同一个基本串的幂次,也等价于整个子串有周期 。
P4391 [BalticOI 2009] Radio Transmission 无线传输
计算这个串的周期所使用的这个哈希做法。
首先呢,计数问题,还是要选择 dp 解决。
问题转化
由于翻转操作是对称的,将初始数组 划分为若干段并分别翻转得到目标数组 ,完全等价于将 按照完全相同的划分方式进行分别翻转,从而得到 。因此,原问题可以转化为:对于给定的数组 ,将其划分为任意个连续子段并分别翻转,能够产生多少种不同的数组 。
分析重复情况与核心结论
如果我们随意对 进行划分并计算结果,会遇到“不同的划分方式产生相同数组 ”的情况。
例如,设当前段为 [1, 2, 3, 1],如果将其作为一整段翻转,会得到 [1, 3, 2, 1];但如果我们将其划分为 [1]、[2, 3]、[1] 三段分别翻转,拼起来的结果依然是 [1, 3, 2, 1]。
发生这种等价替换的根本原因在于:当某一段序列存在一个“前缀等于后缀”(在字符串理论中被称为 Border)时,对其整体翻转的结果,必定等价于将其拆分为更小块分别翻转的结果。
可以证明,为了避免重复计数,我们只需要在所有的划分方案中,只统计那些所有子段都“无 Border”的划分。无 Border 的定义是:对于长度为 的子段,不存在一个长度介于 到 之间的前缀,与相同长度的后缀完全相等。
任意一个能够通过翻转生成的合法数组 ,都存在且唯一存在一种完全由“无 Border”子段构成的划分方案。因此,所求的合法数组 的数量,恰好就等于将数组 划分为若干个“无 Border”子段的合法方案数。
动态规划设计
基于上述结论,我们可以使用一维动态规划来解决。
定义 dp[i] 表示将数组 的前 个元素划分为若干个无 Border 子段的方案数。
初始化时 dp[0] = 1,其余为 。
当我们要从状态 dp[i] 向后转移时,我们需要寻找所有合法的右端点 。条件就是:从 到 构成的子段必须是无 Border 的。如果满足,则执行状态转移:
dp[j] = (dp[j] + dp[i]) % 998244353
借助 KMP 算法加速判断
如何快速判断区间是否存在 Border?这恰好是 KMP 算法中求解前缀函数 pi 数组的核心作用。
pi[k] 存储的是前缀子串中最长的“真前缀等于真后缀”的长度。如果 pi[k] == 0,就意味着当前这一段子串不存在任何 Border。
因此,我们可以这样做:
- 外层循环枚举划分的左端点 (从 到 )。
- 如果 dp[i] == 0,直接跳过以优化常数。
- 否则,将 从 到 的剩余部分作为一个新的模式串,对其运行 KMP 算法求解 pi 数组。
- 在计算 pi 数组的过程中,对于当前长度 ,只要发现对应的 pi 值为 ,就说明从 开始、长度为 的这一段是无 Border 的,立刻将 dp[i] 的值累加到对应的 dp[i + k] 上即可。
复杂度分析
外层遍历左端点 ,共执行 次。每次针对剩余后缀计算 pi 数组时,KMP 算法的复杂度为线性的 。
因此整体的时间复杂度为 。题目给定的所有测试用例的 之和 ,其平方规模在 左右,在 2 秒的时限内可以非常高效地通过。空间复杂度仅需维护 dp 数组和单次 KMP 的 pi 数组,为 。
不过总体上来说,我们对 border 的概念不是很熟。
确实,这道题目的难点就在于,对于不同的划分,如果有相同的这个答案怎么办?这个时候就需要引入字符串算法。
Border 的定义
在序列(如字符串或数组)中,如果该序列的一个非平凡前缀(即长度大于 且小于序列总长度的前缀)和它的一个非平凡后缀完全相同,那么这个相同的前缀或后缀就被称为该序列的一个 Border。
举个具体的例子:考虑数组 [1, 2, 4, 5, 1, 2]。
这个数组长度为 。取它的前缀 [1, 2],再取它的后缀 [1, 2],两者完全相同。因此,[1, 2] 就是这个数组的一个 Border。
Border 对计数产生重复的具体机制
题目要求我们计算能生成多少种不同的初始数组 。如果我们在动态规划中不加任何限制,直接枚举所有可能的划分方式,就会把“产生相同最终数组的不同划分方式”重复计算。
我们继续以数组 [1, 2, 4, 5, 1, 2] 为例。假设它是目标数组 里的某一个连续子段。现在我们要对这一段进行划分并分别翻转。观察以下两种截然不同的划分方式:
划分方案一:作为一个整体翻转
我们将 [1, 2, 4, 5, 1, 2] 视为单独的一大段,整体进行一次翻转操作。
翻转后的结果是:[2, 1, 5, 4, 2, 1]。
划分方案二:沿着 Border 将其拆分后分别翻转
我们把这段数组拆分成三小段,分别是:前缀 Border、中间剩余的部分、后缀 Border,即拆分为 [1, 2]、[4, 5]、[1, 2]。
我们对这三个小段分别独立进行翻转:
第一段 [1, 2] 翻转得到 [2, 1];
第二段 [4, 5] 翻转得到 [5, 4];
第三段 [1, 2] 翻转得到 [2, 1]。
最后,把这三段翻转后的结果原样拼接起来,得到的结果依然是:[2, 1, 5, 4, 2, 1]。
可以看出,不同的划分方式(整体分 段对比拆分成 段)最终产生了一模一样的生成数组。如果不加干预,这两种划分方案都会被统计入总方案数中,对于同一个合法的数组 ,我们就进行了重复计数。
将现象抽象化
为什么只要存在 Border 就会发生这种情况?
我们可以把任意存在 Border 的序列抽象地表示为 (其中 是 Border 代表的子段, 是中间夹着的子段, 表示拼接操作)。
如果我们把它作为整体翻转,得到的是 。根据翻转操作的数学性质,把一个拼接序列整体翻转,等价于把原序列从后往前依次翻转拼接,即结果为 。
如果我们把它拆分成三段分别翻转并拼接,结果显然也是 。
这就推导出了一个核心结论:只要某一段序列内部存在 Border,那么把这段序列“整体翻转”所产生的效果,总是可以被“沿着 Border 切分成更小的块并分别翻转”的效果完全替代。
消除重复的最终策略
既然“存在 Border 的大段”总是可以被等价替换为“没有 Border 的小段组合”,那么为了做到不重不漏,我们需要为每一种生成的最终数组 寻找一个唯一代表它的划分方式。
我们的强制规定就是:在所有能产生同一个结果 的划分方案中,我们只统计那种“被拆分得最细”的方案。
什么样的方案是拆得最细的?就是划分出来的每一小段序列,都不存在任何 Border。
因为一旦某个子段没有 Border,它就绝对无法再被拆解为类似于 的形式,也就意味着它“作为一个整体翻转产生的结果”,绝对无法通过“拆分成更小的几段分别翻转”来伪造。
可以从数学上严谨证明,任意一个能够通过翻转操作生成的合法数组 ,都存在且仅存在一种完全由“无 Border 子段”构成的划分方式。因此,只要在动态规划转移时,严格限制划分出来的每一段都必须没有 Border,我们计算出的方案数就恰好等于最终生成的不同数组 的数量,从而达到了去重目的的不同数组 的数量。
好的,我们对样例 6 \\n 1 3 2 3 3 2 进行详细的算法模拟。
目标数组 ,长度 。
我们使用一维 DP,dp[i] 表示将 的前 个元素划分为若干个无 Border 子段的方案数。
初始化:dp[0] = 1,其余 dp[1...6] = 0。
第一步:以 为左端点进行拓展
当前 dp[0] = 1。我们需要考察从下标 开始的后缀 。
对此后缀运行 KMP 求 pi 数组(注:为方便描述,这里子串内索引用 开始,对应原数组 的前缀长度 ):
| 长度 | 当前子串 | KMP pi[k] |
pi[k] == 0? |
DP 转移操作 |
|---|---|---|---|---|
[1] |
是 | dp[1] += dp[0] dp[1] = 1 |
||
[1, 3] |
是 | dp[2] += dp[0] dp[2] = 1 |
||
[1, 3, 2] |
是 | dp[3] += dp[0] dp[3] = 1 |
||
[1, 3, 2, 3] |
是 | dp[4] += dp[0] dp[4] = 1 |
||
[1, 3, 2, 3, 3] |
是 | dp[5] += dp[0] dp[5] = 1 |
||
[1, 3, 2, 3, 3, 2] |
是 | dp[6] += dp[0] dp[6] = 1 |
||
本轮结束状态:dp = [1, 1, 1, 1, 1, 1, 1] |
第二步:以 为左端点进行拓展
当前 dp[1] = 1。考察从下标 开始的后缀 。
| 长度 | 当前子串 | KMP pi[k] |
pi[k] == 0? |
DP 转移操作 |
|---|---|---|---|---|
[3] |
是 | dp[1+1] += dp[1] dp[2] = 2 |
||
[3, 2] |
是 | dp[1+2] += dp[1] dp[3] = 2 |
||
[3, 2, 3] |
(Border:[3]) |
否 | 无操作 | |
[3, 2, 3, 3] |
(Border:[3]) |
否 | 无操作 | |
[3, 2, 3, 3, 2] |
(Border:[3, 2]) |
否 | 无操作 | |
本轮结束状态:dp = [1, 1, 2, 2, 1, 1, 1] |
第三步:以 为左端点进行拓展
当前 dp[2] = 2。考察从下标 开始的后缀 。
| 长度 | 当前子串 | KMP pi[k] |
pi[k] == 0? |
DP 转移操作 |
|---|---|---|---|---|
[2] |
是 | dp[2+1] += dp[2] dp[3] = 4 |
||
[2, 3] |
是 | dp[2+2] += dp[2] dp[4] = 3 |
||
[2, 3, 3] |
是 | dp[2+3] += dp[2] dp[5] = 3 |
||
[2, 3, 3, 2] |
(Border:[2]) |
否 | 无操作 | |
本轮结束状态:dp = [1, 1, 2, 4, 3, 3, 1] |
第四步:以 为左端点进行拓展
当前 dp[3] = 4。考察从下标 开始的后缀 。
| 长度 | 当前子串 | KMP pi[k] |
pi[k] == 0? |
DP 转移操作 |
|---|---|---|---|---|
[3] |
是 | dp[3+1] += dp[3] dp[4] = 7 |
||
[3, 3] |
(Border:[3]) |
否 | 无操作 | |
[3, 3, 2] |
是 | dp[3+3] += dp[3] dp[6] = 5 |
||
本轮结束状态:dp = [1, 1, 2, 4, 7, 3, 5] |
第五步:以 为左端点进行拓展
当前 dp[4] = 7。考察从下标 开始的后缀 。
| 长度 | 当前子串 | KMP pi[k] |
pi[k] == 0? |
DP 转移操作 |
|---|---|---|---|---|
[3] |
是 | dp[4+1] += dp[4] dp[5] = 10 |
||
[3, 2] |
是 | dp[4+2] += dp[4] dp[6] = 12 |
||
本轮结束状态:dp = [1, 1, 2, 4, 7, 10, 12] |
第六步:以 为左端点进行拓展
当前 dp[5] = 10。考察从下标 开始的后缀 。
| 长度 | 当前子串 | KMP pi[k] |
pi[k] == 0? |
DP 转移操作 |
|---|---|---|---|---|
[2] |
是 | dp[5+1] += dp[5] dp[6] = 22 |
||
最终状态:dp = [1, 1, 2, 4, 7, 10, 22] |
模拟结论
遍历结束后,我们将整个数组 (长度为 )划分为若干个无 Border 子段的总方案数,即为 dp[6]。
模拟得出的 dp[6] 的值为 。
对比题目样例:
1 | 6 |
样例输出恰好为 22。算法模拟过程严丝合缝地吻合了正确答案。
众所周知,计数题目,必须要找到一种方法,一种特征,保证符合这一特征的划分方式/方案之间是独立,互不相同的。这道题目的特征如下:(注意,我们认为单一字符符合这个要求,毕竟递归需要有一终止条件嘛)
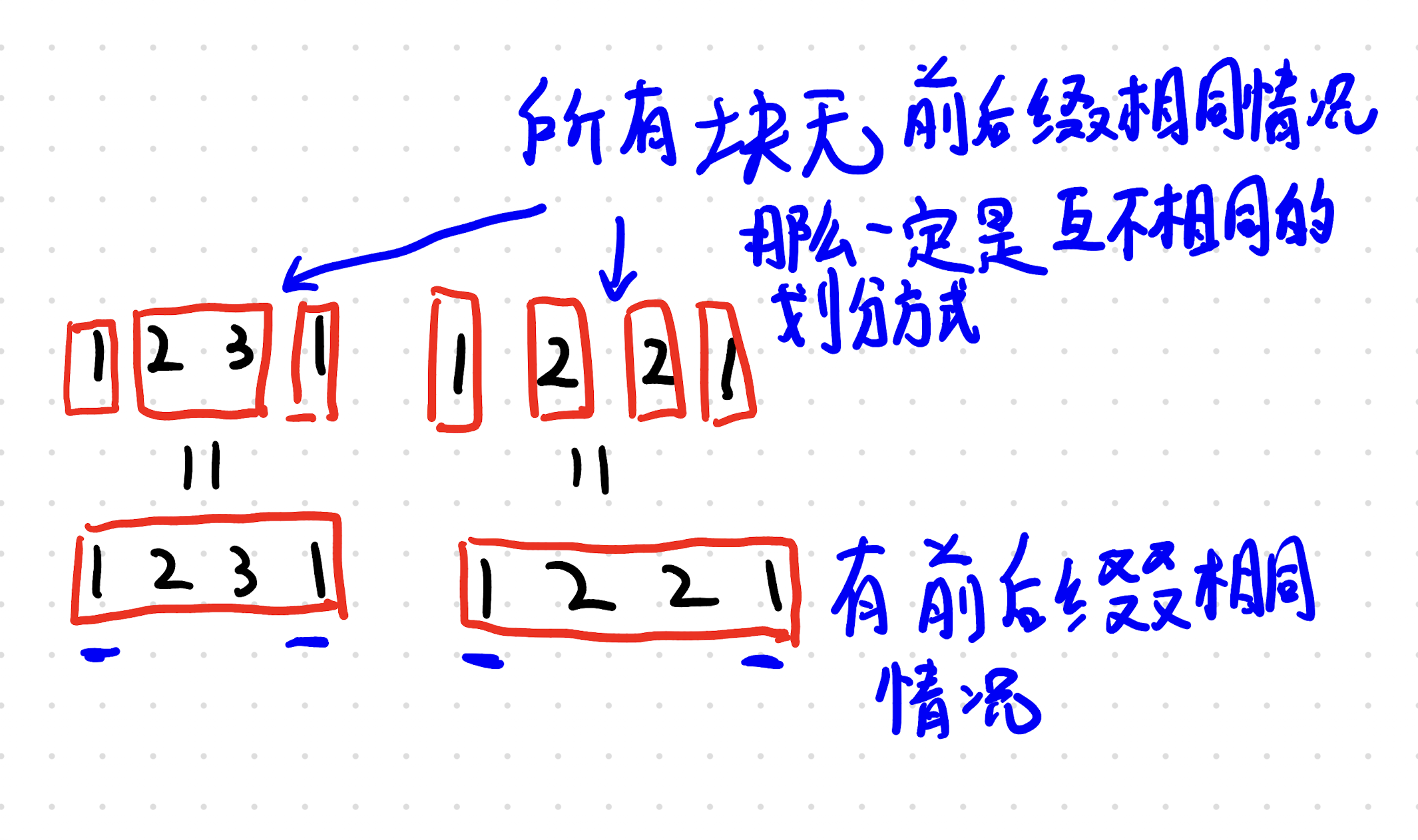
只要有前后缀相同情况,那么一定会有更加细粒度的切分方法,实现相同效果。
不过,如果只是需要无前后缀相同情况的话,那么直接判断一下前后缀第一个一不一样不就行了?事实上,我们要求,我们所选择的串,其所有子串(长度 ≥ 2)的前后缀都必须不同。